Get all your observability data in one unified platform with limitless possibilities.
Discover why Honeycomb is the better choice for your engineers, your customers, and your bottom line.
Explore our latest blogs, guides, training videos, and more.
Give all software engineering teams the observability they need to eliminate toil and delight their users.
Kyle Moonwright | Jun 27, 2023
Insightful proof-of-concepts with a tool can be difficult to undertake due to the demands on valuable resources: time, energy, and people. With a task as grand as observability, how could one truly test if Honeycomb and OpenTelemetry are right for their organization and meet their requirements? For this thought experiment, here’s a comprehensive description of the ideal product evaluation over the course of four weeks, given unlimited resources.
Fred Hebert | Jun 26, 2023
People seem to struggle with the idea that there are no repeat incidents. It is very easy and natural to see two distinct outages, with nearly identical failure modes, impacting the same components, and with no significant action items as repeat incidents. However, when we look at the responses and their variations, we can find key distinctions that shows the incidents as related, but not identical.
Mike Terhar | Jun 23, 2023
OpenTelemetry and Beelines were designed with assumptions about the types of traffic that most users would trace. Based on these assumptions, web application and API calls fit very nicely into a trace waterfall view. This is also the set of assumptions for Refinery, our sampling proxy, to manage the traces it processes. These assumptions are true for most traffic.
Jessica Kerr | Jun 21, 2023
At Honeycomb, we are all about observability. In the past, we have proposed observability-driven development as a way to maximize your observability and supercharge your development process. But I have a problem with the terminology, and it is: I don’t want observability to drive your development.
Phillip Carter | Jun 16, 2023
In early May, we released the first version of our new natural language querying interface, Query Assistant. We also talked a lot about the hard stuff we encountered when building and releasing this feature to all Honeycomb customers. But what we didn’t talk about was how we know how our use of an LLM is doing in production! That’s what this post is all about.
Ian Smith | Jun 14, 2023
When considering a migration to Kubernetes, as with any major tech upgrade or change, it’s imperative to understand the motivation for doing so. The engineering time and labor to execute a complex migration will take away from other priorities, making it crucial to have org-wide alignment on why the change makes sense.
Martin Thwaites | Jun 13, 2023
We saw a shift this year in how the technology sector honed in on sustainability from a cost perspective. In particular, looking at where they’re spending that revenue in the infrastructure and tooling space. Observability tooling comes under a lot of scrutiny as it’s perceived as a large cost center—and one that could be cut without affecting revenue. After all, if the business hasn’t had a problem in the last few months, we mustn’t need monitoring—right?
Nathan Lincoln | Jun 12, 2023
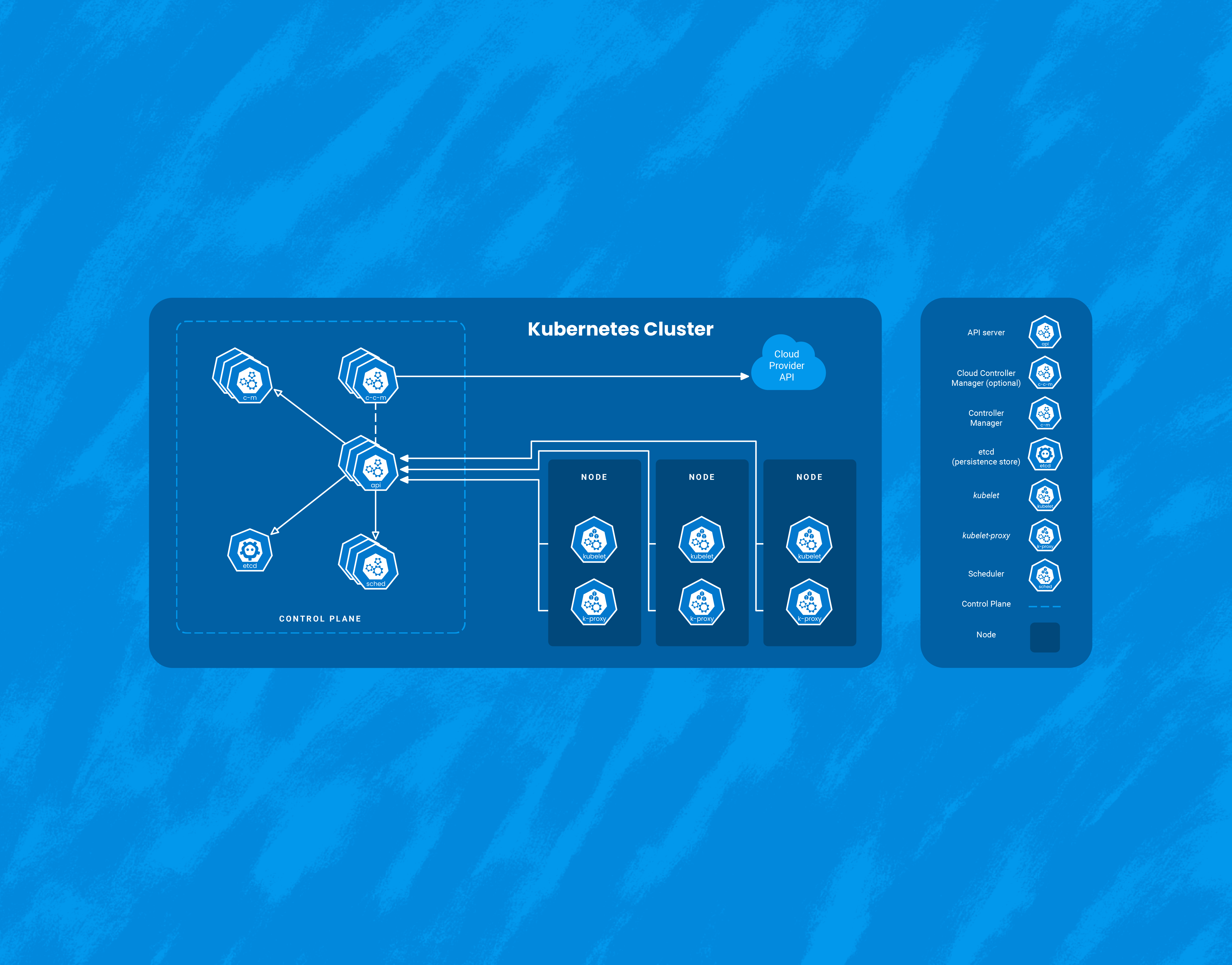
While Kubernetes comes with a number of benefits, it’s yet another piece of infrastructure that needs to be managed. Here, I’ll talk about three interesting ways that Honeycomb uses Honeycomb to get insight into our Kubernetes clusters. It’s worth calling out that we at Honeycomb use Amazon EKS to manage the control plane of our cluster, so this document will focus on monitoring Kubernetes as a consumer of a managed service.
Rebecca Carter | Jun 09, 2023
Kubernetes helps teams of all sizes optimize their microservices architecture by enabling seamless automated containerized app deployment, easy scalability, and efficient operations. But Kubernetes also has a reputation for being difficult to learn and complex to manage, and when you’re new to something, it’s hard to know what you don’t know. That’s where Honeycomb observability comes in—distributed traces provide real-time visibility into container operations so they can be fine-tuned for optimal performance and bugs can be found and fixed faster, paving the way to a successful delivery.
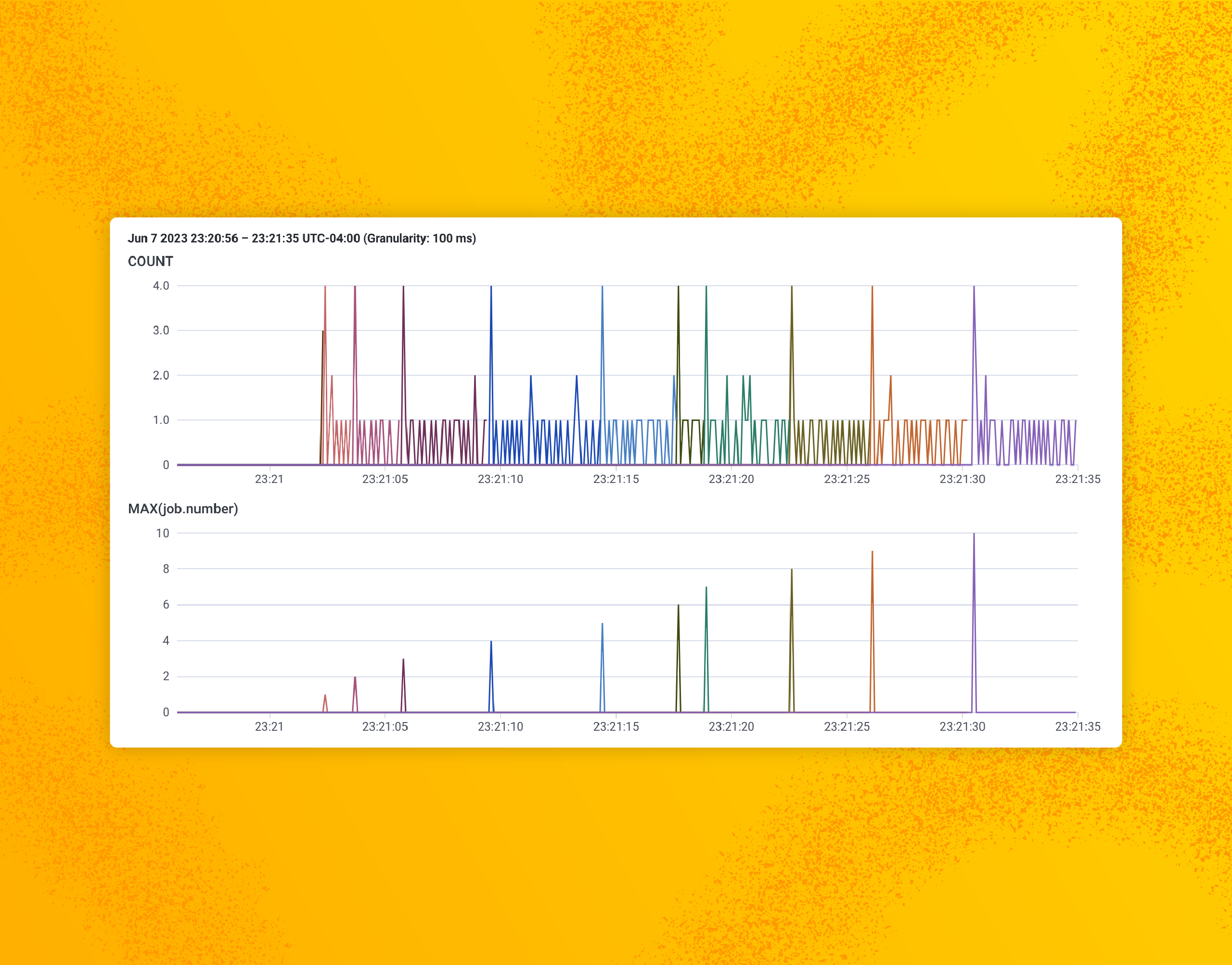
Tyler Helmuth | Jun 07, 2023
Running a Kubernetes cluster isn’t easy. With all the benefits come complexities and unknowns. In order to truly understand your Kubernetes cluster and all the resources running inside, you need access to the treasure trove of telemetry that Kubernetes provides. With the right tools, you can get access to all the events, logs, and metrics of all the nodes, pods, containers, etc. running in your cluster. So which tool should you choose? Since we are all in on OpenTelemetry, we think the best solution is the OpenTelemetry Collector.
Tyler Wilson | Jun 05, 2023
Frontend observability is a tricky problem. No website is free of errors or slowdowns; sites break down in weird ways for all kinds of reasons. Accounting for every possible combination of platform, browser, extensions, and (sometimes baffling) user behavior would be an impossible task. How do we decide which errors are important? One useful framework for making these frontend development decisions is customer-centric observability.
Mike Terhar | Jun 01, 2023
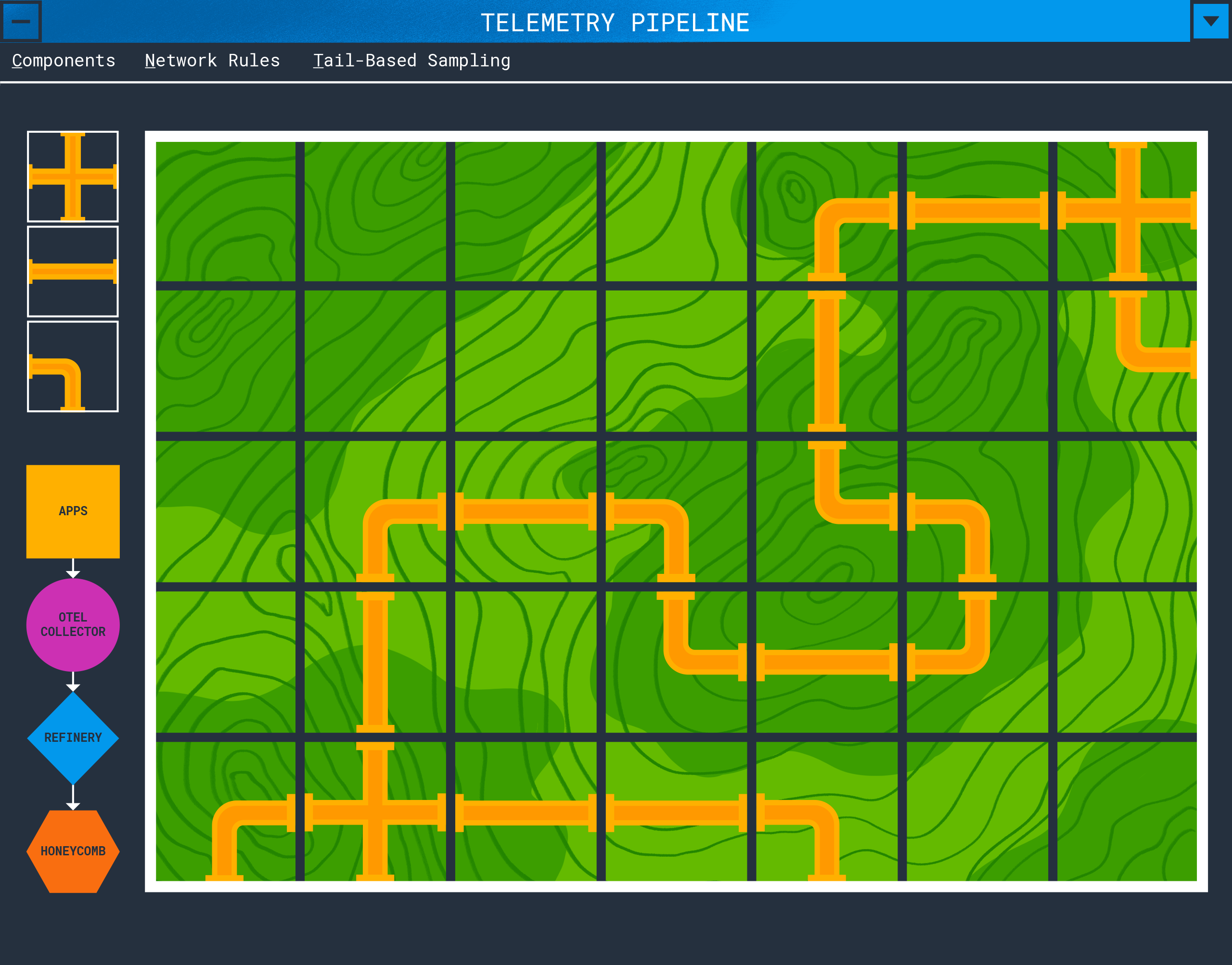
In a simple deployment, an application will emit spans, metrics, and logs which will be sent to api.honeycomb.io and show up in charts. This works for small projects and organizations that do not control outbound access from their servers. If your organization has more components, network rules, or requires tail-based sampling, you’ll need to create a telemetry pipeline.