Get all your observability data in one unified platform with limitless possibilities.
Discover why Honeycomb is the better choice for your engineers, your customers, and your bottom line.
Explore our latest blogs, guides, training videos, and more.
Give all software engineering teams the observability they need to eliminate toil and delight their users.
Martin Thwaites | Mar 03, 2023
So you're used to debugging systems using a distributed trace, but your system is about to introduce a message queue—and that will work the same… right? Unfortunately, in a lot of implementations, this isn't the case. In this post, we'll talk about trace propagation (manual and OpenTelemetry), W3C tracing, and also where a trace might start and finish.
Rebecca Carter | Mar 01, 2023
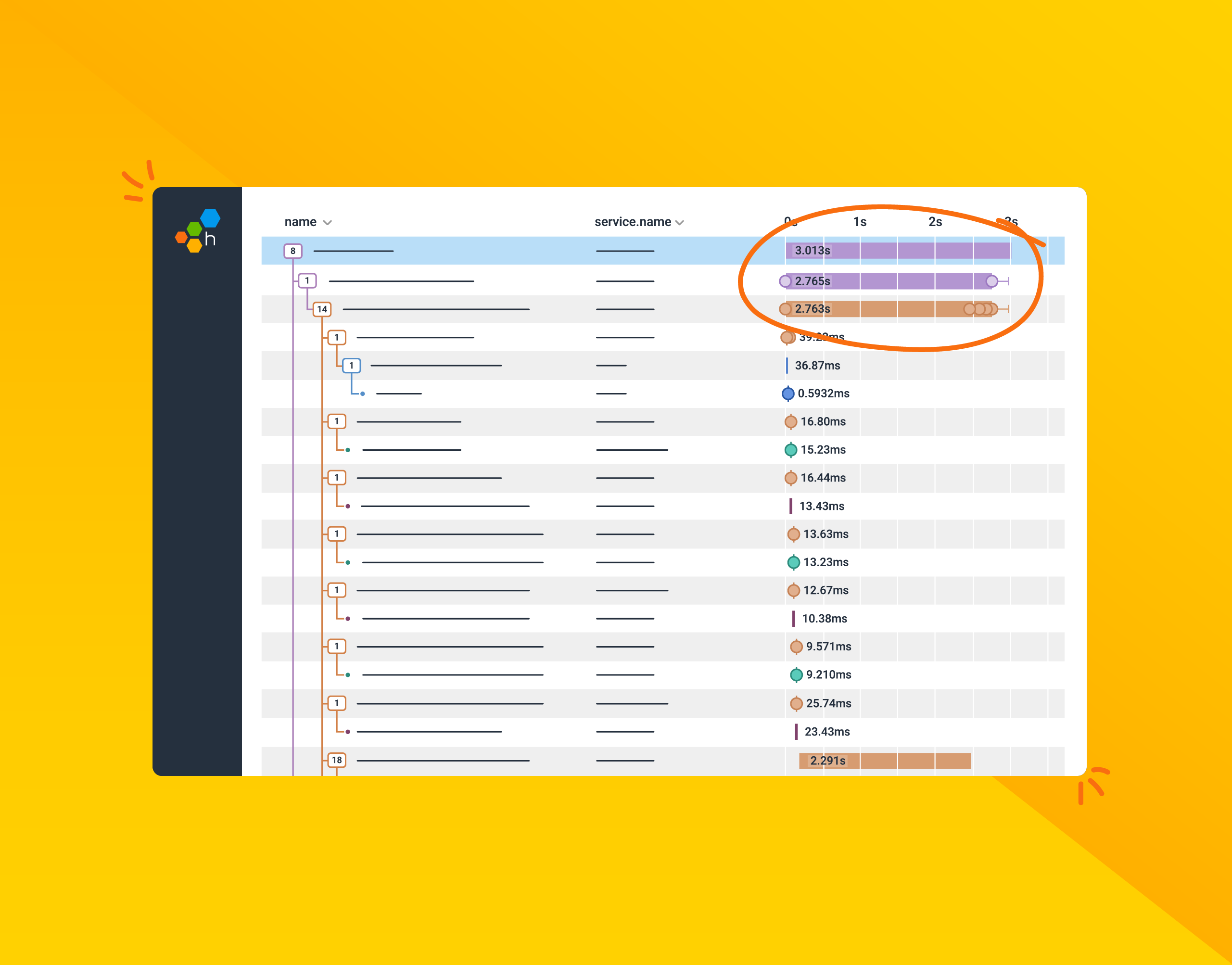
Distributed tracing enables you to monitor and observe requests as they flow through your distributed systems to understand whether these requests are behaving properly. You can compare tiny differences between multiple traces coming through your microservices-based applications every day to pinpoint areas that are affecting performance. As a result, debugging and troubleshooting are simpler and faster. No one has to guess or spend countless hours researching possible causes for issues, like you would if traditional logging methods were your only resource.
Rebecca Carter | Feb 24, 2023
Imagine a universe in which a massively multiplayer online role-playing game (MMORPG) sets Guinness World Records for the size of its online space battles—and that game is built on 20-year-old code. Well, imagine no more. Welcome to the world of EVE Online, where hundreds of thousands of players interact across 7,800+ star systems and participate in more than one million daily market transactions. As you might guess, updating and maintaining this codebase without interrupting game play could pose quite a challenge.
Rebecca Carter | Feb 23, 2023
Growing pains can be a natural consequence of meteoric success. We were reminded of that in our recent panel discussion with SumUp’s observability engineering lead, Blake Irvin, and senior software engineer Matouš Dzivjak. They shared how SumUp’s rapid growth spurt compelled them to change their resolution process—both logistically and culturally—to ensure a service level quality that reflects their customer obsession.
Fred Hebert | Feb 21, 2023
When I joined Honeycomb two years ago, we were entering a phase of growth where we could no longer expect to have the time to prevent or fix all issues before things got bad. All the early parts of the system needed to scale, but we would not have the bandwidth to tackle some of them graciously. We’d have to choose some fires to fight, and some to let burn.
Jessica McElroy | Feb 17, 2023
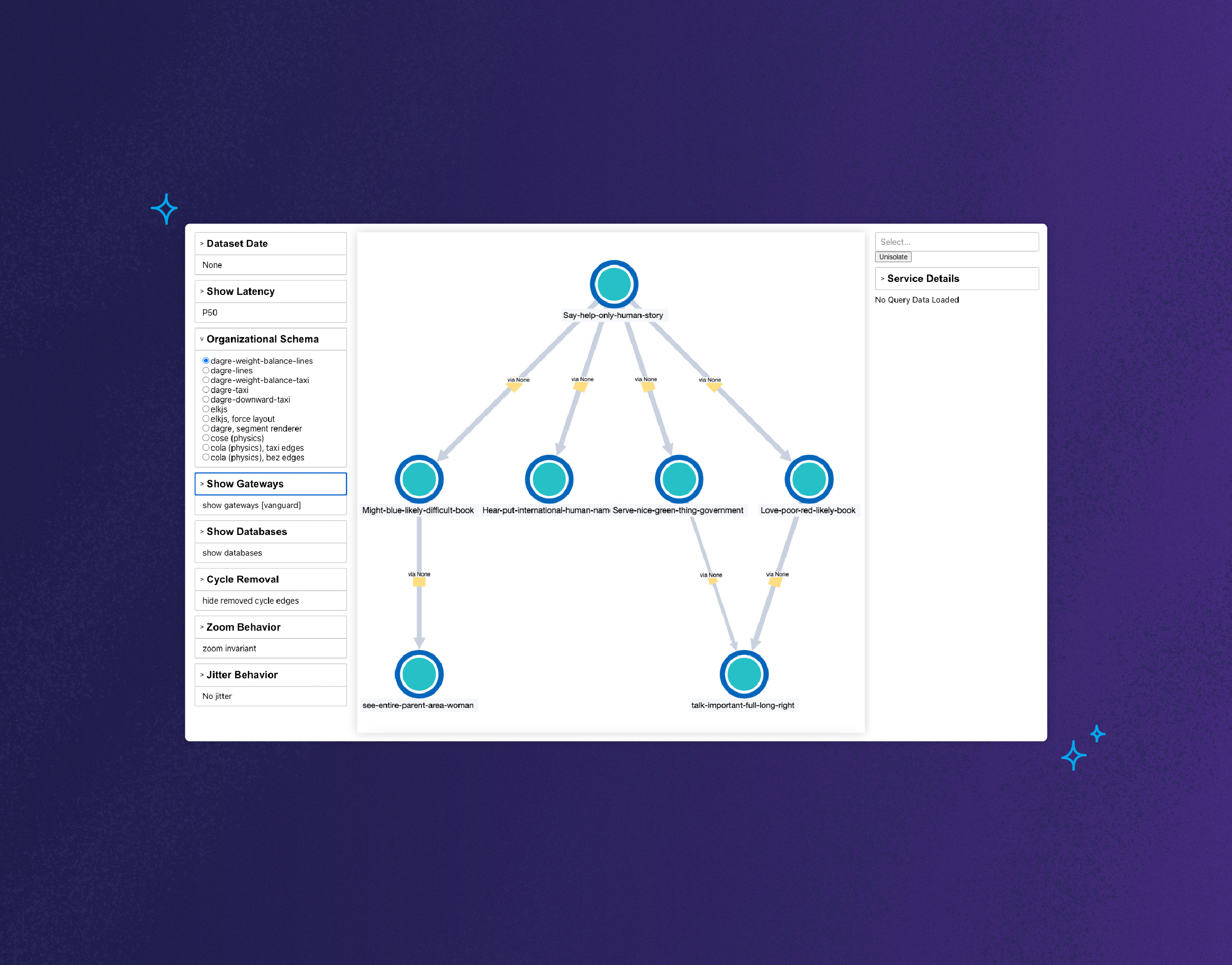
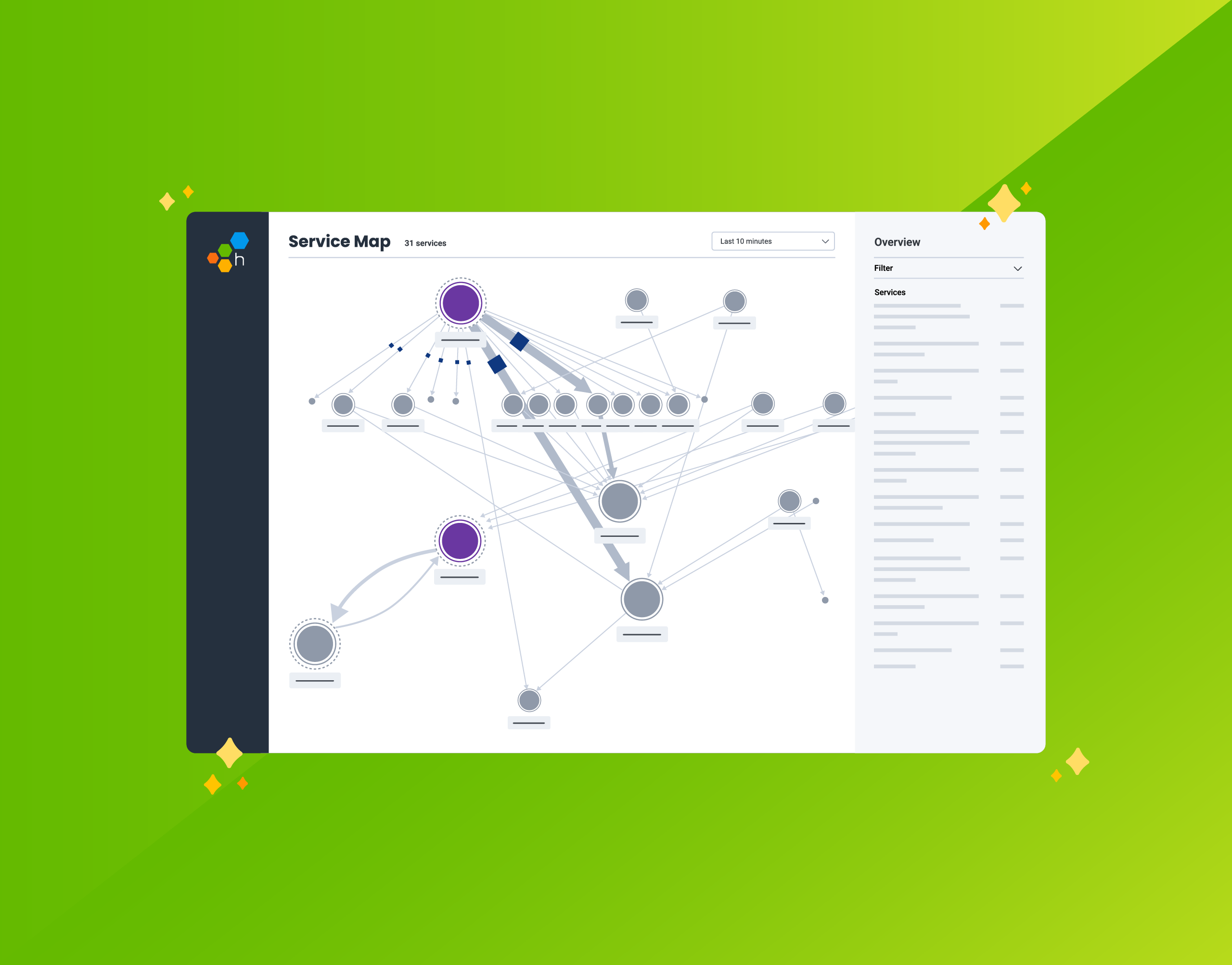
For a long time at Honeycomb, we envisioned using the tracing data you send us to generate a service map. If you’re unfamiliar, a service map is a graph-like visualization of your system architecture that shows all of its components and dependencies. We didn’t want it to be a static service map, though—the kind you’d view once before going “huh, neat”—and then never looking at it again. We wanted to build an actually useful, uniquely Honeycomb-y service map that could become an integral part of your team’s observability workflow.
Alyson | Feb 15, 2023
In January 2022, Honeycomb kicked off a one year experiment to have an employee sit as a voting board member on the board of directors. I became that board member in July 2022. As the experiment comes to a close, I want to share some of my reflections.
Valerie Silverthorne | Feb 08, 2023
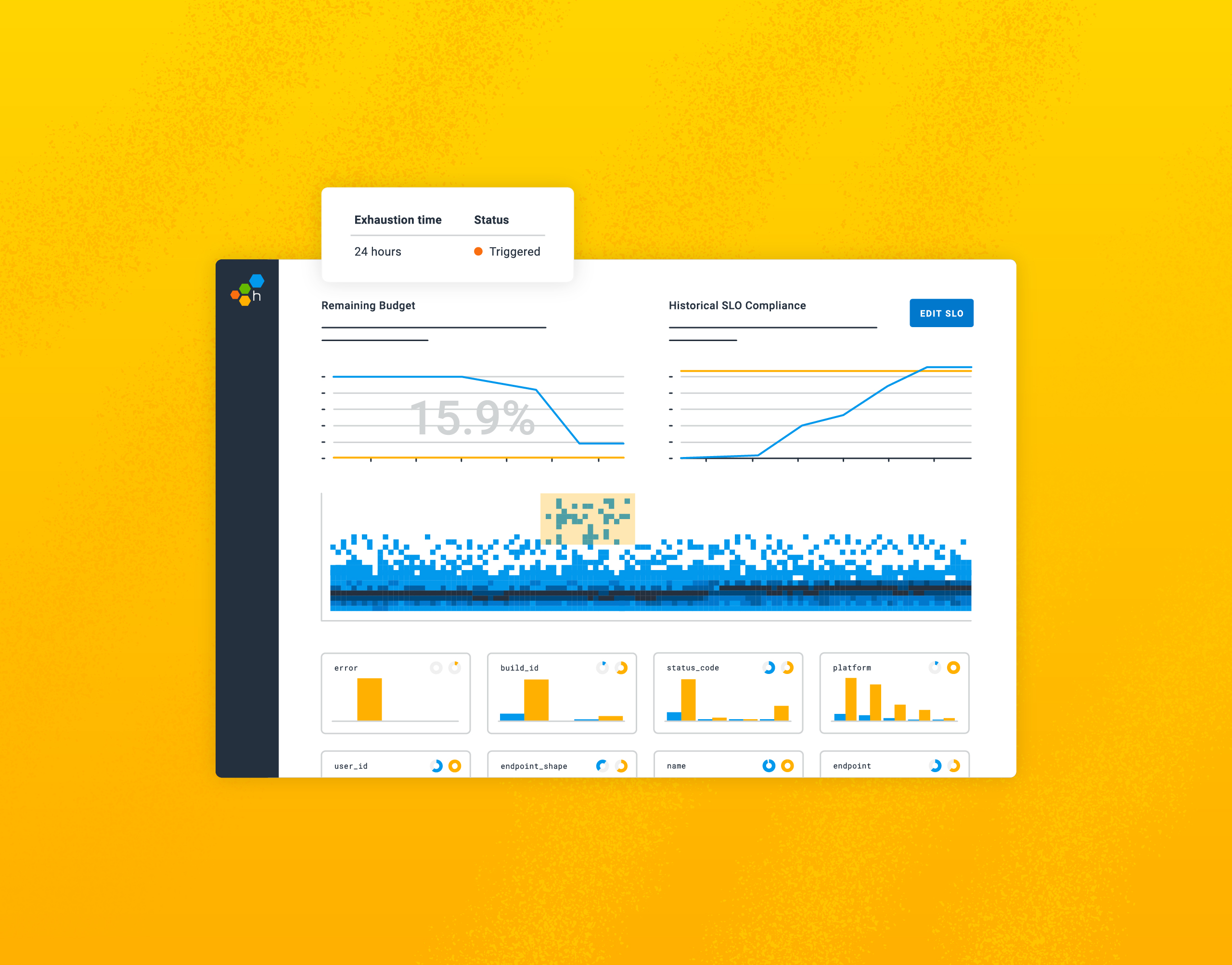
With one key practice, it’s possible to help your engineers sleep more, reduce friction between engineering and management, and simplify your monitoring to save money. No, really. We’re here to make the case that setting service level objectives (SLOs) is the game changer your team has been looking for.
Rebecca Carter | Feb 06, 2023
Honeycomb’s Service Map gives you the unique capability to filter by both services and traces so you can generate maps that isolate very specific areas of your environment. This helps you surface issues quickly and gain a granular understanding of how everything in your system works and evolves over time. And now that a Service Map scenario is available in our Sandbox, you can see it for yourself.
Nick Travaglini | Feb 02, 2023
When an organization signs up for Honeycomb at the Enterprise account level, part of their support package is an assigned Technical Customer Success Manager. As one of these TCSMs, part of my responsibilities is helping a central observability team develop a strategy to help their colleagues learn how to make use of the product. At a minimum, this means making sure that they can log in, that relevant data is available, that they receive training on how to query, and perhaps that they collaborate with the rest of Honeycomb’s CS department to solve problems as they arise.
Sarrah Vesselov | Jan 31, 2023
Over the past few months, we've been hard at work modernizing Honeycomb’s data visualizations to address consistency issues, confusing displays, access to settings, and to improve their overall look and feel.
Michael Wilde | Jan 26, 2023
Incidents happen. What matters is how they’re handled. Most organizations have a strategy in place that starts with log searches—and logs/log searching are great, but log searching is also incredibly time consuming. Today, the goal is to get safer software out the door faster, and that means issues need to be discovered and resolved in the most efficient way possible.