

Honeycomb recently released our Query Assistant, which uses ChatGPT behind the scenes to build queries based on your natural language question. It’s pretty cool.
While developing this feature, our team (including Tanya Romankova and Craig Atkinson) built tracing in from the start, and used it to get the feature working smoothly.
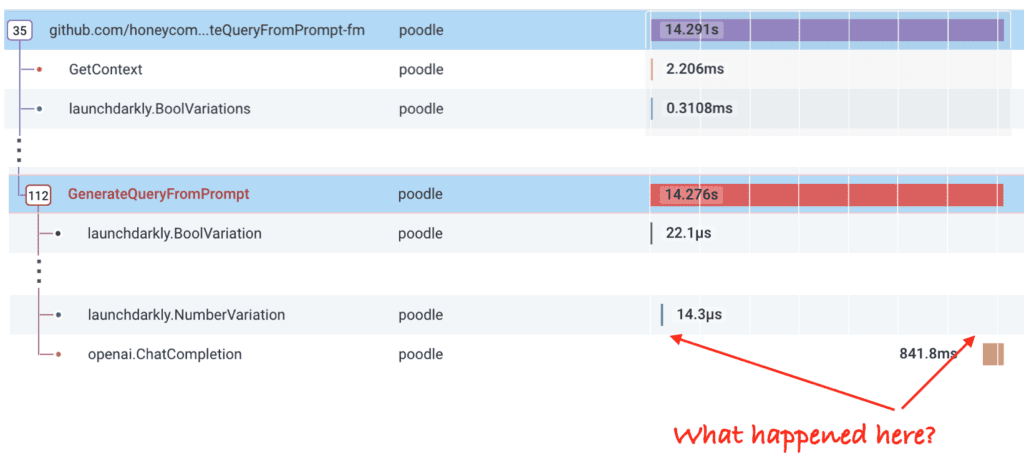
Here’s an example. This trace shows a Query Assistant call that took 14 seconds. Is ChatGPT that slow? Our traces can tell us!
The API call to ChatGPT is called “openai.ChatCompletion” and it took 840ms. What happened during the 12+ seconds right before that? We can’t tell!
So Craig and Tanya added some instrumentation. They created spans representing important units of work: constructing the prompt, and as part of that, truncating the list of available fields we send as part of the prompt. Now we can see what’s happening!

To truncate the column list, we call a library that counts tokens in the prompt. With traces that show how long it’s taking, Tanya and Craig tried various optimizations until they landed on one that was close enough on the token count—and much, much faster. Here’s the trace from a query I ran today:

This is observability during development: see what you’re doing, make the feature better, and keep that same visibility in production.
Want to learn more? Read the announcement on Query Assistant, and try it yourself by signing up for Honeycomb today.





