One of the things that struck me upon joining Honeycomb was the seemingly laissez-faire approach we took towards internal SLOs. From my own research (beginning with the classic SRE book, following Google’s example), I came to these conclusions:
- SLOs are strict. They aren’t as binding as an SLA, but burning through your error budget is bad.
- SLOs/SLIs need to be documented somewhere, with a formal specification, and approved by stakeholders.
- SLOs should drive customer-level SLAs.
- Teams should be mandated to create a minimum number of SLOs for the services they own.
If you read the original SRE book when it was released, before the workbook came out, these conclusions all made sense. I tried to implement this approach at a startup or two with varying levels of success—and by “varying,” I mean “very little,” as I perhaps took the material in the book too literally and didn’t consider the context in which I applied it enough.
The approach that the SRE book advocates—as most of us understand now—is great for Google, but none of us are Google (it seems that we all continue to learn this). The workbook, and Alex Hidalgo’s Implementing Service Level Objectives, both have great examples of some of the more successful implementations of SLOs.
Customer-oriented SLOs
One of the better things that I had taken away, at the time, was the customer orientation of their SLO approach: figure out what your customers care about, measure it, determine what an unacceptable level of service is, and alert on it. This, I found, is the best way to give upper management the big “are we up?” chart that they ask for (possibly as a symptom of low trust or confidence in engineering). If you’re running a basic web app, this could mean things like:
- The homepage takes less than one second to fully render.
- When submitting an order, there are no errors.
- Backend order processing completes in under 30 seconds.
The important thing about all of these is that it’s okay if they aren’t met 100% of the time. It’s expected, in fact; that’s why Honeycomb exists. We just need to find a threshold over a certain period of time that’s acceptable to us: if 99% of homepage renders take less than one second, we’re all good (this can hide some nasty problems, though, because if 1% of your users consistently experience 30 second load times…).
There have been much better posts (and books) written about defining SLOs, but my point is that SLOs are what allowed me to start thinking from the customer perspective again, something I had lost after my move to DevOps/SRE. In the end, we’re here to provide a service for our customers and users. However, the process of actually implementing SLOs was a difficult problem, hence why many SREs newer to the field took their cues from Google.
How Honeycomb defines SLOs
The way Honeycomb defines SLOs is radically different from what I expected. Instead of the definitions I wrote about at the beginning of this post, I saw:
- Flexible SLOs: We hold ourselves to an extremely high internal standard, but an SLO burning down faster than normal is merely a signal or alert that something is wrong. Reset the burndown chart if normal service has been resumed, so it can start providing signal again. Teams might update the threshold or definition if the stakeholders agree a different level of reliability makes sense.
- On-call authority: Speaking of flexibility, on-call has the authority to silence or disable a particularly noisy SLO they are being alerted by—or one that isn’t serving its purpose—as well as the responsibility to follow up with stakeholders and peers. Outside of on-call, if a budget is continually burning too fast, the SRE team might call a discussion between engineering, product, customer success, and support, and decide whether we need to adjust our expectations or shift work to meet them.
- Documentation: There is no authoritative document other than the SLO itself within Honeycomb, though it usually has rich descriptions and is usually created with input from many stakeholders and teams. A log is kept of burn alerts that are reset, and documentation maintained about our philosophy of SLOs.
- Internal SLOs: The SLOs that are internal or department-specific don’t need to have the same cross-team or customer-facing standards. However, everyone still needs disk alerts.
- Availability: SLOs and incident metrics are relevant to measuring availability, but they are not directly tied to customer SLAs. There are numerous reasons for this that are above my station, but it allows us to have extremely high internal standards along with an extremely low bar for calling an incident, a key aspect of our safety culture. Anyone should feel comfortable raising the alarm for any reason.
- SLO implementation: How many, and what kind, is up to the team that owns it. We don’t have a minimum number of SLOs (providing reliable service with zero alerts might raise some eyebrows, though), and the SRE team plays an increasingly consultative role in their creation. This could change as Honeycomb grows, but it works for now.
A whole lot of alerting
If you’ve ever held the DevOps/Infrastructure/Platform/SysOps Engineer title, this sounds a hell of a lot like good alerting—and it should. Much like that decades-old practice, the notifications and alerts coming from the SLO should be primarily actionable, and if not, it should tell you something important about the state of the system. Many hypotheses have been proven or disproven mid-incident from an SLO burn alert firing or failing to fire.
Finding the right things to measure, in what quantity, and over what time period in an SLO wasn’t exactly rocket surgery either: largely, reaching across the organization to customer support is a great way to find something to monitor. If you care about the experience of your users, there is an incredible amount of signal in the part of your organization that talks to those users tens, or hundreds, or thousands of times daily.
[…] Can you describe what the metric stands for in enough detail to know when it’s irrelevant and you’re free to disregard it, or when it’s important stuff you actually need to worry about? Do we have enough clues about the context we’re in to know when they’re normal and abnormal regardless of pre-defined thresholds? If we don’t, then we’re giving up agency and just following the metric. We’re driving our vehicle by looking at the speed dial, and ignoring the road.
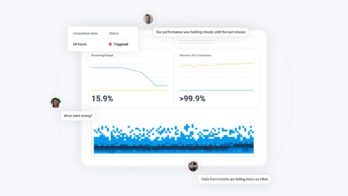
If you’re curious about some of Honeycomb’s internal SLOs, an excellent example of one that provides us a huge amount of value is our end-to-end checks SLO. This is a service that continuously tests our core product by submitting data for ingestion, then checking to make sure that data becomes queryable across all of our partitions. If this data is delayed—or never shows up—means we are no longer meeting our internal goals for data availability (or ingestion speed). You can see an excellent exploratory of this data in this post about Derived Columns.
I hope this blog helps you create and implement your own SLOs! Our pro plan offers support for SLOs and we’d love for you to give ‘em a spin. Contact sales to get started.