

See how Honeycomb manages incident response.
Back in Alerts Are Fundamentally Messy, I made the point that the events we monitor are often fuzzy and uncertain. To make a distinction between what is valid or invalid as an event, context is needed, and since context doesn’t tend to exist within a metric, humans go around and validate alerts to add it. As such, humans are part of the alerting loop, and alerts can be framed as devices used to redirect our attention.
In this post, I want to drive this concept a bit further. Rather than focusing the thinking on the events that result in alerts, I want to switch the lens with which we look at the system and center it on the operators who get the message, and on how we can restructure our alerting to play these roles better.
What people do with a signal
A very common pattern I’ve seen in the industry is one where we attempt to make the loop as narrow as possible: the alert contains indications of what to do to fix the problem. I think this is misguided, and to illustrate why, we need to introduce a few distinctions between concepts:
- An alarm or an alert:
- Is a signal that tells you about something or some condition
- Mainly asks to redirect your attention, usually through a sound and/or visual cue that interrupts you
- Anomaly detection:
- Is an agent or automated mechanism that notices something in the data is odd
- Is based in a concept of normalcy or correctness, where expectations aren’t being met
- Fault identification:
- Is about knowing that a specific thing is broken
- Can also be that the specific thing is broken in a particular way
- Corrective actions:
- Are specific actions required to correct a situation
- Can be considered exploratory, where a fix is attempted, and the outcome provides new information about the system
The risk in designing alerts to also contain corrective actions is that they tie the attention redirection to a conclusion that suggests direct action. This means that we are implicitly very certain of an anomaly existing, of the fault being properly identified, and of the corrective action being safe and adequate.
You know what they say when you assume…
That’s a really big assumption to make in many cases. When it is pushed to extremes, we start creating one alarm per potential corrective action to make alert handling as friendly (and mindless!) as possible.
The operator in the midst of all these “helpful” alerts and diagnoses has to interpret them properly in their own sense-making loop, a big mess that looks a bit like this:
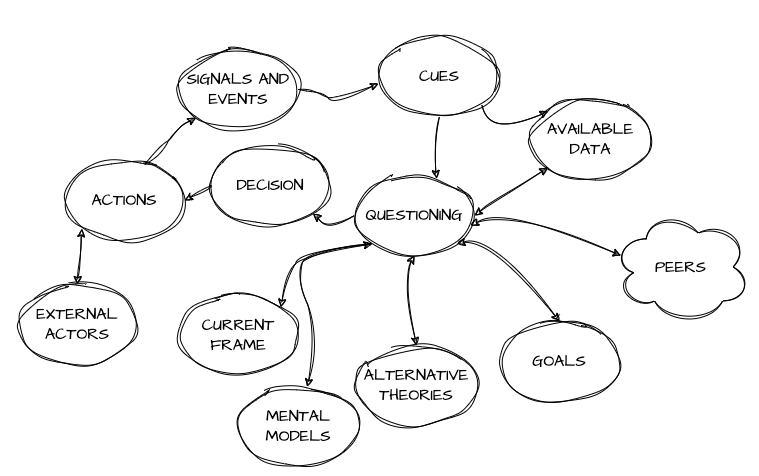
There are various theories and models of how decision-making and sense-making work, but the above diagram shows some of the things that need to happen under time pressure and partial information.
Alert signals (“signals and events”) that do not leave any room for activities other than “decisions” or “actions” may create extra burden at the “questioning” step if they don’t shortcircuit the loop altogether and go from action to awaiting further signals—acting without taking the time to assess the situation and think—often couched in one specific frame and model of the world that may not even be accurate.
Another misguided element here is assuming that each signal means only one thing, which omits possibly interconnected issues. This is called common mode failures, meaning a shared element acts unexpectedly and causes other elements to misbehave in turn.
An alternative representation could look like the following diagram:
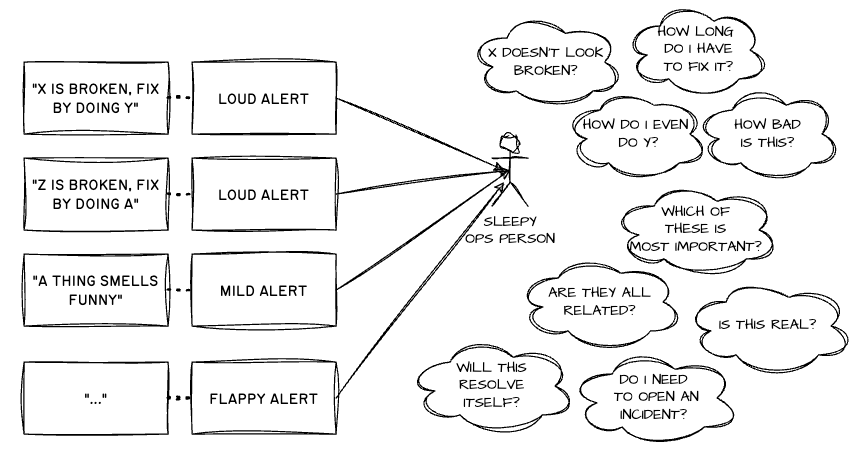
To put it another way, the idea of specific alerts leading to unambiguous “root causes” may lead to noisy systems that are less clear and more demanding to handle than what you could get with a more solid catering to distinct concepts of alarms, anomalies, faults, and corrective actions.
How do I put this in practice?
In a nutshell, when designing an alert, you want to keep in mind these more practical elements:
- More event volume means better likelihood of finding a real problem. Alerts based on rare events are often noisy and flappy.
- If you don’t have enough traffic, you need to be more tolerant of failures, or generate artificial (but ideally representative) traffic.
- Alerts should have various levels of noisiness based on certainty and intensity.
- More alerts possibly firing all at once make it harder to know what happened and what needs sorting.
- Fewer alerts might be desirable, even if each is a bit less clear about the anomaly or fault it might be related to, because people will need to investigate it regardless.
- The alert must be informative, even when just getting the mobile notifications; the less attention it requires to understand what it’s about (different from “what needs doing”), the better.Assume people will need to validate whether the alert is true or not—regardless of what happens.
- Alerts ultimately demand a response or an action. Any signal they raise must be in the service of driving proper action at the proper time.
- Preventive alerts (“State X is maybe worrisome and could get much worse later”) need to have enough of a lead time to let you prioritize and act on them. They don’t need to be loud unless things are already bad.
- Context is important and usually unknown at alert design time, so state facts rather than interpretations (“response time or errors too high” rather than “we are being overloaded by too much traffic and someone might be DDoSing us!”).
Since context is shifting, we should feel confident in tweaking and adjusting alerts to match varying demands based on the actions we believe will be needed. The alarms are here to serve us, not the other way around.
In terms specific to Honeycomb, for alerts using triggers and Service Level Objectives (SLOs):
- Make broader, but vaguer SLOs rather than many small and precise SLOs if you can. A longer budget (e.g., 30 days) is better than a shorter budget (e.g., seven days) because it reduces the noisiness of specific time periods, such as slow weekends.
- Be careful with data distribution; if you monitor 40 endpoints and a single one of them does 95% of traffic volume, you may need two SLOs to separate all noise accurately.
- Make your SLO count errors and bad performance at the same time.
- Triggers can be made more descriptive without losing manageability by using
GROUP BYorCOUNT_DISTINCT.GROUP BYcan help you know how many things are impacted (number of endpoints, partitions, users) and display them in the alert.COUNT_DISTINCTcan let you know how many things are impacted while eitherWHEREorHAVINGclauses can define what the impact is (e.g., let me know when at leastNteams have slow queries).
- Delete, silence, and/or rework signals nobody cares about or communicate no useful information.
- “Just in case” alerts need to go to a low distraction place so they don’t overload someone handling other alerts already.
- Keep runbooks short and to-the-point (“optimized for the sleepy on-caller”).
- How bad is this and how long do I have?
- What are usual things to try and what do I do if they don’t work?
- It’s okay to go, “This is usually bad news, start an incident, escalate, and think of resolving later.”
- Architecture background that may be useful but should be read before being on-call goes either in a different doc or in a clearly labeled section.
- If you’re designing an SLO for on-call people, use burn rate alerts to avoid ever needing to remember to reset it to get new alerts.
- Pick a shorter burn window on a longer budget window to get better signal, and quicker alert resets. Counter-intuitively, longer burn windows are more sensitive than shorter burn windows because they have more events available to find the same failure count!
- If you don’t know how to pick a budget:
- Assume right now is fine and make sure you have 30% left then reevaluate over time.
- Pick a strict value and make it non-paging. The SLO is now in calibration mode. Every time it fires, ask: “Did I need to be paged for this?” and if not, relax it.
- From time to time, review it and ask: “Should I have been paged at any point here?” (e.g., when users point out an issue we didn’t catch) and figure out if you need to make it stricter.
- If you can’t meet a budget and can’t fix it within the realm of on-call:
- Start a discussion across engineering, customer success, support, product, or whatever teams have a stake in product quality. Ask what priorities we need to shift, and how this needs to be communicated.
The key value of an alert is that it provokes the right reaction and adjustment for the situation at hand. This involves not just the reaction and immediate technical issue, but also relevant situational context that must be understood.
Evolve practices; affect change
These are the general principles and suggestions I push here at Honeycomb. If you’re interested to find more approaches we use to re-structure our incident response to better cater to problem solving, take a look at how we mostly got rid of incident severities and instead switched to incident types.





