Find issues before your customers do
There’s nothing worse than when customers alert you to issues. Your observability tool should do that for you. Send any data to our data store, solve problems quickly with all the relevant context, and fix issues before they impact users.
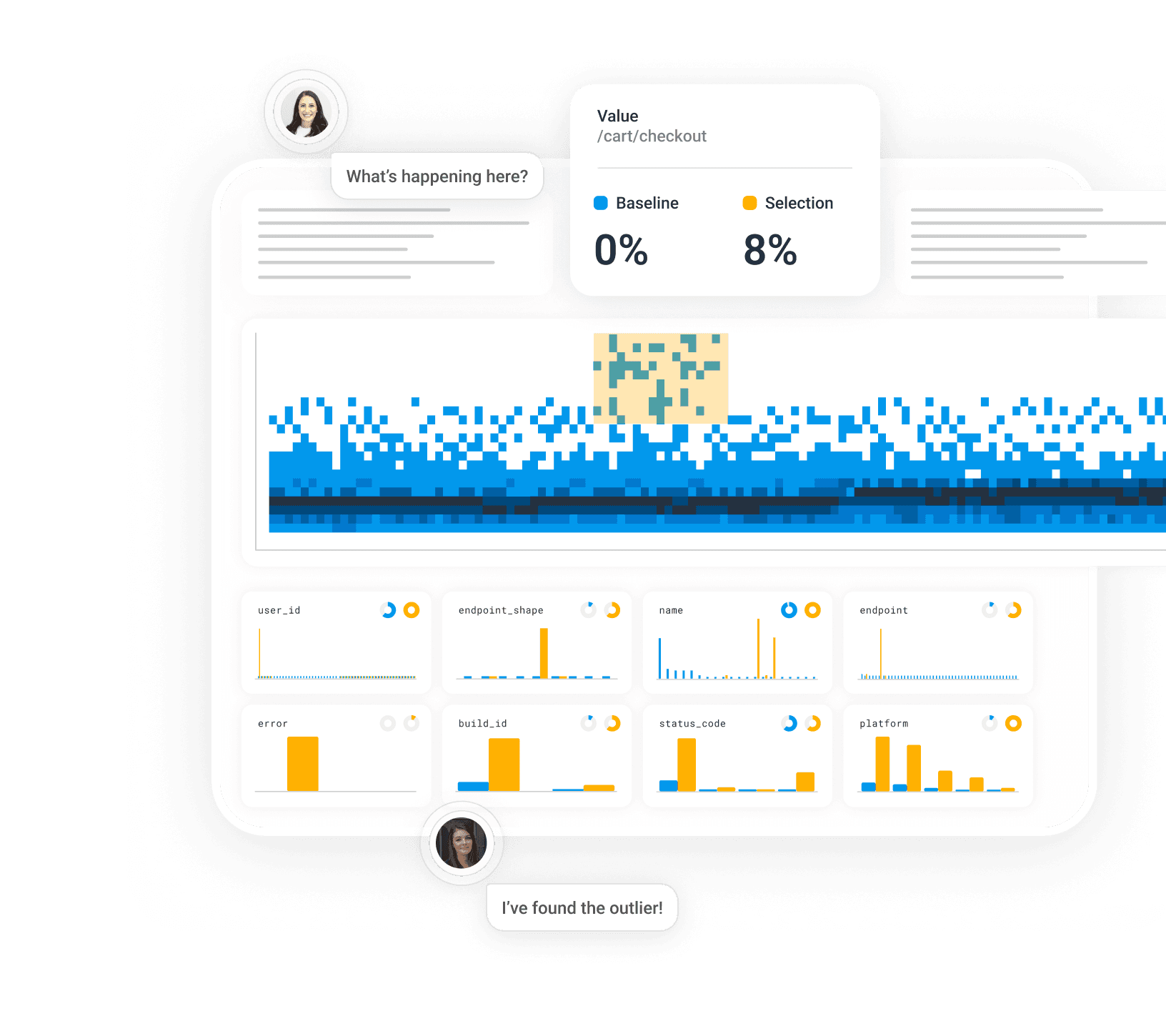
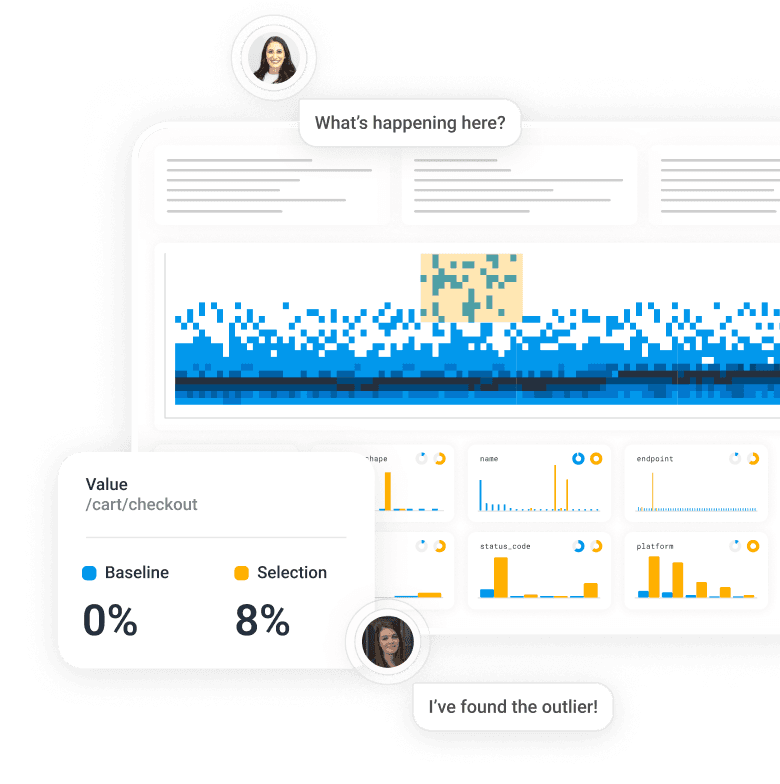
You're the last one to know when your system is down.
Engineering teams need to ship quickly and control operational and customer risk. Problems will happen but they cannot be allowed to affect users.
Knowledge silos
High dependency on a select few engineers who understand the full code base and architecture.
Needing to dig deeper
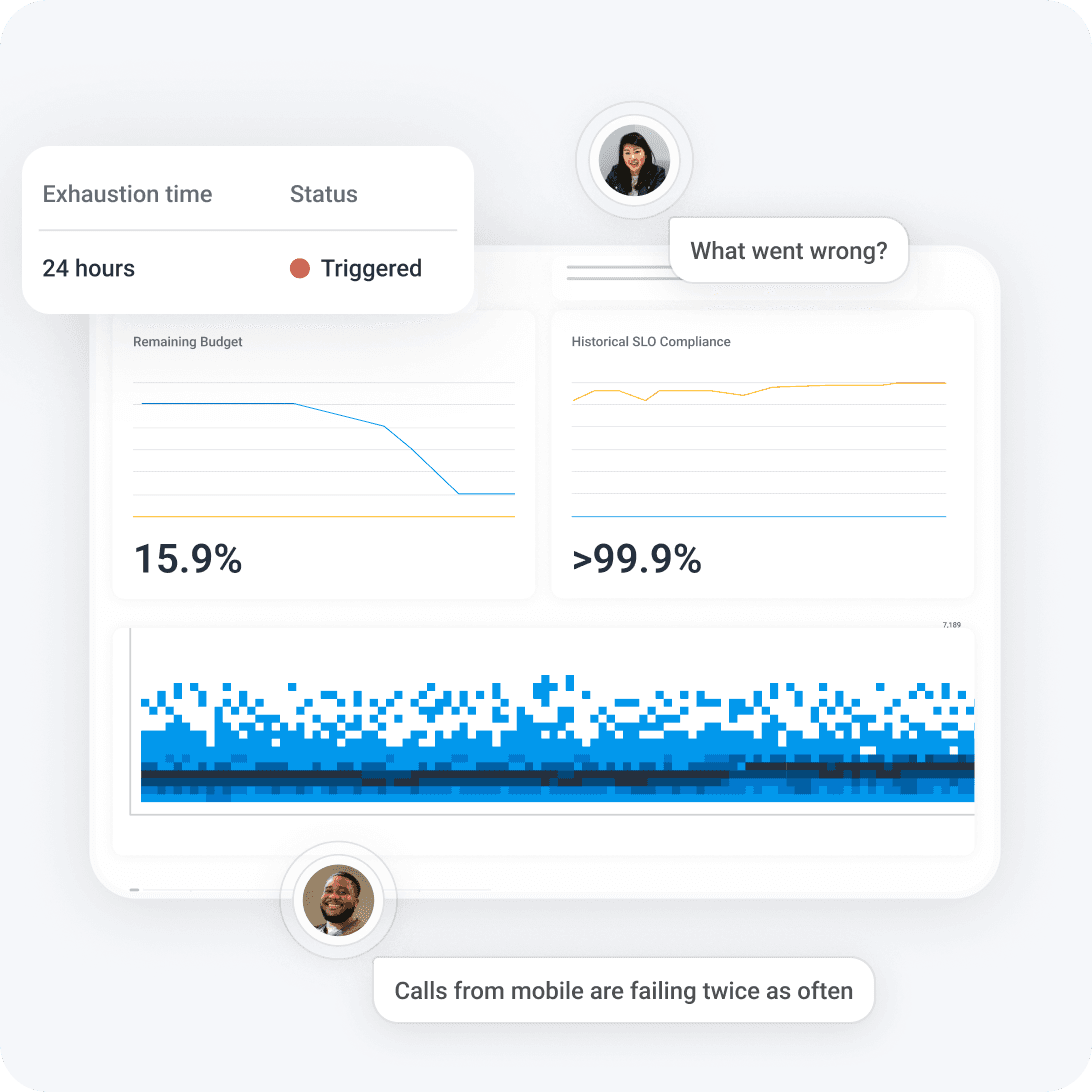
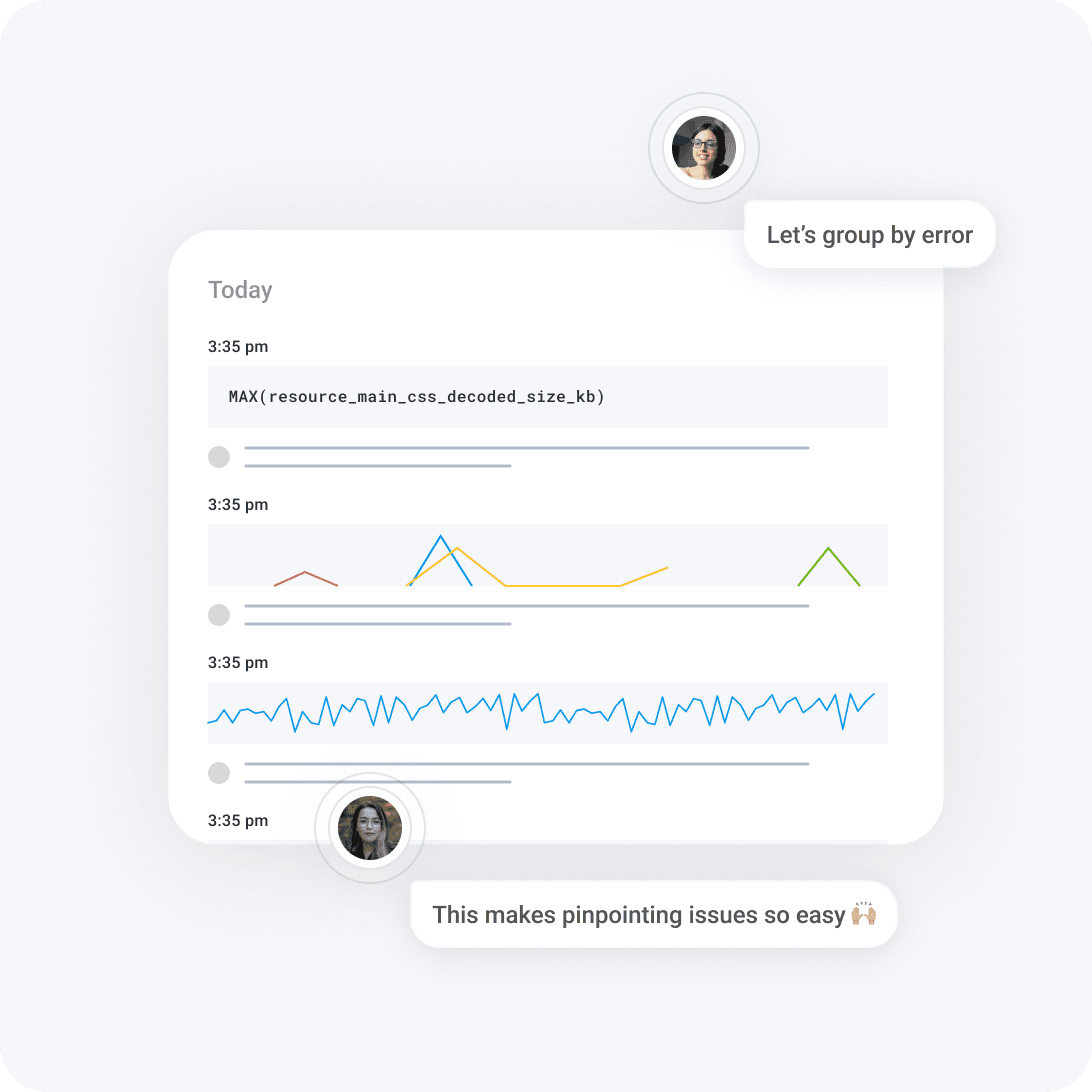
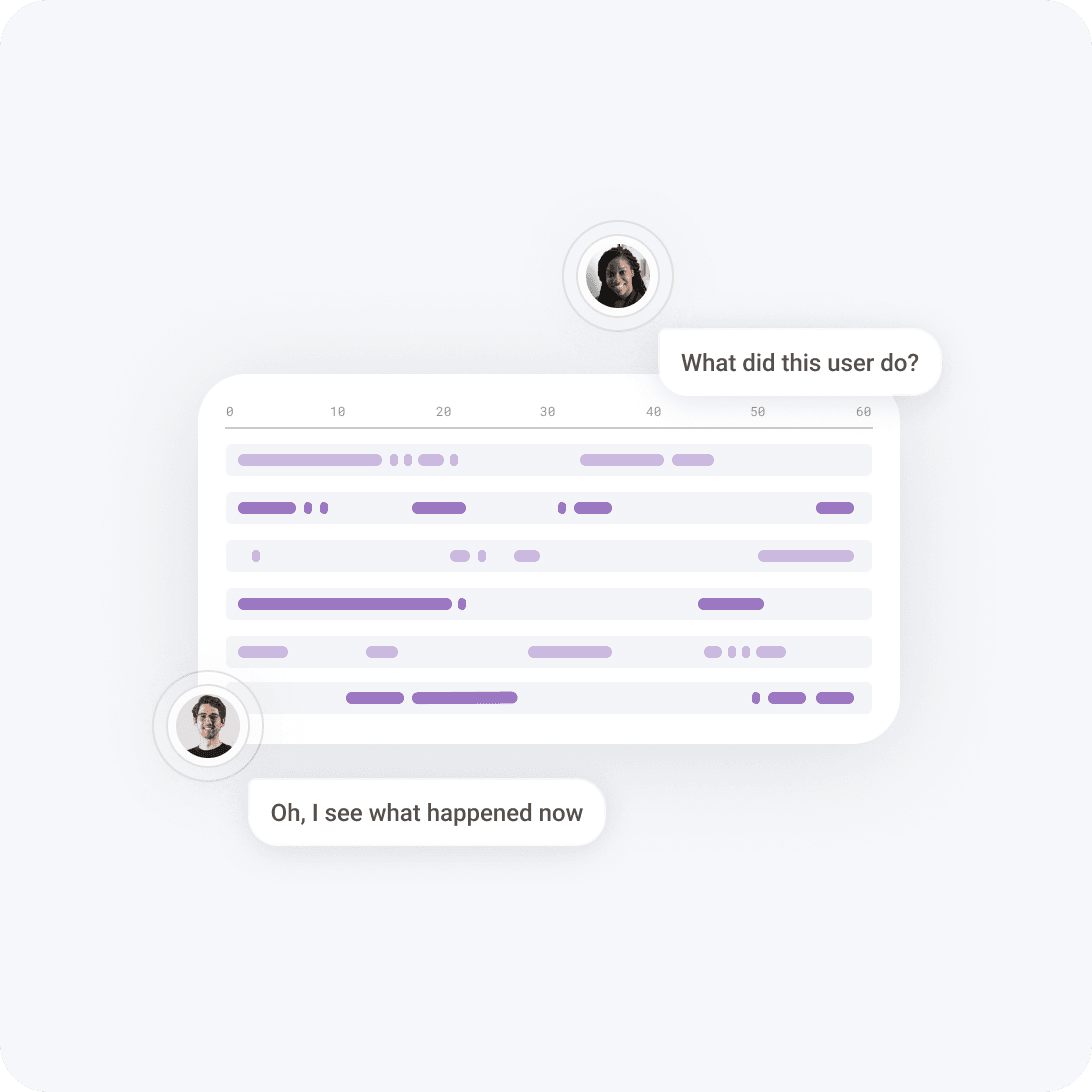
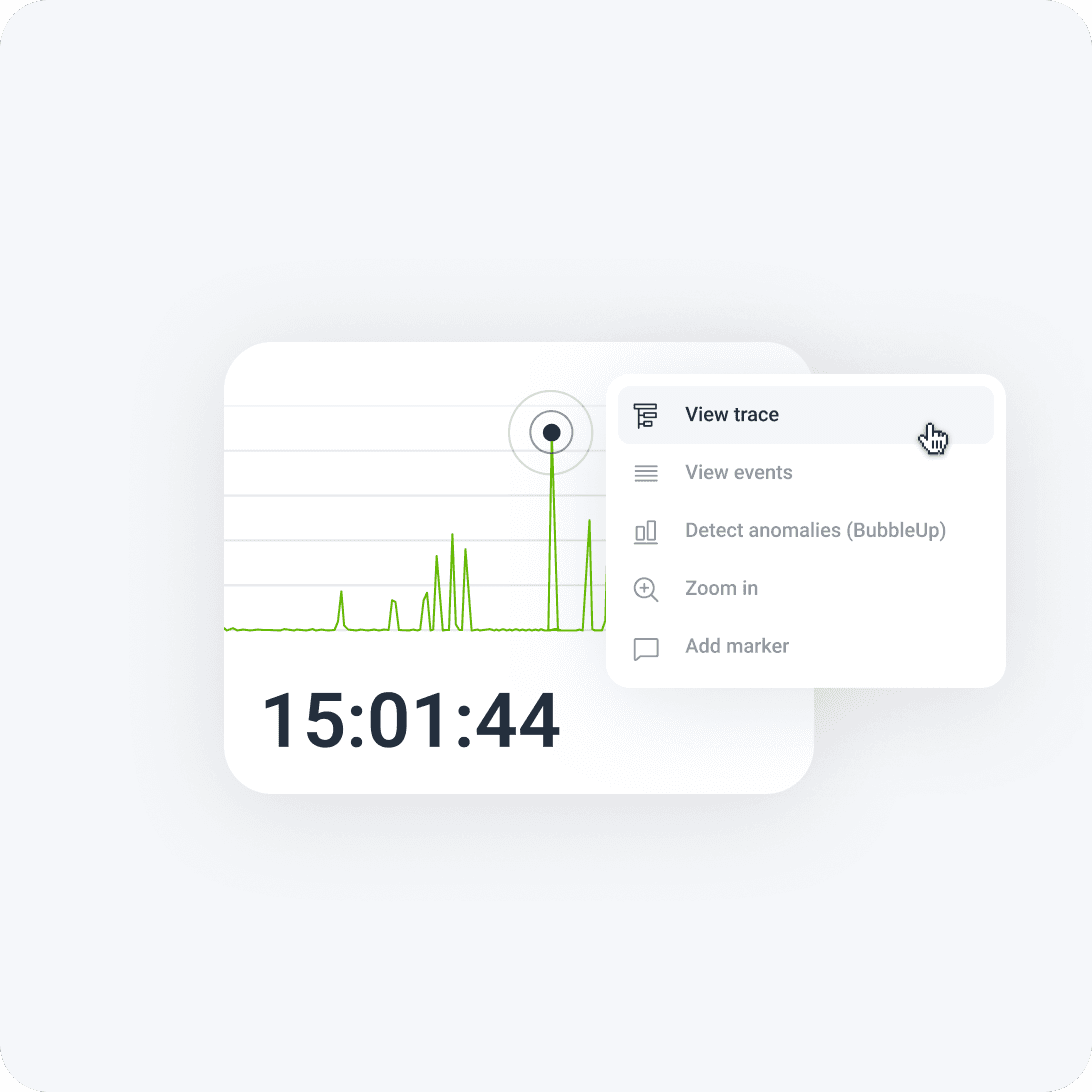
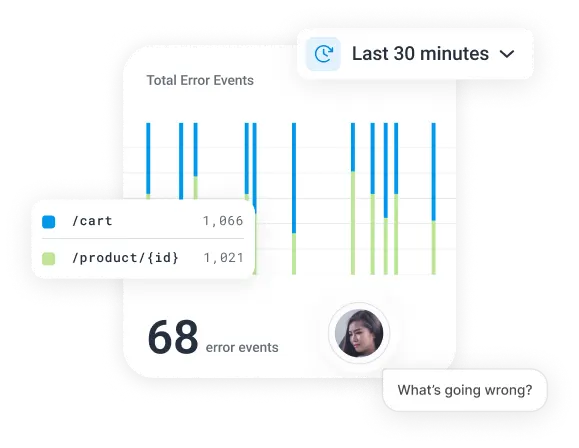
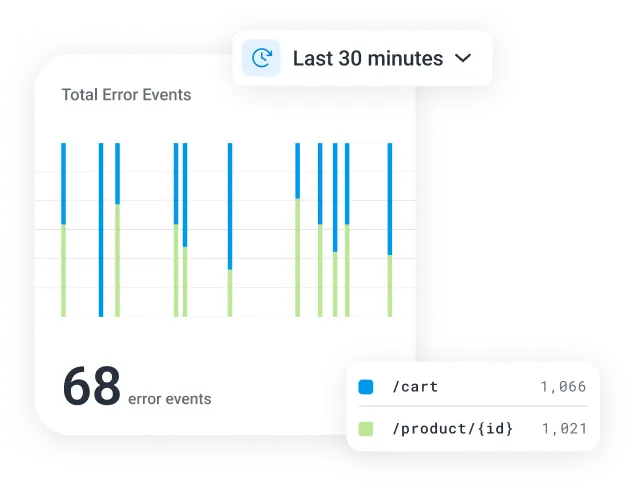
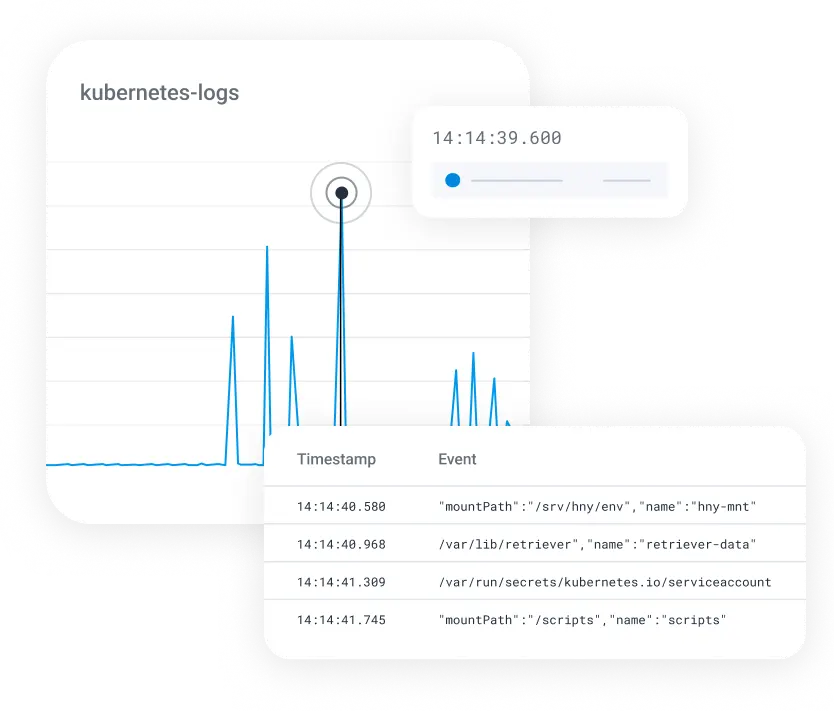
Engineers need to pinpoint a single misbehaving service amid an ever-expanding sea of distributed architectures.
Inconsistencies around “good”
Misalignment around “what good looks like” can lead to a disconnect on success metrics.
Alert fatigue
Engineers can be burned out, stressed, and reactive. Firefighting, not building.
Safety at speed
Honeycomb is the unified, fast, and collaborative observability platform for engineering teams who care about the customer experience to get the answers they need, quickly.
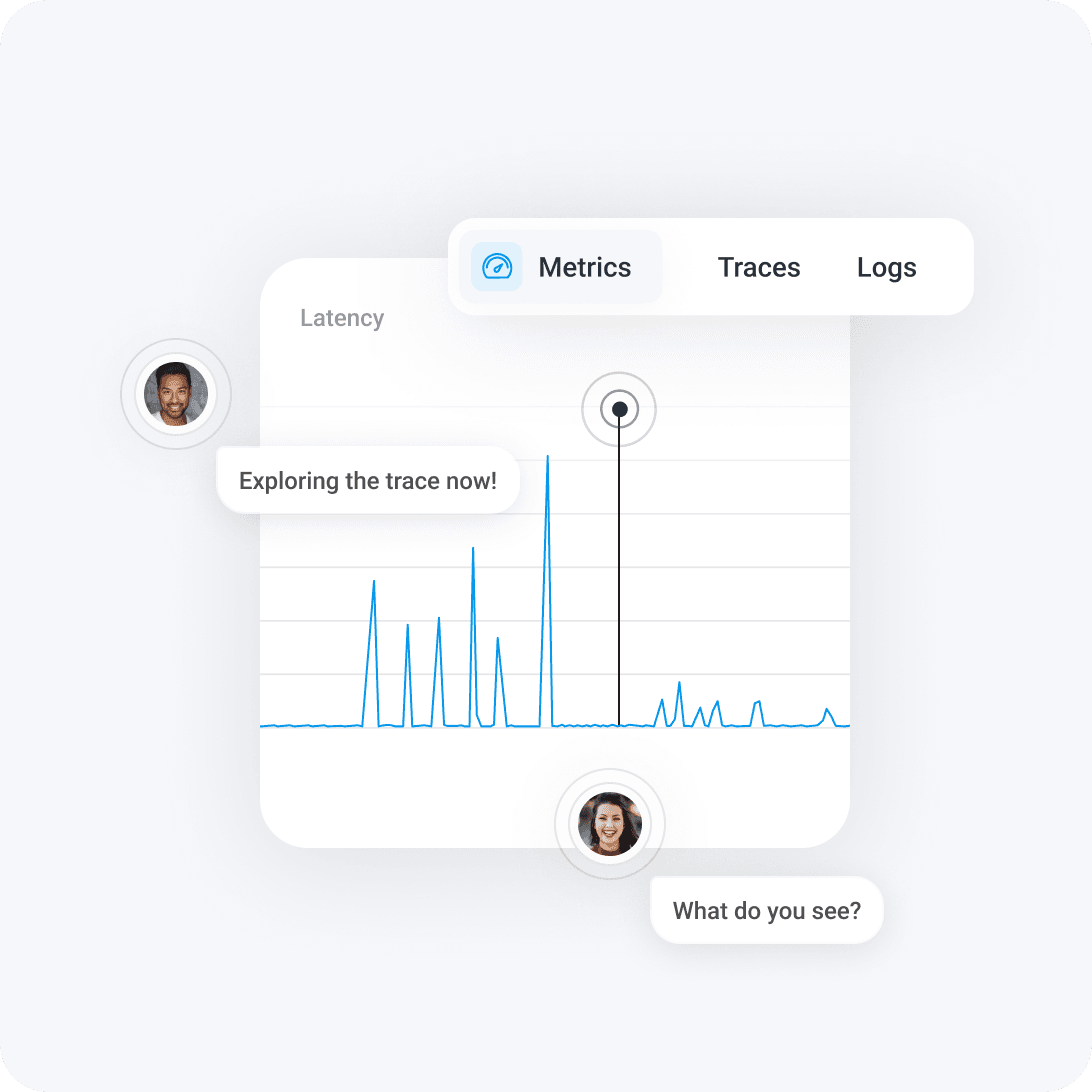
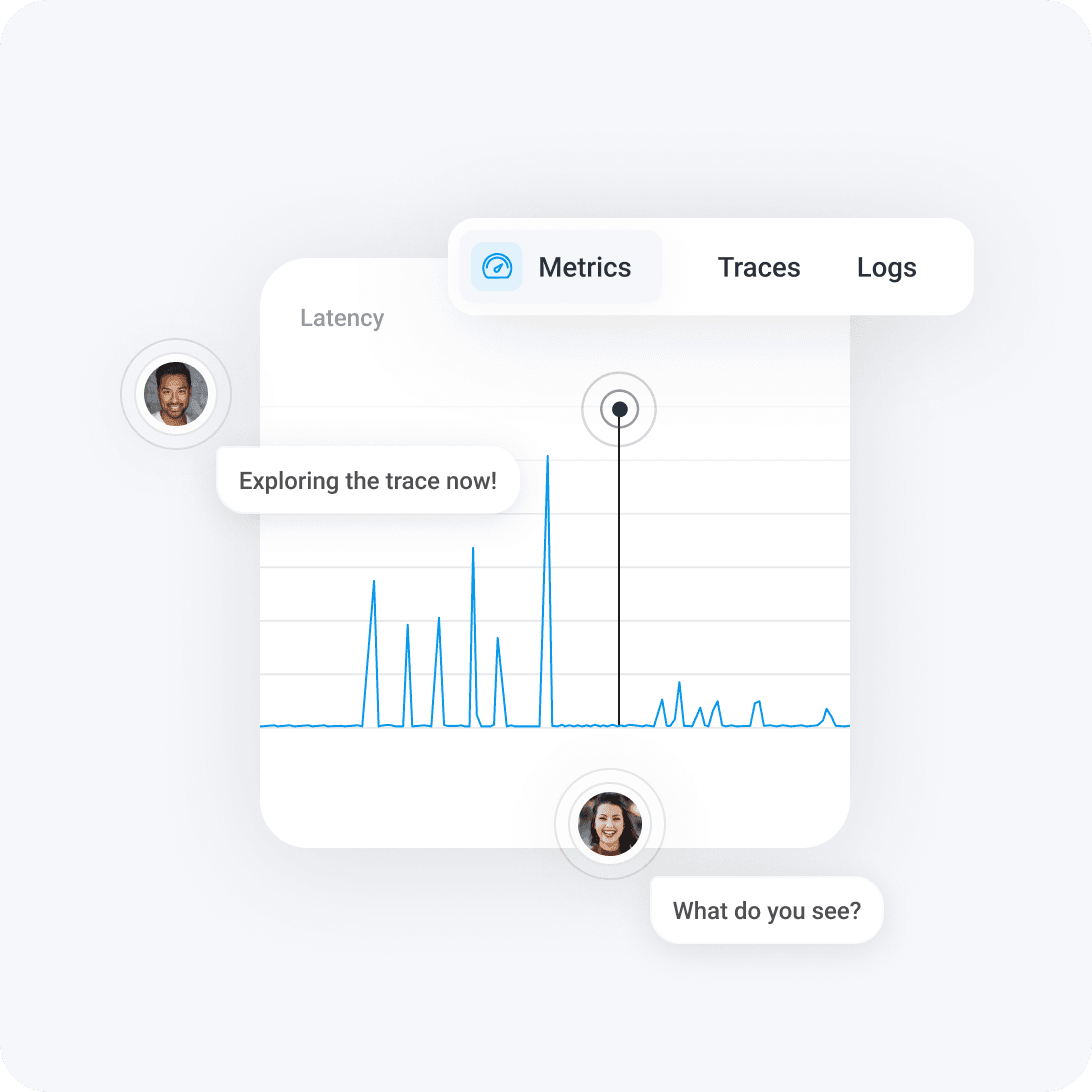
Trusted by innovators and enterprises worldwide








[At OneFootball], we’re not just delivering content; we’re delivering a real-time connection to something people are passionate about. That means we can’t afford delays or gaps in the experience, especially for our pay-per-view users during high-traffic moments.

Bruno Costa
Principal Site Reliability Engineer
Related features
Discover our full suite of features, giving you everything you need to easily solve problems.
Experience the power Honeycomb
Jump into our sandbox and start exploring—no signup required.




Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.