Get all your observability data in one unified platform with limitless possibilities.
Discover why Honeycomb is the better choice for your engineers, your customers, and your bottom line.
Explore our latest blogs, guides, training videos, and more.
Give all software engineering teams the observability they need to eliminate toil and delight their users.
Rynn Mancuso | Mar 20, 2023
The open source community talks a lot about the problem of aligning incentives. If you’re not familiar with the discourse, most of this conversation so far has centered around the most classic model of open source: the solo unpaid developer who maintains a tiny but essential library that’s holding up half the internet. For example, Denis Pushkarev, the solo maintainer of popular JavaScript library core-js, announced that he can’t continue if he’s not better compensated.
Fred Hebert | Mar 16, 2023
The SRE team is now four engineers and a manager, and we are involved in all sorts of things across the organization, across all sorts of spheres. We are embedded in teams and we handle training, vendor management, capacity planning, cluster updates, tooling, and so on. After growing the team to a point where we could get a better grasp on our mission and identity, we decided to revisit our charter. It is a living document after all, and it was exciting for me to let other folks get their hands in it.
Nick Rycar | Mar 14, 2023
It’s been a minute since our last Feature Focus, and we have a bit of catching up to do! I’m happy to report we’ll resume monthly updates next month, but until then, please enjoy this super-sized winter digest of what we’ve been up to at Honeycomb.
Charity Majors | Mar 13, 2023
Rebecca Carter | Mar 10, 2023
When you’re just getting started with observability, a proof of concept (POC) can be exactly what you need to see the positive impact of this shift right away. Coveo, an intelligent search platform that uses AI to personalize customer interactions, used a successful POC to jumpstart its Honeycomb observability journey—which has grown to include 10,000+ machine learning models in production at any one time.
Jessica Kerr | Mar 09, 2023
Your API Key (in the x-honeycomb-team header) tells Honeycomb where to put your data. It specifies a team and an environment. Then, Honeycomb figures out which dataset to put each event in, based on the service.name field in the event. Except…
Jessica Kerr | Mar 07, 2023
When we work at it, professionals are pretty good at analysis. We can break down a simple system, look at its parts and their relations, and master it. Given enough time and teammates, we can analyze a very complicated system and fix it when it breaks. But complex systems don’t yield to analysis. We have to add another skill: sense-making.
Martin Thwaites | Mar 03, 2023
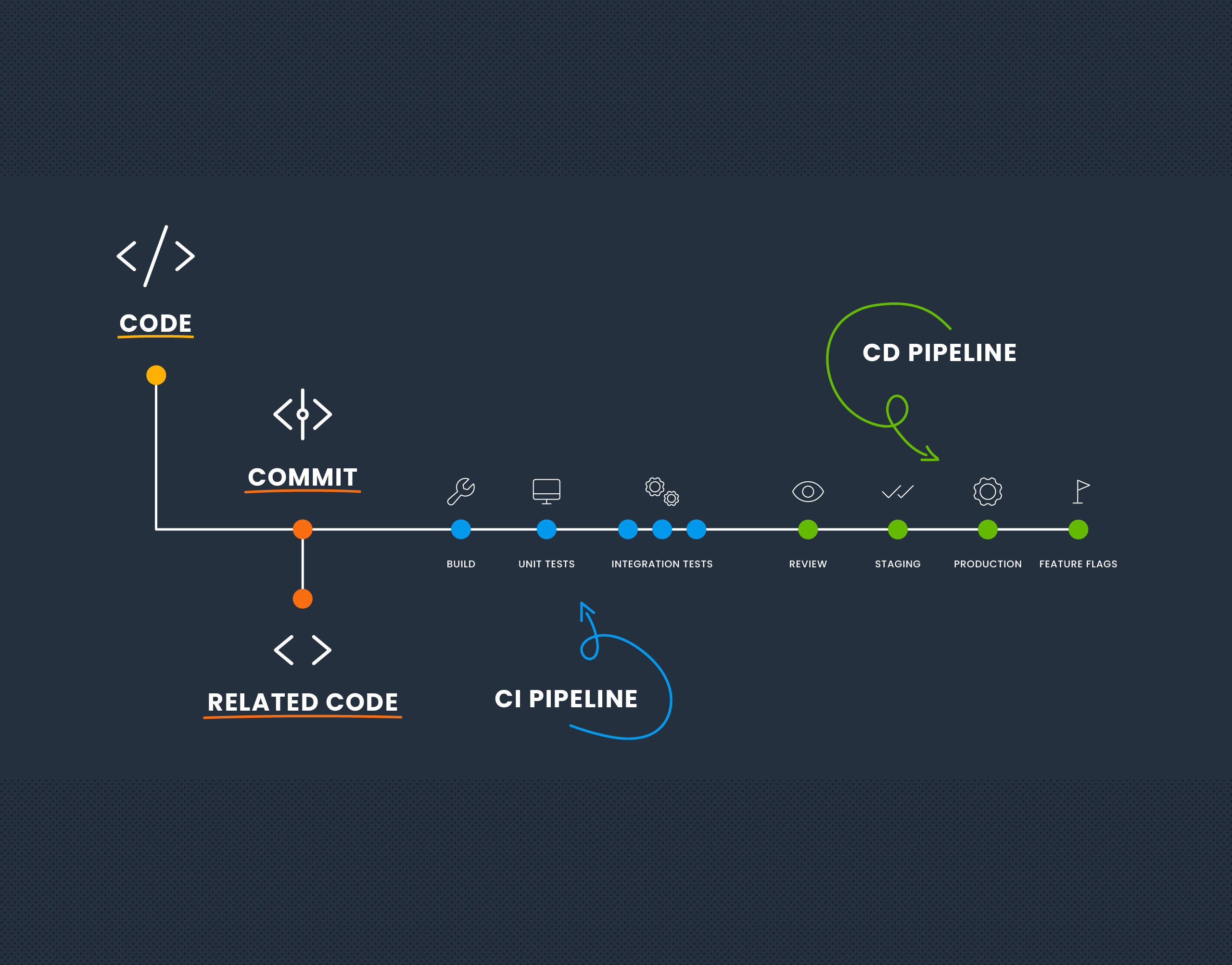
So you're used to debugging systems using a distributed trace, but your system is about to introduce a message queue—and that will work the same… right? Unfortunately, in a lot of implementations, this isn't the case. In this post, we'll talk about trace propagation (manual and OpenTelemetry), W3C tracing, and also where a trace might start and finish.
Rebecca Carter | Mar 01, 2023
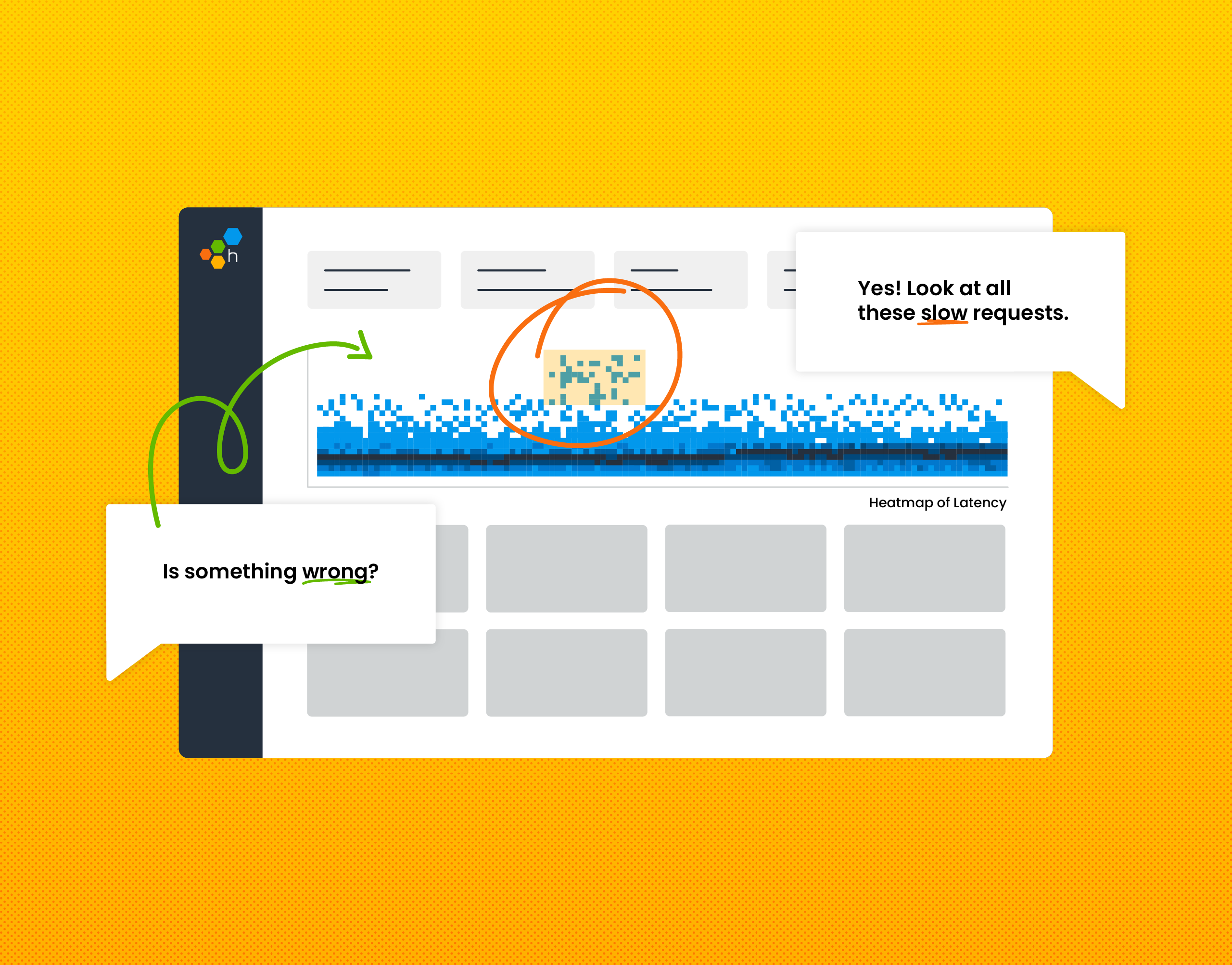
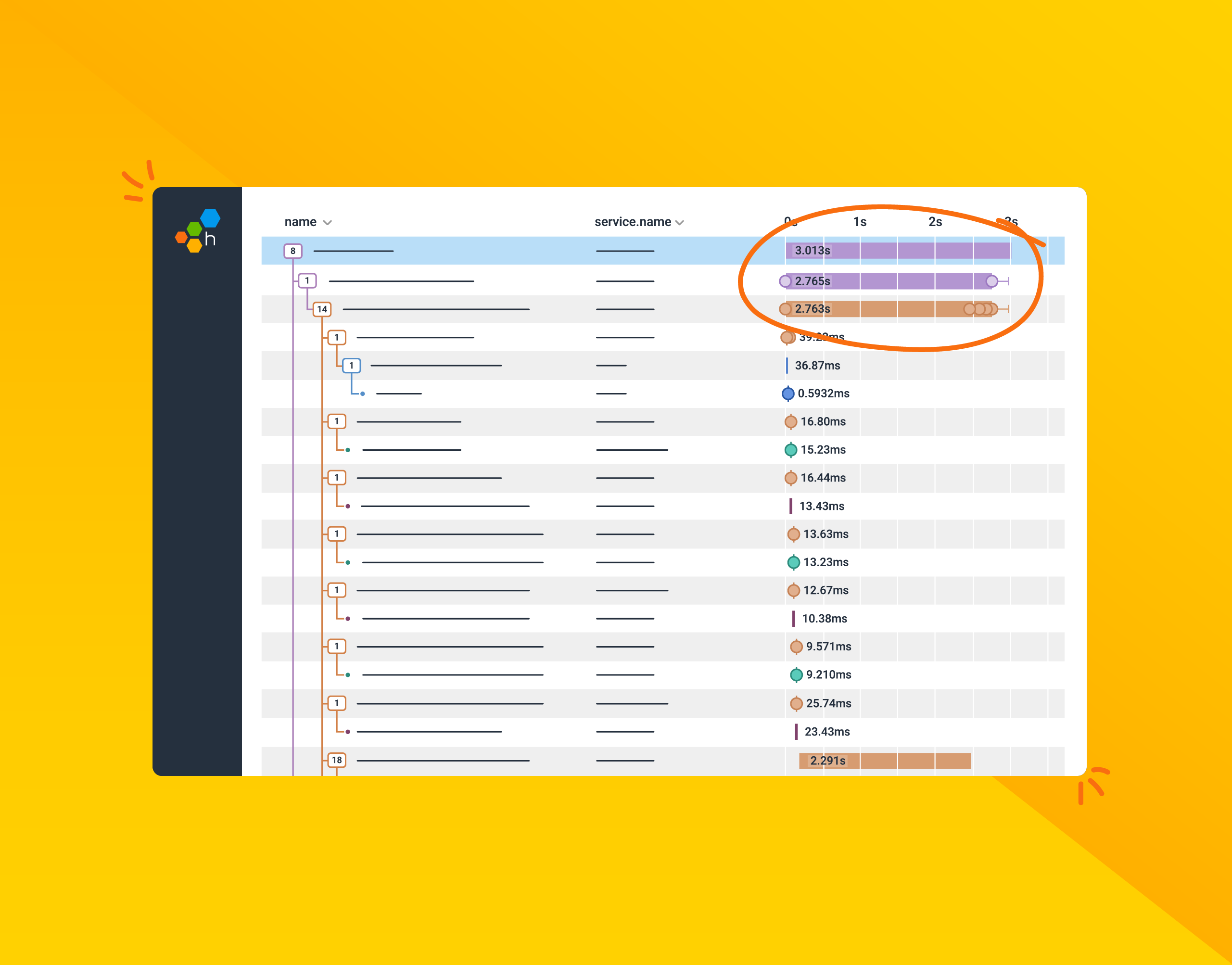
Distributed tracing enables you to monitor and observe requests as they flow through your distributed systems to understand whether these requests are behaving properly. You can compare tiny differences between multiple traces coming through your microservices-based applications every day to pinpoint areas that are affecting performance. As a result, debugging and troubleshooting are simpler and faster. No one has to guess or spend countless hours researching possible causes for issues, like you would if traditional logging methods were your only resource.
Rebecca Carter | Feb 24, 2023
Imagine a universe in which a massively multiplayer online role-playing game (MMORPG) sets Guinness World Records for the size of its online space battles—and that game is built on 20-year-old code. Well, imagine no more. Welcome to the world of EVE Online, where hundreds of thousands of players interact across 7,800+ star systems and participate in more than one million daily market transactions. As you might guess, updating and maintaining this codebase without interrupting game play could pose quite a challenge.
Rebecca Carter | Feb 23, 2023
Growing pains can be a natural consequence of meteoric success. We were reminded of that in our recent panel discussion with SumUp’s observability engineering lead, Blake Irvin, and senior software engineer Matouš Dzivjak. They shared how SumUp’s rapid growth spurt compelled them to change their resolution process—both logistically and culturally—to ensure a service level quality that reflects their customer obsession.
Fred Hebert | Feb 21, 2023
When I joined Honeycomb two years ago, we were entering a phase of growth where we could no longer expect to have the time to prevent or fix all issues before things got bad. All the early parts of the system needed to scale, but we would not have the bandwidth to tackle some of them graciously. We’d have to choose some fires to fight, and some to let burn.