Deploy on Friday? How About Destroy on Friday! A Chaos Engineering Experiment – Part 1
We recently took a daring step to test and improve the reliability of the Honeycomb service: we abruptly destroyed one third of the infrastructure in our production environment using AWS’s Fault Injection Service. You might be wondering why the heck we did something so drastic. In this post, we’ll go over why we did it and how we made sure that it wouldn’t impact our service.

By: Lex Neva


Ensuring Reliability in Kubernetes with Chaos Engineering and Honeycomb
Learn MoreWe recently took a daring step to test and improve the reliability of the Honeycomb service: we abruptly destroyed one third of the infrastructure in our production environment using AWS’s Fault Injection Service. You might be wondering why the heck we did something so drastic. In this post, we’ll go over why we did it and how we made sure that it wouldn’t impact our service.
Why? Chaos engineering.
We put significant effort into designing our systems to be able to continue operating reliably, even in the face of unexpected problems like hardware failures. That means that when an outage in our service does happen, by definition it was caused by something we didn’t expect. Part of designing for resiliency is continually improving the team’s understanding of our system, uncovering those unexpected failure modes, and fixing lurking reliability risks.
Up until now, we’ve been pretty sure our system could handle the failure of an AWS Availability Zone (AZ). An AZ is one of the basic units of scaling and reliability that allows us to deploy redundant copies of various parts of our infrastructure, analogous to a datacenter. Availability Zones can and do fail from time to time, and we need to be ready. It’s one thing to think we’re ready, but it’s another thing entirely to prove it.
In order to prove it, we used chaos engineering. When using chaos engineering, you form a hypothesis about how your system will behave in the case of a failure, and then you design a chaos experiment to prove or disprove the hypothesis. In this case, our hypothesis was: “If an entire AZ fails, our production service will continue operating with little or no customer impact.” No matter which way the experiment went, the opportunity for learning was tremendous.
Of course, there was potential risk as well. If our hypothesis turned out to be incorrect, we could cause a potentially serious incident. Most companies choose to avoid this risk by performing their chaos experiments in non-production environments, and in some, running experiments in production is simply out of the question. These experiments can still provide a great learning opportunity without risking your production environment.
In all cases, it’s best to start testing in non-production environments in order to gain an understanding of your system’s behavior and spot weaknesses early—and that’s exactly what we did. However, no non-production environment is ever entirely the same as production, which is why we test in production too. You simply never quite know how production will behave in an AZ failure until you experience one, and we didn’t want to wait until the next unplanned outage to start learning.
Risk mitigation
While we intended to test in production, we wanted to incur as little risk as possible. Our first strategy was to run experiments in non-production environments, find problems, and fix as many as possible. We also refined our failure simulation process in this phase with an eye toward giving ourselves an escape hatch. We wanted the failure simulation to be as realistic as possible while still allowing us to abort the experiment and quickly return to a stable state.
Unfortunately, that didn’t work out. Our hope had been to partition each individual host on the network, keeping it running but preventing it from contacting any other host. We quickly learned that Kubernetes, our infrastructure orchestration system, won’t easily accept a node back into the fold if it’s been gone for an extended period—at least not without extensive tuning. Achieving this goal would be complex, if it were even possible, and that complexity itself seemed likely to bring more risk than it mitigated. It was time to revise our plan.
From this point, we took a two-pronged approach to reducing our risk:
- We redoubled our efforts to test in non-production environments and uncover as many problems as we could.
- We also found ways to test isolated parts of the AZ failure in a controlled way in production. We did that to see whether production and non-production systems behaved differently—but we’ll cover that later on.
In our very first non-production test, we found that Basset, our service that processes Triggers and SLO notifications, couldn’t acquire a lock from Zookeeper and so was unable to run. Zookeeper had handled the failure of one of its nodes perfectly, and Basset was well aware of the other two nodes. So why couldn’t it get a lock?
require ‘zookeeper’
def get_zookeeper_connection(config)
config.zookeeper_hosts.each_with_index do |host|
begin
Zookeeper.new(host)
rescue RuntimeError => e
if i == config.zookeeper_hosts.length - 1
# only raise the exception if that was the last
# host, otherwise try the next one
raise e
end
end
end
endA quick bugfix later…
This code shows how the script requests a lock from Zookeeper. It should try the second and third Zookeeper host if it can’t connect to the first. However, the script spent its entire 30-second timeout trying to connect to the first Zookeeper node (the one that we had terminated), never getting around to trying the other two. A quick pull request and that bug was fixed!
…but then, false alerts with telemetry…
We also saw a problem with telemetry. Each of our environments is a copy of Honeycomb, and we monitor these environments by having them send their telemetry to another Honeycomb environment, in the same way that our customers use Honeycomb. While simulating an AZ failure in our Kibble environment, we saw that some Dogfood applications stopped sending their telemetry to Kibble, triggering a false alert. This was a really neat networking puzzle—keep your eyes peeled for a blog post about that!
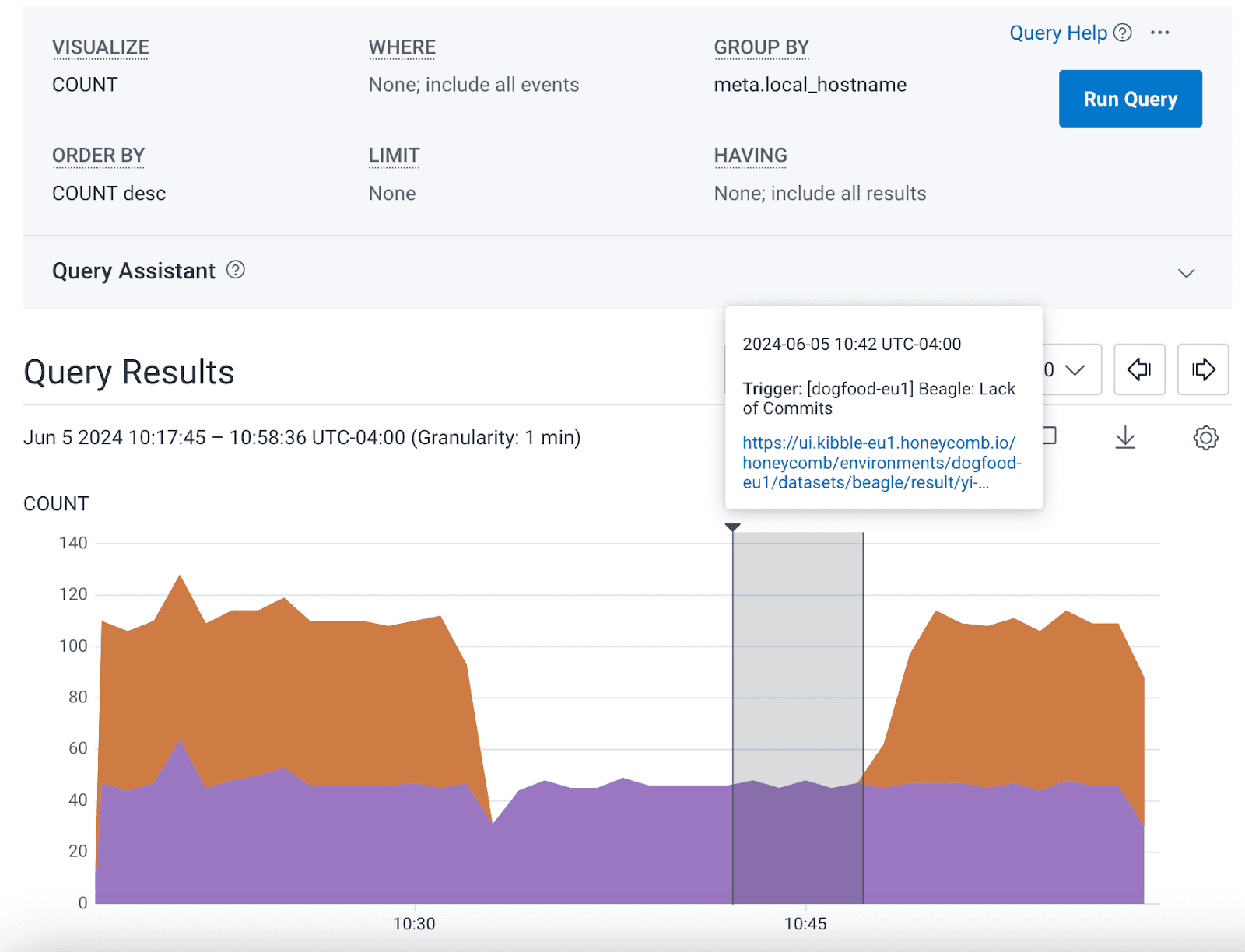
…and finally, some unexpected PrivateLink issues
We found that customers using our AWS PrivateLink offering would be disproportionately affected by the AZ failure test, with up to one third of their traffic never reaching Honeycomb for the duration of the test, instead receiving HTTP code 504. Fortunately, we caught this early in Dogfood—well before actual customer traffic was in jeopardy. That’s thanks to the fact that we send some of our Production environment’s own internal telemetry to Dogfood through PrivateLink. We were able to design a potential mitigation strategy and prove that it prevented customers using PrivateLink from being affected.
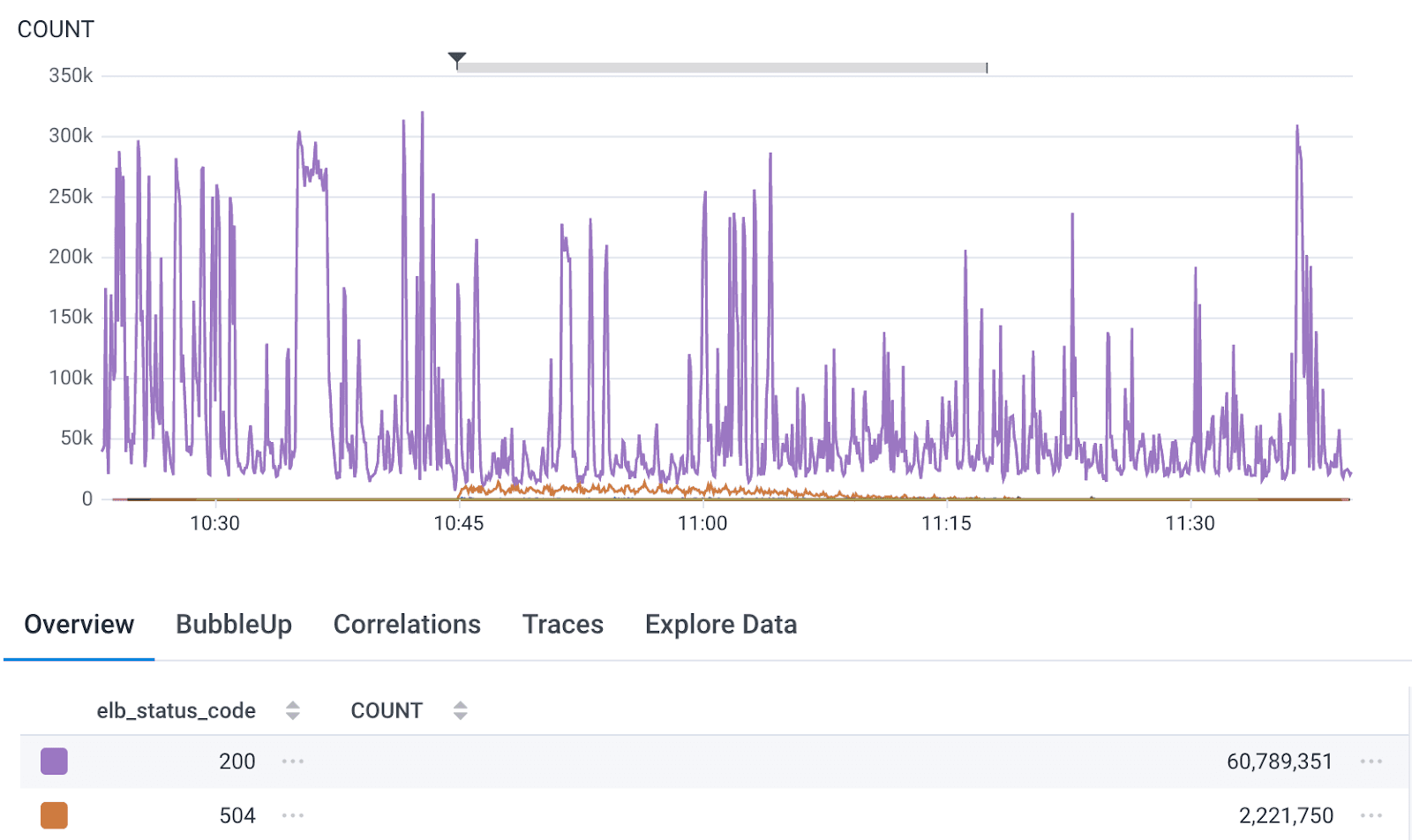
But how will production behave?
By this point, we had run over a dozen non-production tests and gained a thorough understanding of how our system behaves when faced with an AZ failure. We had also become quite efficient at simulating an AZ failure using AWS’s Fault Injection Service (FIS)—more on that in part two of this series. We weren’t done yet, though. We still needed to know, does Production behave in the same way as Dogfood and Kibble?
The answer was no—at least not for some parts. It’s easy to see why: no other environment has the sheer volume of traffic that Production has. This became most apparent in Shepherd, the service that answers requests to api.honeycomb.io and accepts customer telemetry. Production sees a relatively even flow of customer requests and uses a steady 80-90% of the CPU cores that we assign to it. If it uses more or less, our autoscaler kicks in and adds or removes Shepherds to balance out the load.
In Dogfood, however, Shepherd tends to use only 20% of the CPU cores assigned. That’s because the telemetry load reaching Dogfood is rather bursty. The autoscaler scales Shepherd up for a spike, but only scales back down slowly because of the way we’ve configured it. Most of the time, Dogfood is under light load—around 20-30%.
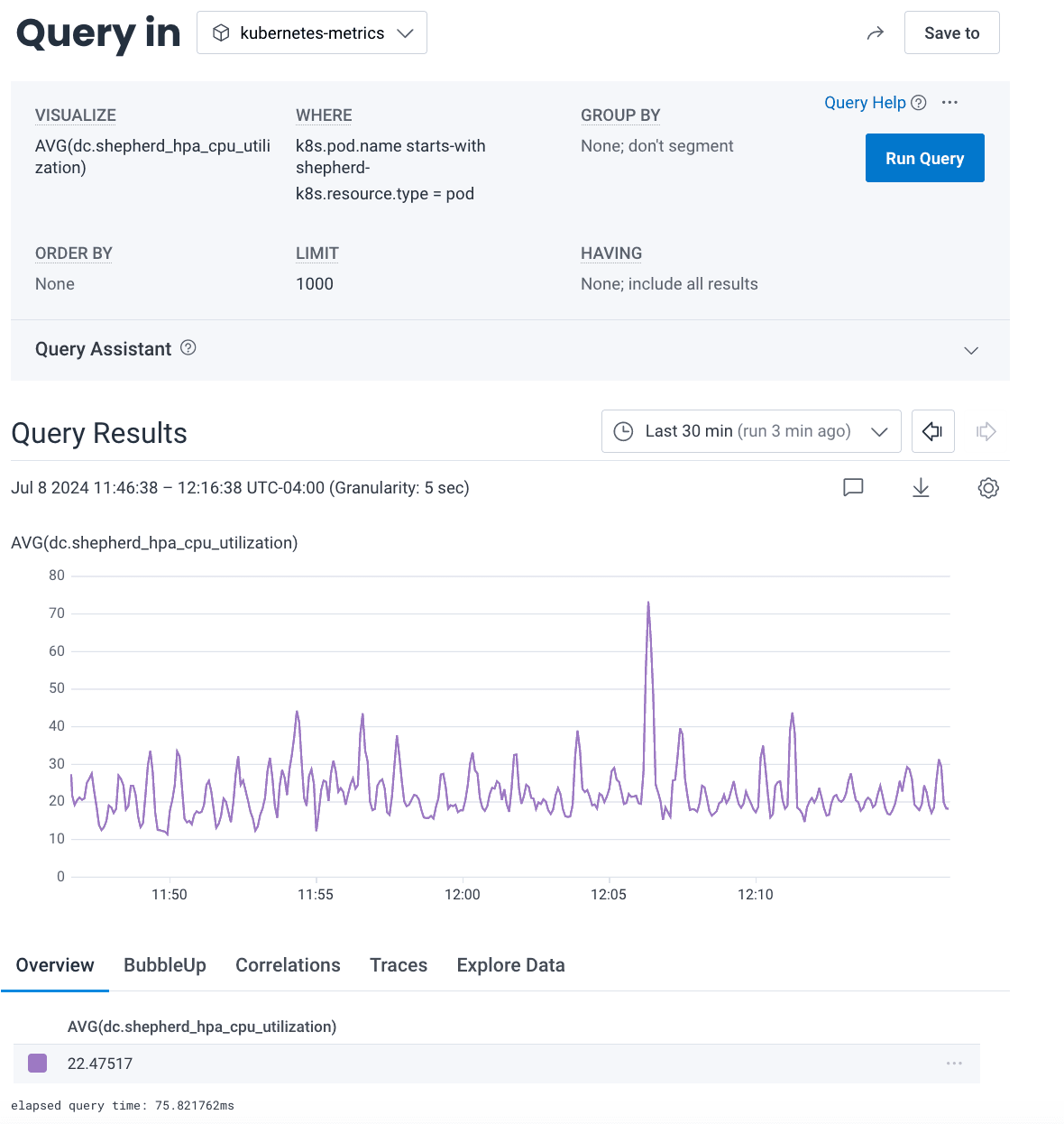
The key question was, “Will Production’s remaining Shepherd nodes be able to burst to handle the extra load that comes when we terminate one AZ?” We use Kubernetes, and we’ve purposefully structured our cluster to allow Shepherd to burst to around 150% of its normally-assigned CPU cores (that is, we’ve set the Limit to around 150% of the Request, in Kubernetes parlance). We hypothesized that this bursting should handle the excess temporary load on the remaining Shepherd nodes until Kubernetes was able to launch replacements in the remaining two AZs, but this is chaos engineering! We had to test our hypothesis.
We performed isolated failure simulations on just the Shepherd service, first in Dogfood and then, slowly and carefully, in Production. By terminating a few Shepherd pods at a time, we were able to see how much load the remaining pods endured and whether they performed properly. We slowly increased the number of pods we terminated at once, watching our telemetry as we went. Finally, we performed multiple tests in which we terminated an entire third of our Shepherd pods at once, and the system handled the load with ease and without impact to customers. We even ran one of these tests during our weekly internal Friday Demo Day, live, with many of our engineers watching! These tests showed us that we could lose one third of our Shepherd pods simultaneously and still have room to handle additional coincidental failures, should they occur.
Kafka just kind of… tested itself?
We planned to perform a similar kind of test on another important system, Kafka. That turned out to be unnecessary, because a coincidental failure tested Kafka for us! After a routine software version update, three of our nine Kafka nodes failed in rapid succession—the most we’d ever seen fail in one go. We sprang into action, diagnosed and fixed the underlying cause of the failures, and prevented an outage. Meanwhile, we noted that the remaining six nodes had handled our full production load with resources to spare, such that we could likely handle even one more node failure. This little surprise gave us confidence that Kafka could handle an AZ failure without a problem.
Confidence = rising
By this point, we had gained a high degree of confidence in our system’s ability to handle an AZ failure. We had honed our simulation procedure and written runbooks to handle unlikely failure modes we had identified, primarily around the slight possibility of additional coincidental failures.
Through all of this, we also kept a close eye on the durability of customer data. We keep at least three copies of customer data (and often more), such as by storing customer events in the incredibly durable Amazon S3. We knew that customer data would never be at risk.
To peak, or not to peak?
We were ready to go to production! Just one thing remained: scheduling the test and posting it to the status page as scheduled maintenance. Often, companies choose to run such tests at non-peak times, and we initially considered this as well. Ultimately, however, we decided to run the test just after peak and on a Friday. Why?
First, there’s the question of peak vs off-peak. While our daily traffic shows a noticeable peak, the trough is still a significant level of traffic. Many of our internal components use autoscaling, meaning that they behave largely the same in both peak and trough traffic, and that diminishes the benefit of doing the test off-peak.
At the same time, off-peak hours fall outside of our engineers’ normal working hours. If anything unexpected occurred despite our careful preparation, we’d need to launch an incident, and we could lose valuable time while summoning engineers to help. Out-of-hours incident response is inherently risky, as engineers that are not well-rested are more likely to make mistakes despite how careful they are. We felt that these heightened risks easily outweighed any theoretical additional risk involved in running the test close to peak.
Finally, we wanted to ensure that we learned as much as possible from the test. For the components of our system that are affected by the traffic level, we wanted to understand whether they could handle an AZ failure test at peak.
With all of these factors combined, we knew that running the test near peak was the best choice and presented the least risk. We chose Friday simply because that was the day that worked the best for all of the internal teams that would be involved.
How did it go?
To find out how our test went, check out part two!
Inject more chaos into your life! Watch the webinar.
In the meantime, if you’re interested in learning more about chaos engineering, watch our webinar with Sylvain Hellegouarch, CEO of Reliably: Ensuring Reliability in Kubernetes with Chaos Engineering and Honeycomb. It’s a fun watch on topics we’re passionate about.
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.