Massdriver is a cloud operations platform that makes it easier for engineering teams to build, deploy, and scale cloud-native applications. While many companies use this lofty language to make similar promises, Dave Williams, CTO and co-founder at Massdriver, means it.
Before Massdriver, Dave worked in product engineering where he was constantly bogged down with DevOps toil. He spent his time doing everything except what he was hired to do: write software. He founded Massdriver to help engineering teams build and release faster while limiting and managing the complexity of the cloud.
Dave and his co-founders knew from the start that observability had to be a priority. They also understood that relying on logs alone wouldn’t cut it. So, they solved ‘log lag’ by using industry best practices: instrumenting with OpenTelemetry (OTel) and debugging with tracing.
Dave recently joined Honeycomb for a technical session to share how he got his team on board with implementing observability, and tips on how to avoid the perils of relying on logs alone.
The need for observability
Massdriver’s founders knew from the beginning that they would face challenges that would make observability a necessity—not a perk. With an engineering team of just six people running an enormous and complex application, they would have to test in production and narrow down possible errors quickly, making real-time context and tight feedback loops key.
In the past, when Dave was a software developer, he suffered through many middle-of-the-night fires because observability tooling was ignored. He saw firsthand how a lack of observability makes it nearly impossible to diagnose problems—and worse, how it diverts already lean resources away from actual crises to false alarms. Wasted time and resources are a sink-or-swim reality, so he needed to eliminate this risk if the team was going to scale.
Thankfully, most of the founding team had similar experiences. This made getting them to buy in on observability easier from the get-go. As such, they first needed to answer not whether to implement observability, but rather which platform was right for their team. This was where the advantages of Honeycomb became clear.
With its supercharged query engine, Honeycomb is built to answer complex questions
Dave initially encountered Honeycomb a few years ago using its interactive Sandbox to diagnose a theoretical issue. It made a lasting impression: “I love the Sandbox experience and its ease of use. I’ve been a Honeycomb fanboy for a long time.”
Even before choosing Honeycomb, Dave was all in on OpenTelemetry (OTel). “Before production observability was even a consideration, our product ran in Docker Compose. We used Jaeger and an OTel exporter. I’m a test-driven developer and spent a lot of time with Jaeger while unit testing. From the start, I wanted to make sure that I knew how our system worked so that I could know what was going on in production.”
The Massdriver team tried another observability platform to get an idea of what was out there, and it became apparent that it was an absolute no-go. “It lacked advanced filtering and querying capabilities. You had to declare what information you wanted to be able to filter on upfront. It took up more time than we wanted it to,” Dave explained.
Honeycomb, on the other hand, immediately felt right. Its datastore and query engine are purpose-built to detect patterns across billions of requests in seconds, even with high-granularity data. The unmatched speed and limitless combinations of searchable attributes make Honeycomb a gamechanger for engineering teams because it helps them avoid dead ends typically found with stale dashboards and logs.
The culture shift to OpenTelemetry, distributed tracing, and Honeycomb
Dave explained that Honeycomb’s developer-centric UI made getting the engineering team on board with observability easy: “Honeycomb just worked out. The team saw what the tool could offer, making it easy for them to adopt.”
The cultural shift to observability within the Massdriver team also gave them better control over data leakage, compliance, and security. “Leaving things to chance using auto-instrumentation was a nonstarter for us,” Dave explained. “With OpenTelemetry and Honeycomb, it felt like we were in more control of protected information. We had a better picture of two systems operating in tandem to ensure our customers’ security; this was one of the biggest ‘aha’ things that solidified OTel as the better approach for managing large volumes of telemetry.”
Dave was also struck by how easy integrating OpenTelmetry with Honeycomb was for fast analysis, particularly compared to pulling logs. “We loved the ability to use distributed tracing from day one. It helped us better understand how our system functions flowed across isolated accounts, one of which is air-gapped.” Honeycomb’s distributed tracing allowed Dave’s team to get valuable contextual information quickly, which resulted in overall faster debugging.
Socialization of production insights
Honeycomb’s ability to socialize and make data accessible was vital to the team’s buy-in. Honeycomb’s query history provides a ton of value for Dave’s team. “When one of our engineers was stuck, they could look at my past queries as a jumping-off point to get started. From there, they could modify it a bit until they were able to find what they were looking for,” Dave explained.
This helped team members build their confidence in using Honeycomb and scaled their ability to quickly debug issues—beyond just a couple of power users. It also enabled the team to start building a shared vocabulary, enhancing the team’s understanding of each other and the system at large.
Addressing the challenges of GraphQL and the resulting alert fatigue
Dave also spoke about Massdriver’s use of GraphQL, which adds challenges around alert fatigue. “If you’re familiar with GraphQL, you probably know that everything is a 200,” Dave explained. “It’s hard in other tools to filter those expected statuses out so that you can get reasonable alarms. For a long time, alarms were difficult and distracting to the team.”
If you’re unfamiliar with 200s, here’s a very short primer: normally, when you get a 200 status code, that means everything’s ok. However, with GraphQL, you could still get resolver errors. Dave’s team needed a way to filter out which 200s were ok and which weren’t, but most monitoring tools don’t allow you to create conditional alerting based on the response body itself. However, Honeycomb does, and it helped Dave’s team parse out normal 200 status codes versus those that had resolver errors, drastically reducing the amount of alerts that came in, and making clear that if an alert did come in, it was most likely a real, actionable alert. This was a huge quality of life improvement for the engineers on Dave’s team.
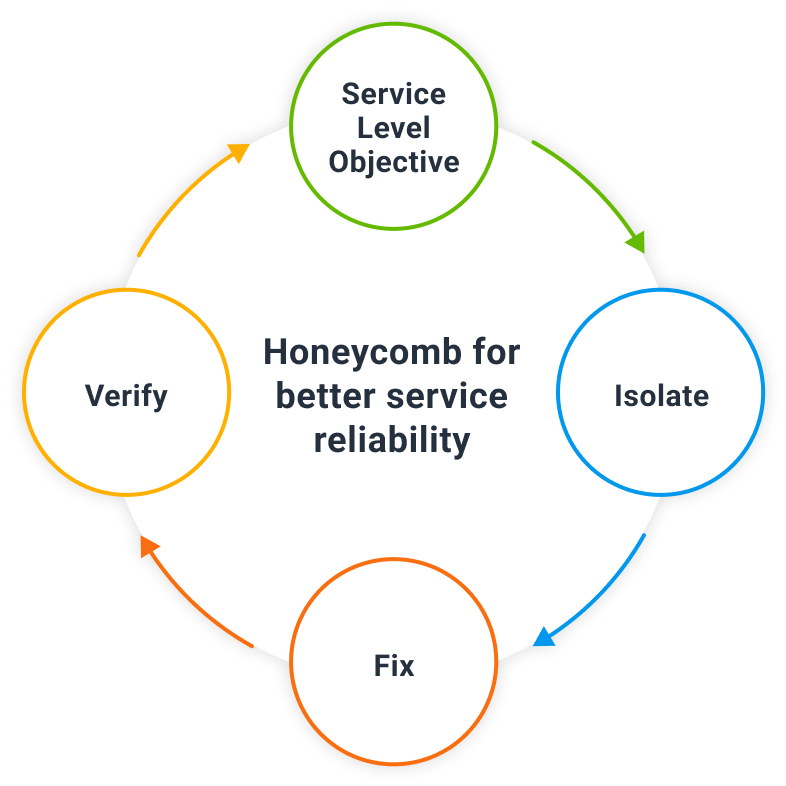
Mapping Service Level Objectives (SLOs) to user experience and business priorities
Dave spoke about the importance of Service Level Objectives (SLOs) for the future of Massdriver. “Eventually, there’s a board of directors that’s going to say, ‘What’s our quality of service?’ Triggers are useful for finding an incident immediately, but they don’t tell you how good your organization is doing overall.”
He explained that adopting SLOs is a process of maturity for a firm. It means the team is no longer thinking on a short-term startup timescale. “You’re holding yourself accountable for not just what’s happening minute-to-minute, but what’s happening day-to-day, week-to-week,” Dave continued. “We spend time reviewing incidents: How much of a problem was this? How are we doing generally? Those will eventually become SLOs.”
Dave realizes that SLOs can help the team prioritize fixes for different user bases and prove the value of specific actions to the business side. “We need a sense of impact. How much time is it worth for my engineering team to invest? If it’s an intermittent problem with minimal impact, it’s probably getting pushed down the road. If it’s a quicker fix affecting a good number of users, that’s value,” Dave stated. “It’s about adopting the engineering mindset throughout our entire organization.”
It’s important to Dave to make sure that SLOs are set up in a way that less technical business stakeholders can understand and navigate them. This levels the playing field and aligns other functions with engineering priorities to make sure they are supporting the goals of the business. It’s a great way to translate engineering lingo into business impact.
Stop treading water with logs. Try Honeycomb.
The Massdriver team plans to prioritize observability as they expand their focus on SLOs and further grow their business. Honeycomb will be a vital part of that journey. As Dave put it, “Honeycomb was our first choice, and we’ve been happy with it ever since.”
Are you drowning in a sea of logs? There are a few different things you can try next:
- If you’re a developer, chat with one of our own developers about this post!
- If you’re leading the observability shift in your org, chat with us to see how Honeycomb can transform your logs into useful context with tracing.
- If you’d prefer to keep soaking in all the observability knowledge, try our Sandbox and get the Honeycomb experience—no signup required. Dave liked it, and you might too!





