Alerts Are Fundamentally Messy
Good alerting hygiene consists of a few components: chasing down alert conditions, reflecting on incidents, and thinking of what makes a signal good or bad. The hope is that we can get our alerts to the stage where they will page us when they should, and they won’t when they shouldn’t. However, the reality of alerting in a socio-technical system must cater not only to the mess around the signal, but also to the longer term interpretation of alerts by people and automation acting on them. This post will expand on this messiness and why Honeycomb favors an iterative approach to setting our alerts.

By: Fred Hebert


The Five Characteristics of a Good SLO
Learn MoreGood alerting hygiene consists of a few components: chasing down alert conditions, reflecting on incidents, and thinking of what makes a signal good or bad. The hope is that we can get our alerts to the stage where they will page us when they should, and they won’t when they shouldn’t.
However, the reality of alerting in a socio-technical system must cater not only to the mess around the signal, but also to the longer term interpretation of alerts by people and automation acting on them. This post will expand on this messiness and why Honeycomb favors an iterative approach to setting our alerts.
Balancing signal and noise
Alerts are generally evaluated by their ability to hit a good signal and not miss on a bad one. When we think about how alerting is set up, there are a few broad categories of signals, including:
- saturation thresholds, such as CPU or memory usage, or connection counts (when there’s an upper bound, like on many databases)
- error rates, such as how many queries succeeded and how many failed
- performance indicators, such as throughput, latency, and others that are often aggregated with percentiles
- events that communicate normalcy, like traffic volumes, money (spent or incoming), and so on
These can quickly get sophisticated. In general, we can consider there are valid events (real events that tell us something succeeded or failed), and noise events (events that are wrong on that front).
In an ideal situation, there is no overlap between the valid events that trigger an alarm and the noise events that we don’t want to be notified about:
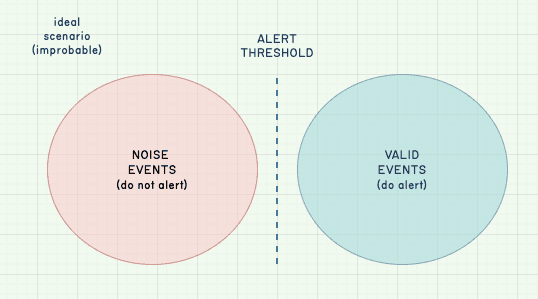
In these cases, the alert threshold is ideal and the alert is always relevant. Therefore, we fully trust our alerts.
In theory, we could accomplish this by being exceedingly specific about what we measure, and when there’s true clarity in terms of purpose, specification, implementation, control, and measurement. Without that, over-trusting alerts—or lack thereof—is misguided.
In practice, however, the event types overlap and are messy. For example, a normalcy indicator might flap because users are experiencing an outage using us less than usual, and there’s nothing we can do about it. Sometimes, users with bad network connections uploading files may have more failures, at a slower throughput than expected.
We have to expect that there’s going to be overlap where some values are expected and some are bad despite having similar numbers, mostly because the underlying factors explaining performance, saturation thresholds, error rates, or usual events are too rich to capture within single metrics.
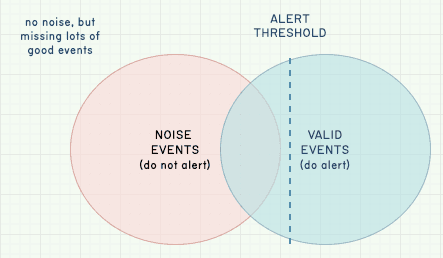
To deal with this, we can opt for a high alert threshold, meaning we only get paged when usage is definitely wrong. This means that we’ll lose signal sensitivity and may miss valid situations where we’d want to get paged but won’t:
On the other end of the spectrum, we may decide to instead pick an alert threshold that is overly sensitive, where we want to capture all worthy events:
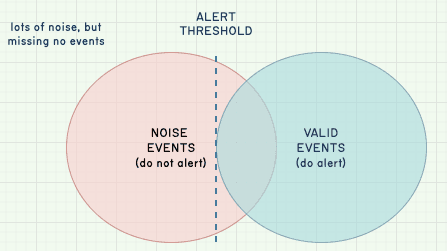
The tradeoff here is that we may end up in a situation with a lot of noise. This is undesirable because the alert often tells you nothing of use and requires active filtering.
Finally, it is very much possible—likely, even—that there is a lot of overlap between event types. This means that no matter what we do, our alert thresholds are likely to lie somewhere in a large mess of signal and noise, where we’ll definitely miss some worthy events and alert on useless ones.
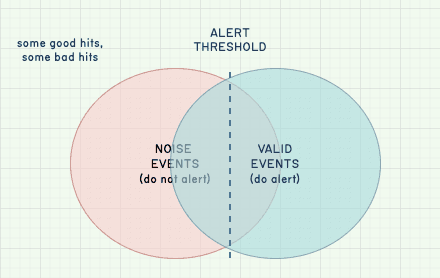
This is unavoidable. An alert’s efficacy cannot be disjointed from its context. To attempt to solve this, we can try to break down our observability data into sub-groups and distinct categories to make the overlapping portion of the Venn diagram smaller. For example: some endpoints are allowed to be faster than others, some users are allowed to have different failure types than others, some times of the day or the month are expected to have distinct error rates from others, and so on.
But sooner or later, we’ll have to face the music: there are a lot of things that can happen and inform us, and keeping track of it all is hard.
More than that, it’s allowed to change over time. It’s possible that one of your users creates and runs a lot of queries successfully. Let’s say you fix your pricing and give them a dedicated batch API endpoint that’s a lot cheaper. The overall makeup of the events you aggregate in your query statistics would change, right? Despite having as many failures as before, they could now make up 0.05% of your total volume instead of 0.01%. In that case, you’d find yourself blowing your 99.95% SLO despite service being overall better and cheaper.
This sort of change happens all the time. If you carefully calibrate your alerts, small changes in how people use your system can have large impacts in how noisy your alerts are. This mess is mostly unavoidable without having an extremely tight control into everything your system interacts with—and who interacts with it.
An iterative approach to alerts
A particularly tricky aspect of the messy and changing nature of signals is that people are generally on the receiving end of them, and people can get tired, fed up, or busy. This means that if we want the alert to result in a given action, humans receiving the alert have to be part of the evaluation of how noisy those alerts are.
So while this is the standard way we like to think about alerts:
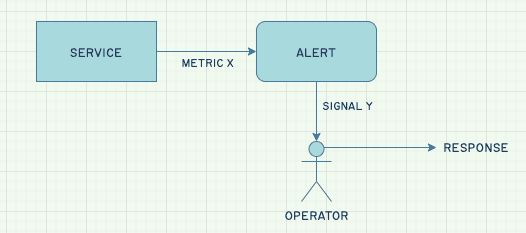
The actual layout is more like this:
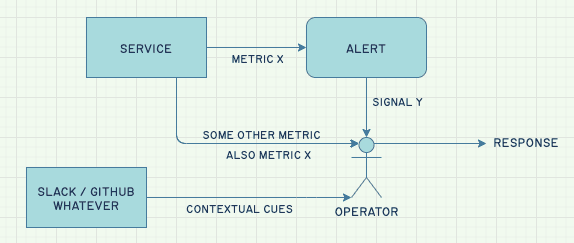
As such, an alert that creates fatigue can lower overall signal by being ignored. The alert itself becomes a filter that people use as information to interpret signals. By looking at the various signals, the alert just becomes another piece of information that influences how signals are understood and processed.
Unhelpful alerts train the operator to ignore or lower the importance of some signals, and therefore the overall balance of an overly sensitive alarm is that you may lose more signal than if you had a less sensitive one.
If we find ourselves in a situation where we make our alerts very sensitive, we have to be sure we’re okay having people investigate mostly unimportant stuff just in case some important stuff is in there too. But if we do that with too many alarms and our operators and engineers are busy, they will ignore the alerts that they trust less and keep their attention to those they trust more.
In fact, what is suggested in literature is to consider the alarm as a way for the system to demand your attention and redirect it. When we frame this in terms of people, we’re able to look at what the other person is doing and choose a level of loudness that is in line with their ongoing demands: if they’re doing something important, we won’t distract them for something that is less important. If what we have as a signal is very sure and very loud, then hell yes we’re going to distract them and demand their attention.
The most practical way we have found of doing this is to simply take the time to think about what we get out of our alerts. If they’re often false alarms, we want to know for sure the false positives are worth the few true positives.
If they’re often real alarms but aren’t actionable, we may want to change the type of signal we get from them: move them away from on-call and toward low-disruption signals up in the decision chain—where people prioritize the work to be done so reliability can be tackled with project work.
If they’re rare, then the ability to know what signals mean can drift over time, because people garbage-collect the information they don’t need much. Also, it’s possible that the statistical makeup changed once again and irrelevant successes hide very real failures. So from time to time, conducting chaos experiments or an analysis of your signals (or lack thereof) can be a profound exercise.
Manage the noise
My overall tip, then, would be to consider your alerts to be an attention-shaping tool that requires frequent recalibration. The data should be thought of as messy, and rarely trustworthy.
Try SLOs in Honeycomb for free
Get started now and reduce alert fatigue.
One of my favorite activities is to check from time to time whether customer success hears of issues we don’t get alerted by from our SLOs, or whether we find them at the same time—or before—customers report them. Things we find and hear nothing about means we may be sensitive enough (or maybe over-sensitive); things we find and hear about means we’re seeing their pain (and maybe not seeing it early enough); things we don’t find but customers do are a sign we may have under-sensitive signals.
The key takeaway is that we want the signal of an alarm to mean something, to help us adjust our response and behavior. If it isn’t doing that, it needs tweaking. Most other concerns, even if they have to do with “knowing how we do year over year,” are less important than that primary response concern.
People are encouraged to discuss and modify alerts as they see fit, both in terms of adding them and in terms of removing them. An alert we learn to ignore doesn’t serve our purposes anymore. It needs fixing.
Enjoying learning more about alerting? Read this blog on alerting on the user experience.
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.