Debug LLM applications with confidence
Generative AI is powerful but unpredictable. With Honeycomb, you get granular insight into how your LLMs behave in production, troubleshoot failures faster, and continuously improve model performance—all in real time with real data.
Get a demo Take a product tour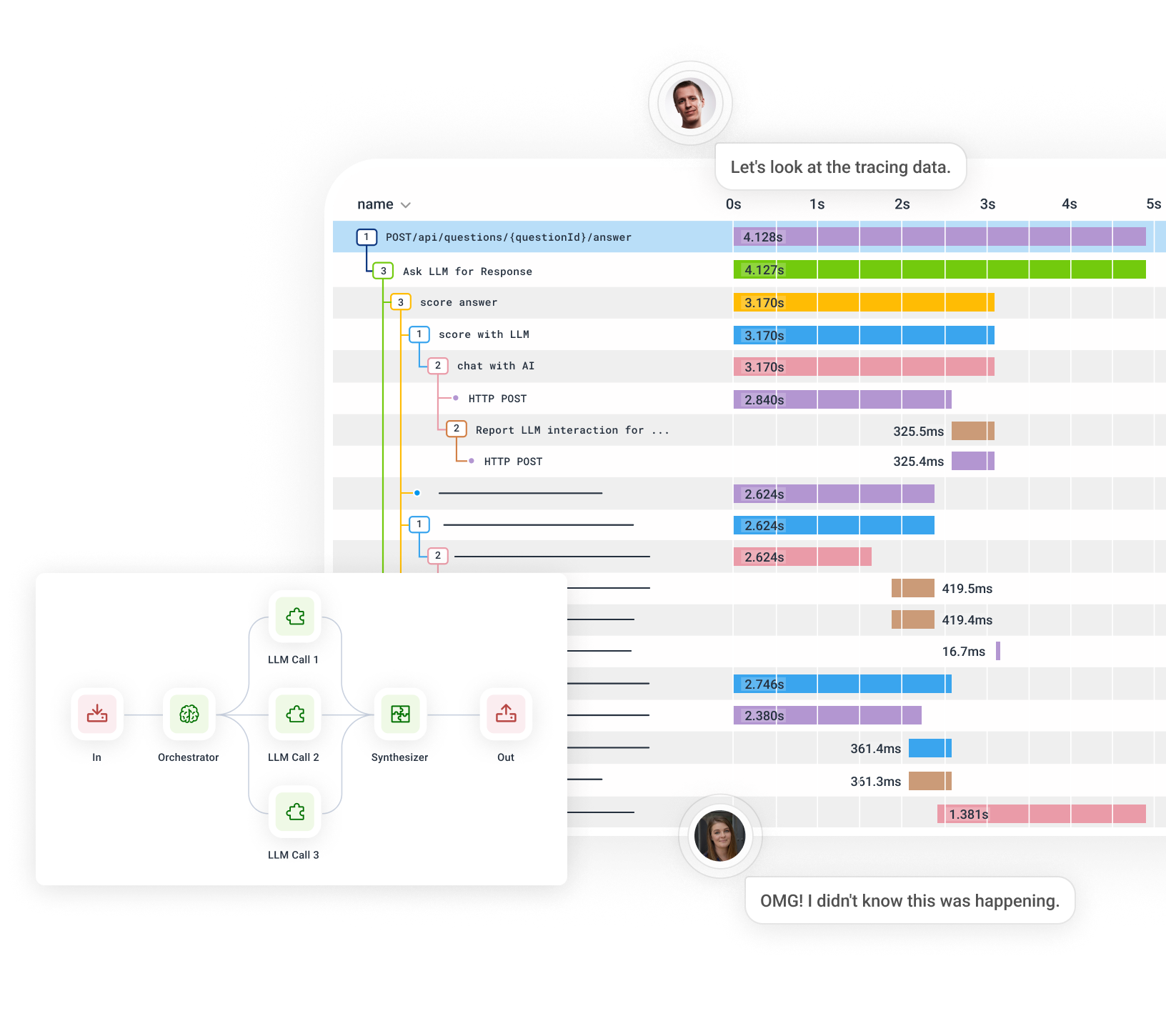
CHALLENGE
AI is a black box in production
Testing Limitations
Traditional testing methods are ineffective for AI-driven systems, requiring new approaches to evaluate performance.
Unpredictable Failures
Small changes in prompts or models can introduce unexpected issues and unpredictable failures.
Debugging Challenges
Tracing LLM execution is difficult, making it challenging to pinpoint when and why errors occur.
THE HONEYCOMB DIFFERENCE
Powerful, granular observability into LLMs
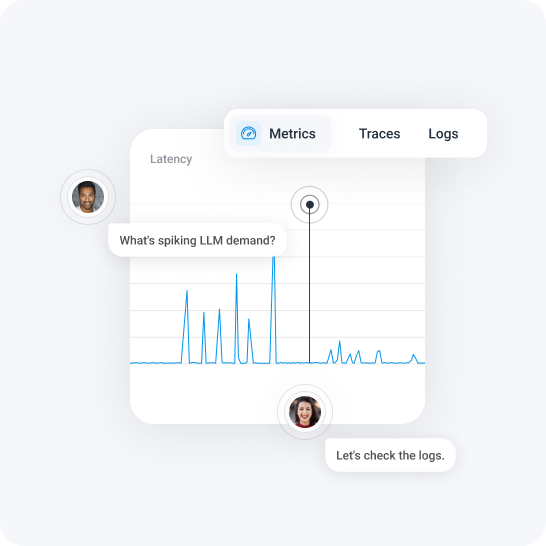
Honeycomb helps pinpoint issues, reduce hallucinations, and improve the quality of AI-powered applications. Understand system behavior as a whole, identify performance bottlenecks, and optimize your AI evals with real-world data.
Unify visibility into LLM behavior
Debug AI features faster
Improve AI features using production data
Monitor key health signals
Trusted by companies worldwide

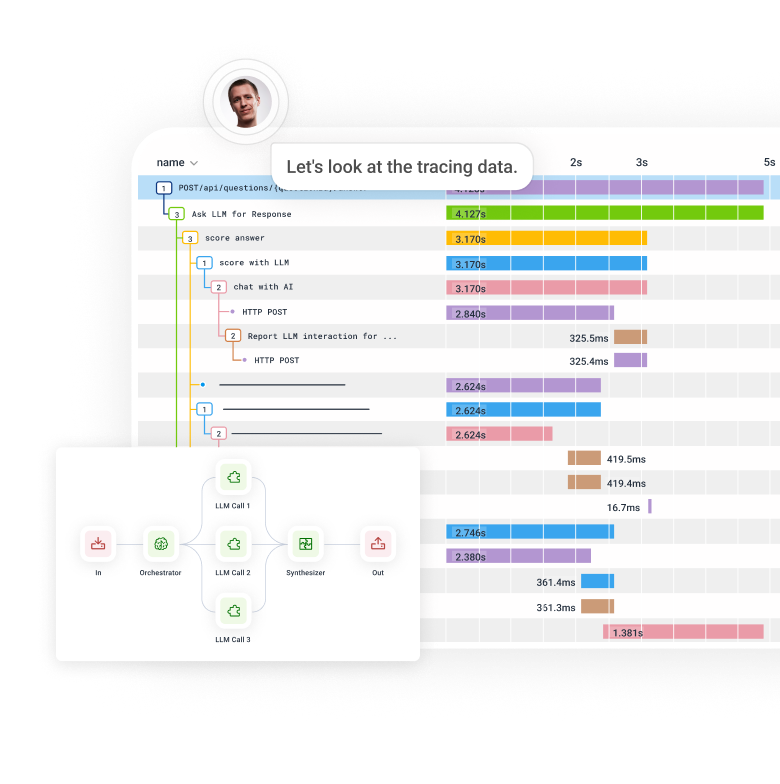
As systems get increasingly more complex, and nondeterministic outputs and emergent properties become the norm, the only way to understand them is by instrumenting the code and observing it in production. LLMs are simply on the far end of a spectrum that has become ever more unpredictable and unknowable.


Related features
Discover our full suite of features, giving you everything you need to easily solve problems.
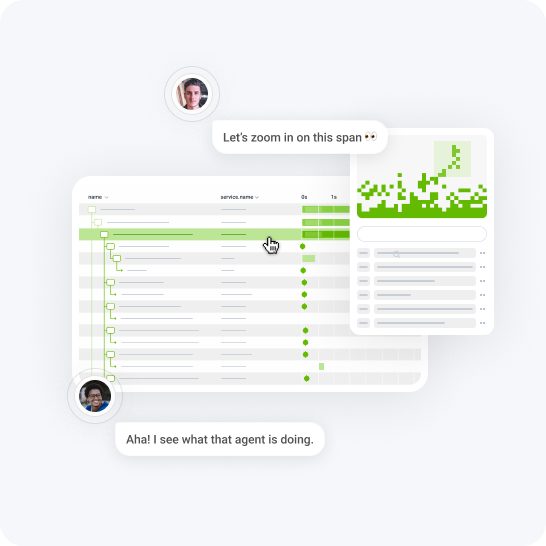
BubbleUp
Surface anomalies with our machine learning-powered anomaly detection tool, BubbleUp. Delve into metrics, traces, and logs to get to the bottom of any issues.
Query Assistant
Ask questions of your system in plain English with our AI-powered query assistant. Say goodbye to learning complex query languages!
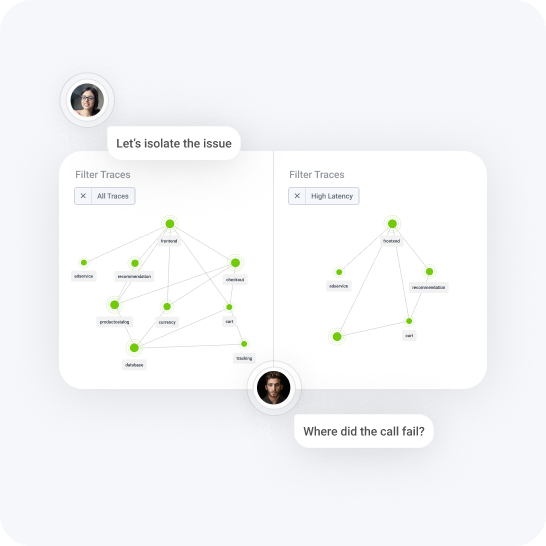
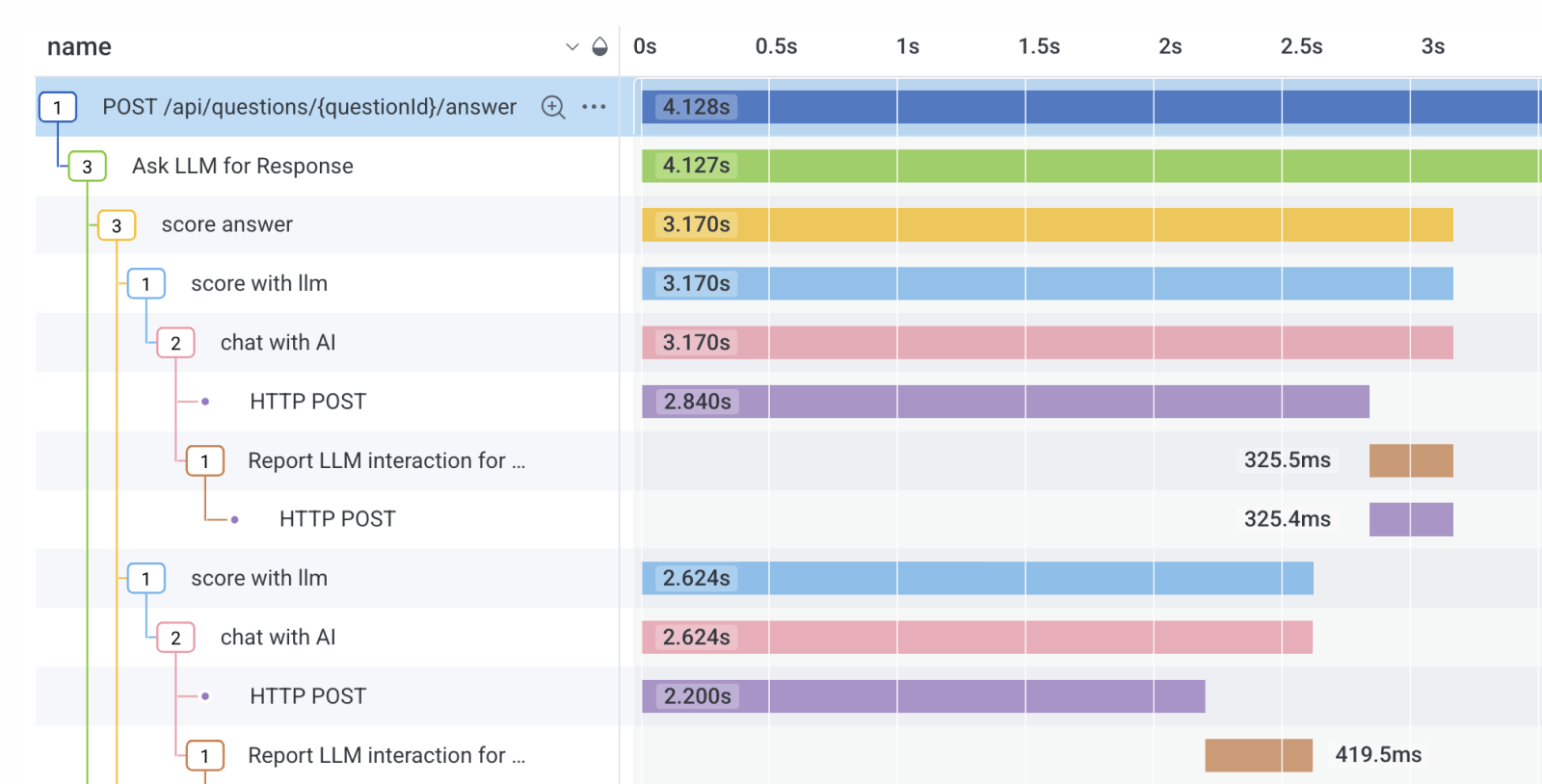
Distributed tracing
Trace AI workflows and agent execution. Quickly separate problematic behavior and drill into representative traces that contain the root cause.
Debug an LLM in our live tour
Explore how you can use Honeycomb to answer questions about LLM behavior.
Take a tour

Dive deeper
Learn more about the power and possibilities of Honeycomb.

Observability in the Age of AI
Honeycomb engineers were amongst the earliest adopters of this technology. Not in the widely parodied top-down, VP-mandated, “go be AI leaders nao plz” kind of way, but in a bottoms-up, experimental kind of way, driven by curiosity and fascination.

Using Honeycomb for LLM Application Development
Ever since we launched Query Assistant last June, we’ve learned a lot about working with—and improving—Large Language Models (LLMs) in production with Honeycomb. Today, we’re sharing those techniques so that you can use them to achieve better outputs from your own LLM applications. The techniques in this blog are a new Honeycomb use case. You can use them today. For free. With Honeycomb. If you’re running LLM apps in production (or thinking about it), these approaches should be useful.




Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.