The Present and Future of Arm and AWS Graviton at Honeycomb
As many of you may have read, Amazon has released C7g instances powered by the highly anticipated AWS Graviton3 Processors. As we shared at re:Invent 2021, we had the chance to take a little…

By: Ian Smith

As many of you may have read, Amazon has released C7g instances powered by the highly anticipated AWS Graviton3 Processors. As we shared at re:Invent 2021, we had the chance to take a little sneak peek under the Graviton3 hood to find out what even more performance will mean for Honeycomb and our customers. The timing of C7g becoming generally available couldn’t be better as just last month we tweeted our excitement about the achievement of migrating 100 percent of our Amazon EC2 fleet to Arm64-based AWS Graviton family instances. Based on the success we had with this experiment (don’t worry, we discuss it below) we can only expect great things to come out of the new AWS Graviton3 Processors.
Now, you might be thinking to yourself, “perfect timing? But didn’t you JUST finish your migration to Graviton2?” And our answer to that is we couldn’t be more thrilled to take this on (and, it’s seamless now that we’ve invested in Arm compatibility). If we’ve learned one thing from our migration to Graviton2, it’s that improving the performance of big-data, high-performance computing only gives our customers more speed and options for analyzing data at scale. Based on what we’ve seen so far with Graviton3, there are massive improvements coming your way. And, of course, all our AWS integrations work flawlessly on Graviton3 which means we’re as ready as ever to continue supporting customers as a Graviton Ready Partner.
Background
Amazon announced the Graviton2 processor in December 2019, and we wrote about our first experiments with Arm processors in March 2020. It was quickly apparent that this was going to be a win for our workloads – running a head-to-head comparison of the (x86_64/Intel) C5 instances against the then-new (arm64/Graviton) M6g family showed us clear wins on several axes – lower cost, more RAM, lower median and tail latency – and when M6g became available in production quantities in May 2020, we made that switch.
We’re a Golang shop, so compiling for Arm was easy to do; and we used Terraform and Chef to manage our infra, so switching from x86 to Arm Amazon Machine Images (AMIs) was likewise streamlined as we could enumerate all the dependencies to update. While the initial Graviton processor was offered in only a single instance family (A1), AWS came to offer Graviton2 in every configuration we’ve come to expect: spot instances for interruptible workloads, different ratios of compute and RAM (C6g/M6g/R6g), NVMe storage attached (for instance, M6gd), and managed services like RDS and ElastiCache.
This diversity of ecosystem support meant we were able to migrate almost all of our services. As we said in our One Year of Graviton2 at Honeycomb retrospective in 2021, “we certainly weren’t going to stop with just one workload after investing in the capability to run any of our workloads on Graviton2”.The work done by software we ourselves develop was both the easiest to move – because we control the build, and so could re-compile for the Arm architecture – and the highest-impact, as it makes up the bulk of our compute spend.
But there’s always that long-tail in any migration, and this was no different. We’ve previously shared our experience moving Kafka over to Arm instances once AWS offered Graviton2 instance types with on-instance storage (Is4gen and Im4gn), and the wins we saw there (with help from Amazon). So what was left fell into 3 categories: the ad-hoc (a handful of SSH bastion hosts and a development box used by one of our product teams); the single-instance service (a SQL web UI) and the more toilsome-to-migrate (Zookeeper was one of these).
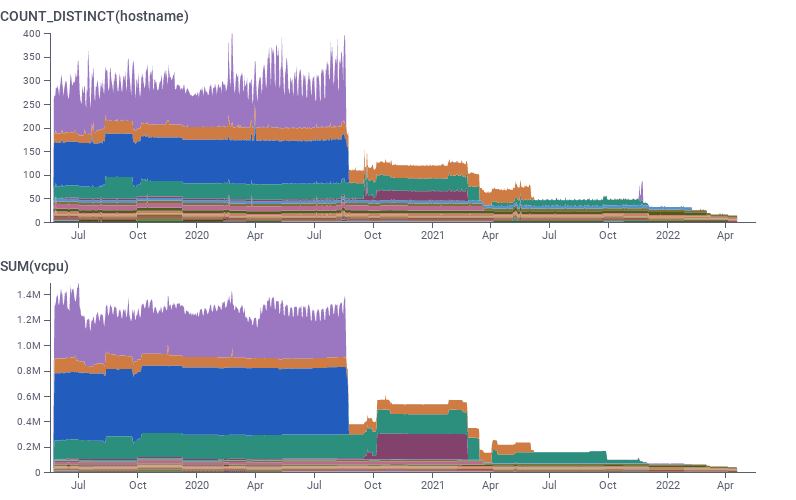
What these all had in common is that they all required some manual effort to migrate over and test, but none used enough instances or compute resources to feel worth the effort. At one point, I had a shell one-liner tracking what we had deployed that wasn’t running on Arm:
aws ec2 describe-instances | jq '.Reservations[]|.Instances[]' | jq -cs '.[] | {arch:.Architecture, type:.InstanceType, tags: (.Tags//[])|from_entries|{name: .Name, env: .Environment}}' | jq -c 'select(.arch != "arm64")'We were at 18 non-arm64 EC2 instances out of a fleet of perhaps 350 – about 5% by instance count, and biased towards smaller (and cheaper) instance types.
Evaluating the cost of complexity
But at some point, you have to ask the questions opposite of those which started our journey with Graviton2. In the early days, it was – can we, easily and simply, support both architectures? Can we move our workload over safely, knowing we can always go back if we don’t see meaningful gains in performance and cost? The answer was yes, which allowed us to proceed incrementally.
Two years later, we asked the opposite question. Is there a chance we might ever want to switch back to x86 in the medium-term? Although 6th generation Intel and AMD instances launched at re:Invent in December 2021 do close the gap with Graviton2 for some workloads, those processors primarily enhanced SIMD/vector performance rather than catering specifically to our general-purpose workload which makes only limited use of SIMD instructions.
And we had been able to preview Graviton3 instances, which offered massive performance improvements for our workload even over Graviton2 (and which leave 5th generation and even 6th generation Intel instances in the dust). This gave us the understanding that AWS and Arm would continue to invest in radical improvements to the architecture and its real-world performance. So, with the announcement of general availability of C7g Graviton3-powered instances today, we’d like to share our observations since we gained preview access in November.
Experiencing the future
We performed initial testing of Graviton3 in our dogfood environment to substantiate our quote about 30% performance improvement from Graviton2 to Graviton3 at re:Invent in December. We squished selected AWS Auto-Scaling Groups (ASGs) down to the minimum possible size for each of C6g and C7g processors while maintaining similar latency and throughput targets. We did not need to rebuild any software this time (unlike the original migration from Intel to Arm instances), because both Graviton2 and Graviton3 processors are compliant with the ARMv8.2+ instruction set.
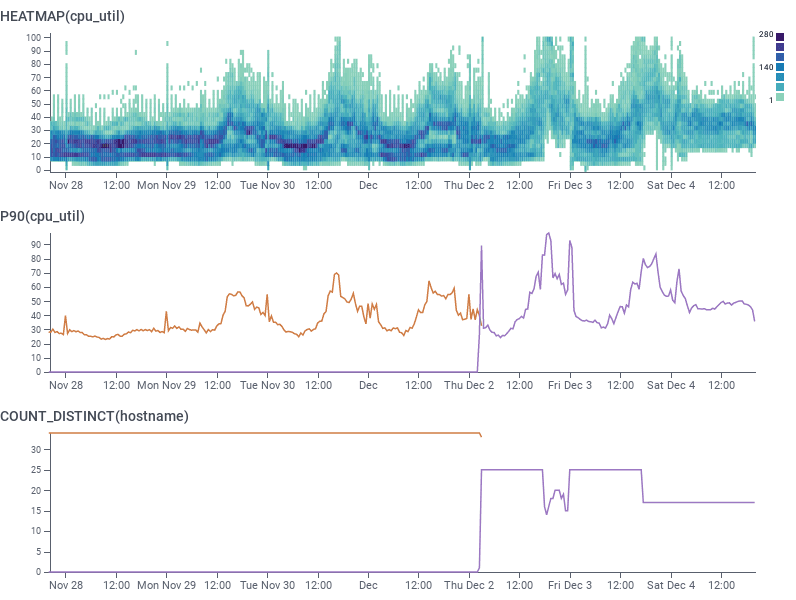
We believe that in benchmarking whole VMs, it is important to test to the breaking point, rather than assuming the same CPU utilization should be used across the board and that latency always will degrade at the same target CPU percentage. Through those tests, we were able to establish that shepherd ingest and beagle streaming data processing were able to operate at similar latency and throughput with 10% higher CPU target utilization set on the ASG (leading to 30% fewer instances being provisioned).
Since then, however, we have migrated almost all workloads at Honeycomb to Kubernetes. For our final performance and quality testing, we configured our ASG to create a handful of Kubernetes nodes using the latest EKS node AMI on c7g.2xlarge, c7g.4xlarge, and c7g.8xlarge instances, attached them to our production cluster, and allowed our existing Arm compatible deployments and pods to randomly schedule across them (truly seamless, no container changes needed!). We always had the option to revert the experiment by refreshing the ASG managing Kubernetes nodes, ensuring safety. And given this was a production experiment (always test and observe in production, even if you’ve also tested in staging!), we did not test to destruction (nor did Kubernetes require us to, since we could now saturate machines with scheduling more pods instead of scaling VM counts down).
The AWS Application Load Balancer (ALB) then naturally sent a sample of our production workload to the pods scheduled on C7g family instances, allowing us to test and validate with a more realistic workload than we used for the earlier November dogfood tests.
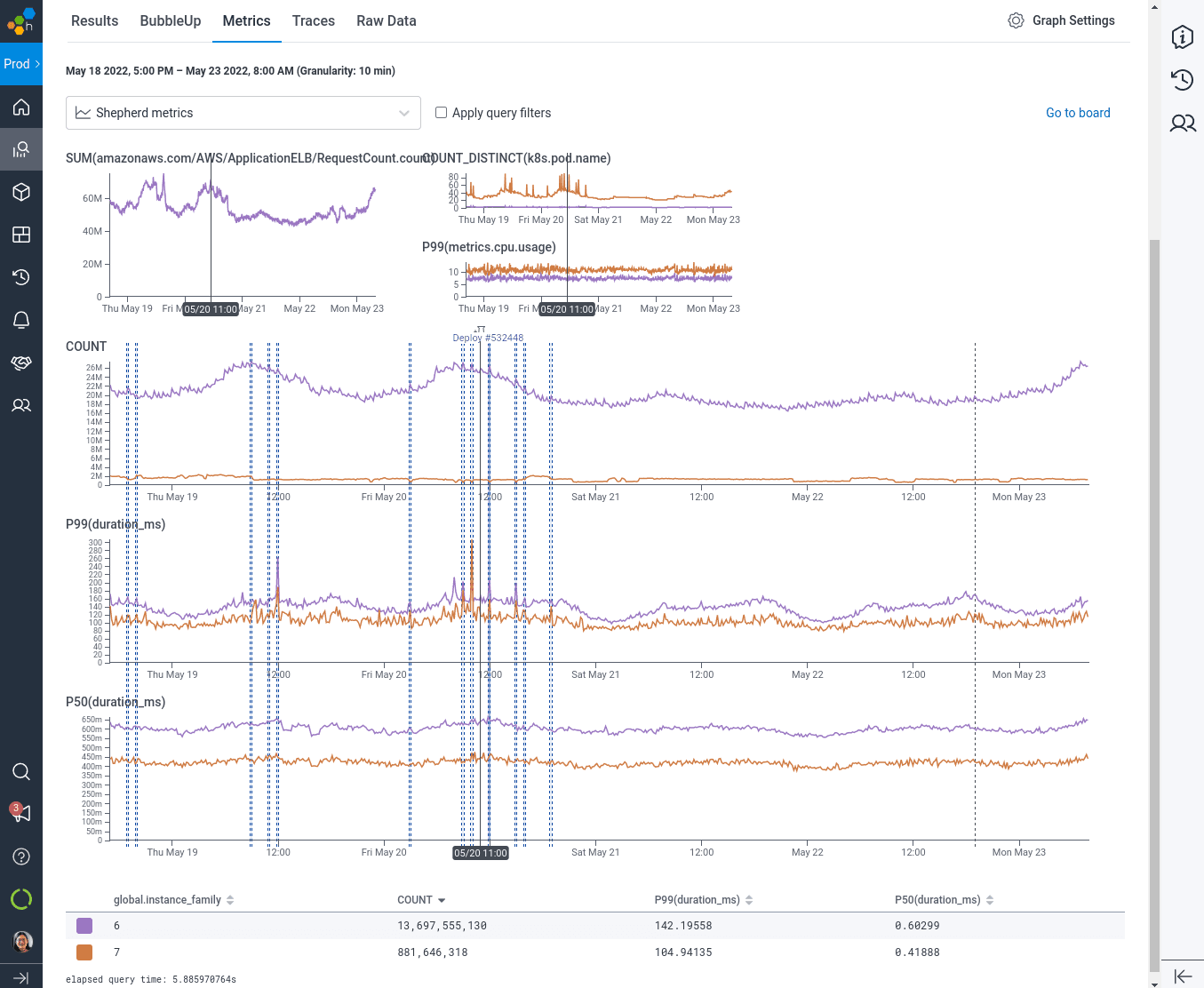
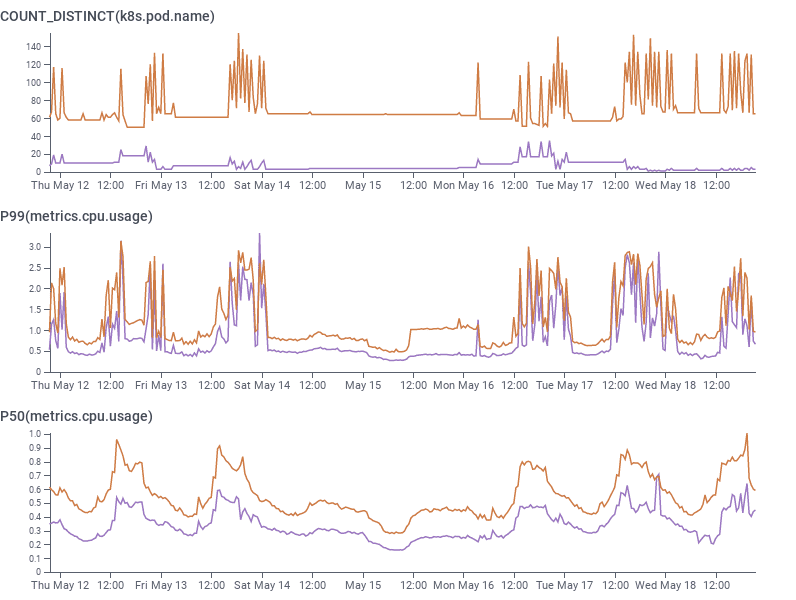
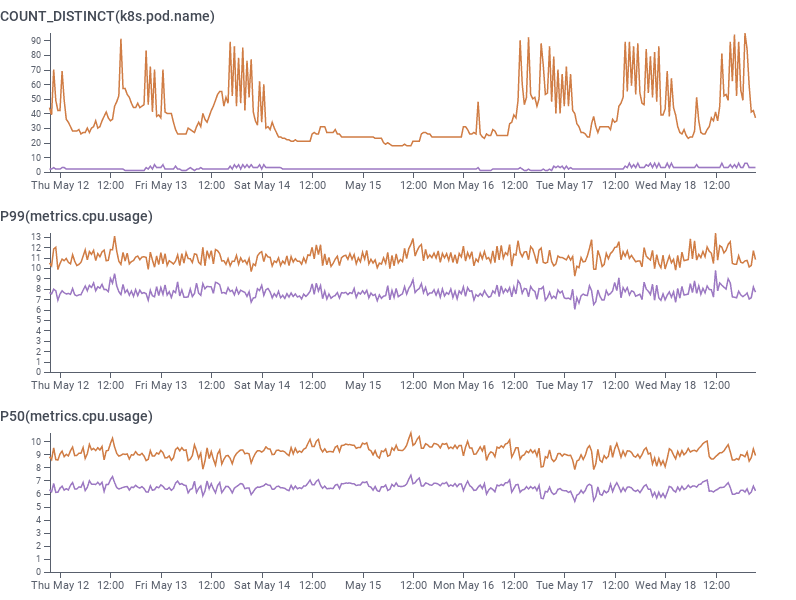
After seeing the benefits of Graviton3 in our infrastructure, it was clear that it would be uneconomical to go back to using x86 processors any time soon. We started asking what it cost us in complexity to have that flexibility we wouldn’t be using? The technical complexity (perhaps, even, technical debt if it might silently break from not being regularly used) adds up: compiling for both architectures, Terraform and Chef conditionals to support both sets of instance types, and, as of our migration to EKS – running k8s worker groups for both x86 and Arm and managing taints. Our answer was, well, it’s not a lot … but it’s not nothing, and each of these caveats caused at least one follow up PR of the “oh right, we have to do both of these” variety. As with any big migration, there comes a time to tie it all up in a bow and say “woohoo, we’re done now!”
Finishing the migration
By combining data from Honeycomb’s Kubernetes agent sending along pod metrics tagged with instance type, and Honeycomb’s own telemetry sending traces containing application latency and performance tagged by instance type (along with all of the other rich, high-cardinality data we already use), we were able to confirm the results from the November trial. Median CPU utilization when serving round-robin decreased by 30% per-worker, allowing Kubernetes to schedule more pods onto the same size of node. Processing latencies at p99 also decreased from 150ms to 110ms (27%).
So we took the Metabase web UI for our internal BI SQL database, which did not have an upstream docker image available for Arm, and repackaged it ourselves. We spent a day or two reassuring ourselves that we could safely roll our Java-based Zookeeper cluster onto new (Arm!) instances with no disruption. We spent a bit of time eliminating a closed-source telemetry proxy that was no longer strictly necessary. And we coordinated with users of the aforementioned bastions and dev box to be sure all those tools could move … and we did it.
As of April 2022, we are all-in on Graviton family processors in EC2 land; we do not have a single x86 EC2 instance running in our production accounts. (And we get to turn off some builders in CI – no need to build x86 binaries that we’ll never deploy.). And we’re looking forward to formally introducing the now generally available Graviton3 processors into our fleet alongside the existing Graviton2 processors.
Lambda
You might notice the “in EC2 land” qualifier. We’re also very heavy users of AWS Lambda for our storage engine. Accessing the older data (up to 60 days of retention) that we’ve tiered to S3 is embarrassingly parallel, so we keep queries fast (under ten seconds) by fanning out onto tens of thousands of Lambda workers. Because we had been using Arm binaries for everything else, when AWS launched Lambda functions on Graviton in August of 2021, we were ready to go. We deploy identical (in source code) copies of our retriever-segment function compiled for x86 and arm64, use our Lambda layer to export trace spans from the function, and use a feature flag to control the percentage of Lambda invocations that go to each architecture’s function.
Early experiments with Lambda runtimes on Graviton were promising given the 20% decrease in cost per millisecond, but performance wasn’t quite where it needed to be. However, we always expected to need some tweaking and experimentation for the workload to run successfully. By running production loads at 1%-10% of traffic with Honeycomb’s own trace analytics (we love dogfooding!) and pprof CPU profiling enabled, we identified that some of our critical path code needed optimization (in particular, in the lz4 library – thanks to @greatroar for the arm32 patch, which we then ported to arm64). Finally, after the recent Golang register calling conventions on x86_64/amd64 in go 1.17 finally also arrived on arm64 in go 1.18, we had the confidence to move forward knowing performance would be at par and more affordable.
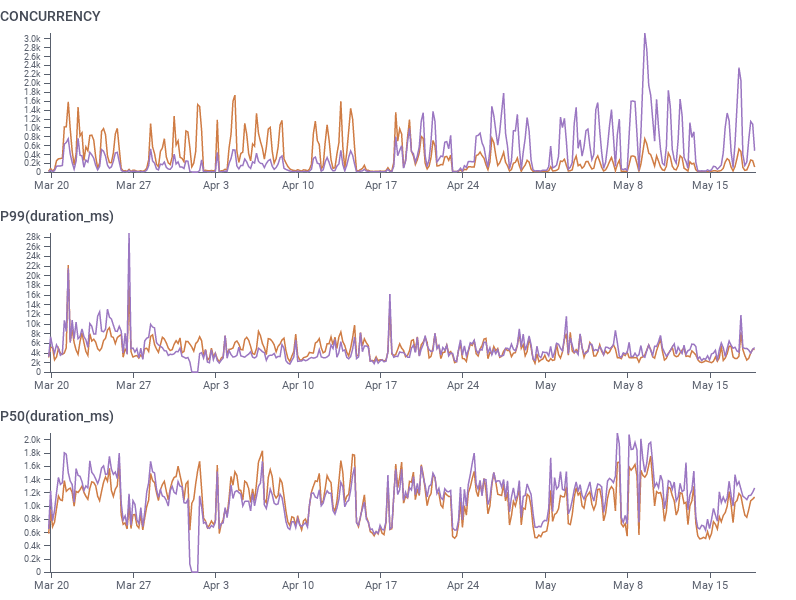
We gradually bumped up the percentage of Lambda invocations running on Arm and are currently at 99% Arm. We expect to keep some portion of our Lambda traffic running on x86 for the foreseeable future, not least so that we can make use of all available capacity as our traffic and workload grow, but it’s safe to say we’re overall all-in on Arm!
Today, new developers at Honeycomb use Arm-compatible M1 Macs (which also have incredible performance and energy efficiency!) to write code and deploy to Graviton2 (and now Graviton3) powered compute in production, and Honeycomb customers benefit from faster query executions thanks to their queries running almost exclusively on Arm processors.
Our fun with Arm and Graviton is far from over
Graviton has enabled Honeycomb to scale up our product without increased operational toil, spend less on compute, and have a smaller environmental footprint. Our Total Cost of Ownership (TCO) is among the lowest in the observability space. When our sales team works with large enterprises on build vs buy analysis, we find that our estimated infrastructure cost can come in >50% less than their ELK-based infrastructure cost they share with us. This doesn’t even include the cost of replicating our real-time querying and cutting edge visualization technology. It is thanks to AWS innovating in what they can offer us that we can focus on our core business of providing cutting edge observability tooling to our customers.
It is bittersweet to finally bid goodbye to the Intel instances that we’d been using since Honeycomb was launched in 2016. But we’ve enjoyed our journey over the past two years with the Arm and Graviton families, and we hope sharing the lessons we’ve learned has inspired our customers and the AWS community at large. Hopefully, you’re feeling as excited as we are about the next two years as we harness the potential power of Graviton3 to deliver you better, faster insights about production.
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.