Slicing Up—and Iterating on—SLOs
One of the main pieces of advice about Service Level Objectives (SLOs) is that they should focus on the user experience. Invariably, this leads to people further down the stack asking, “But how do I make my work fit the users?”—to which the answer is to redefine what we mean by “user.” In the end, a user is anyone who uses whatever it is you’re measuring.

By: Fred Hebert

The Engineer’s Guide to Service Level Objectives (SLOs)
Learn MoreOne of the main pieces of advice about Service Level Objectives (SLOs) is that they should focus on the user experience. Invariably, this leads to people further down the stack asking, “But how do I make my work fit the users?”—to which the answer is to redefine what we mean by “user.” In the end, a user is anyone who uses whatever it is you’re measuring.
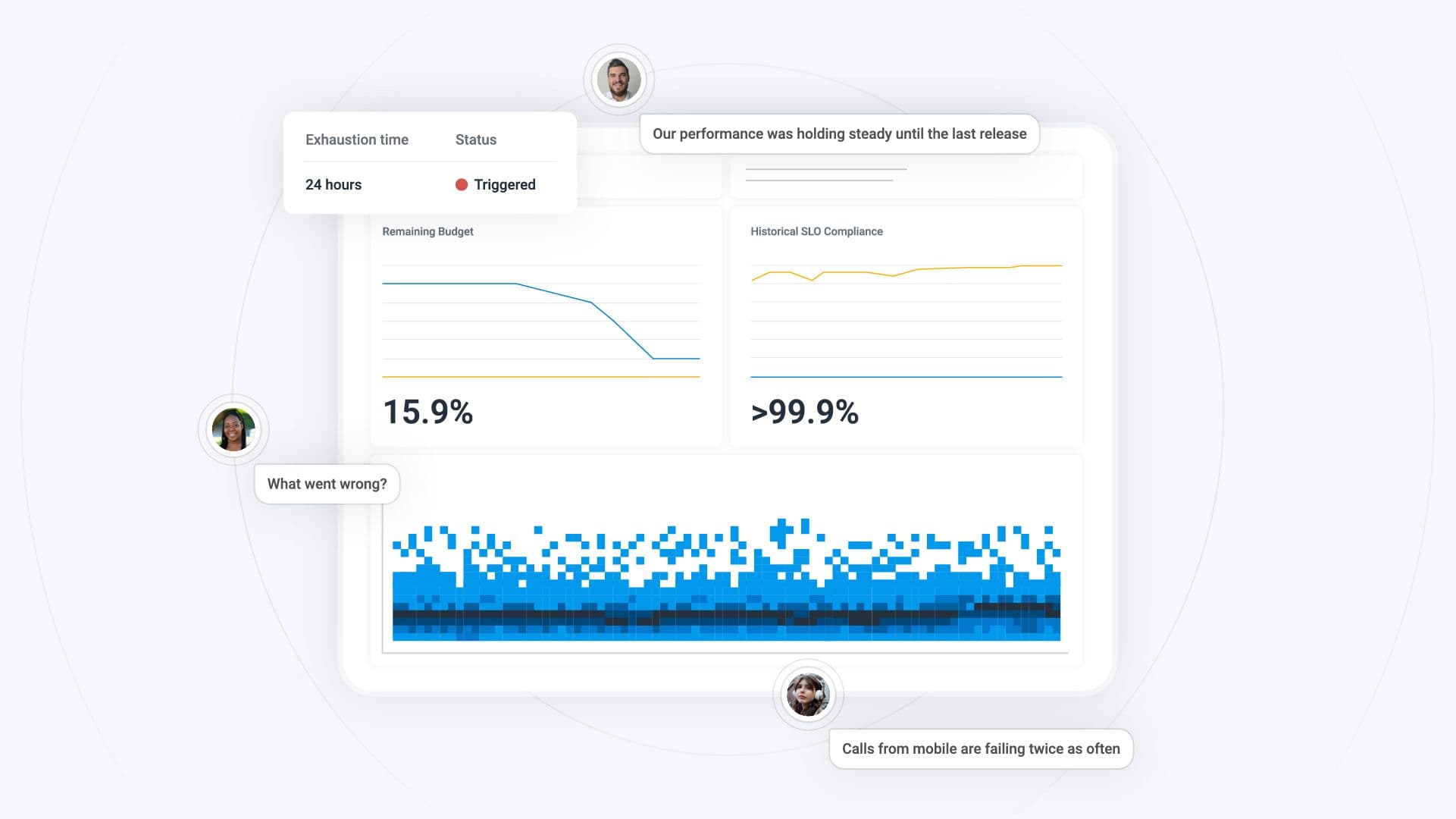
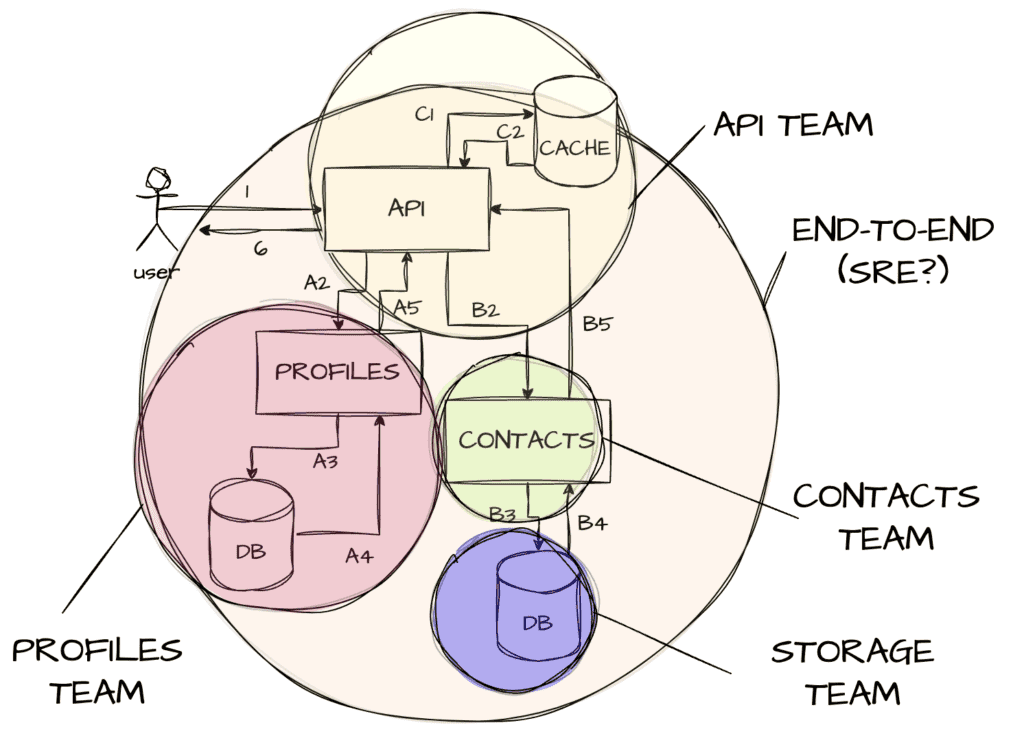
This leads to a funny situation where if everyone uses SLOs, you inadvertently cover some core components multiple times:
While this is a great way to identify critical components, it’s also an alertful way of showing who might be responsible for service quality they can’t impact. If the contacts DB goes down, at least three teams may be alerted.
I’m going to define two approaches to cope with this: defining defensive patterns, and cutting up responsibility.
Defining defensive patterns
One of the amazing parts of engineering is the possibility to make something reliable out of unreliable parts—although, not in all cases.
If a component you depend on fails 0.5% of the time, calling it twice should statistically mean you only get 0.025% failures on both calls. Likewise, if a dependency is slow, caching strategies can drastically improve the response speed regardless of what the backend component does.
There’s also an overall question of composability: an SLO allowing 250ms of processing time for multiple API calls each taking 100-125ms will need to play with parallelism and combine them with any of the above strategies to ensure any likelihood of meeting targets.
At some point, though, you might find yourself unable to palliate issues with your own dependencies.
See how OneFootball proactively identified 45 incidents in 5 months using Honeycomb SLOs.
Cutting up responsibility
You’ll encounter SLOs that are more aspirational (for example, how good your service could be) rather than operational (for example, what it’s doing right now). It’s possible to be in a place where you can’t meet targets without changes to components—or, due to dependencies you don’t control.
To make sure your team isn’t constantly alerted for conditions it can’t correct, a useful approach can be based off of automated software testing. Start talking about unit vs integration SLOs.
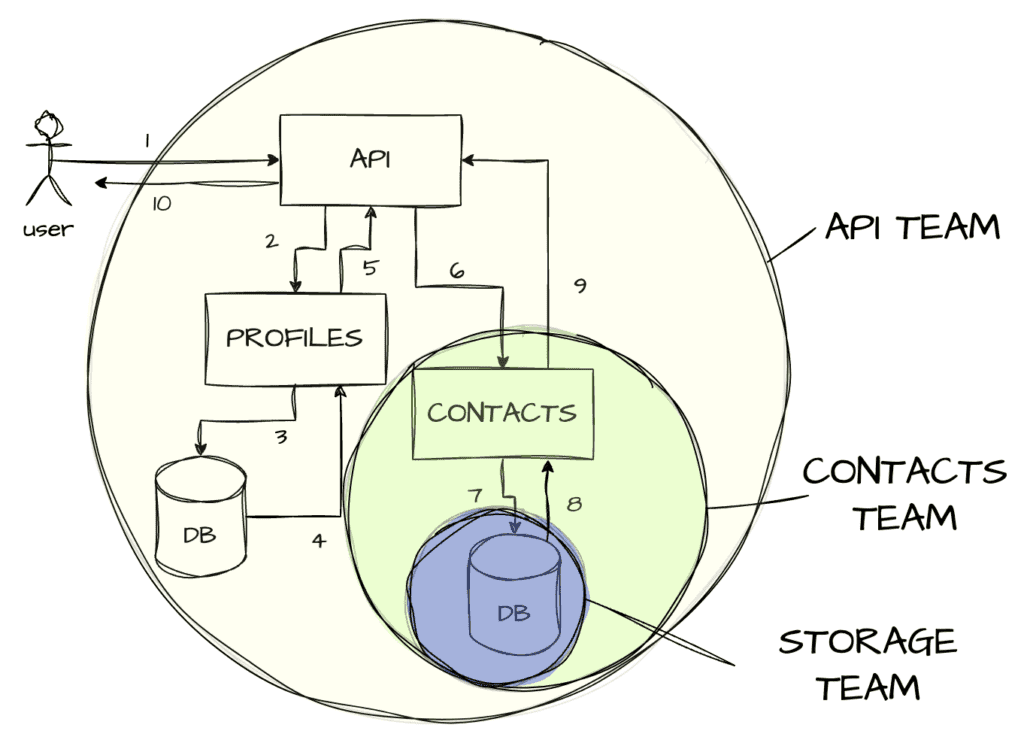
The idea is to have a few high-level, end-to-end SLOs that cover the overall workflow, and then sets of smaller, team-specific SLOs that let teams make sure they abide by their own contracts:
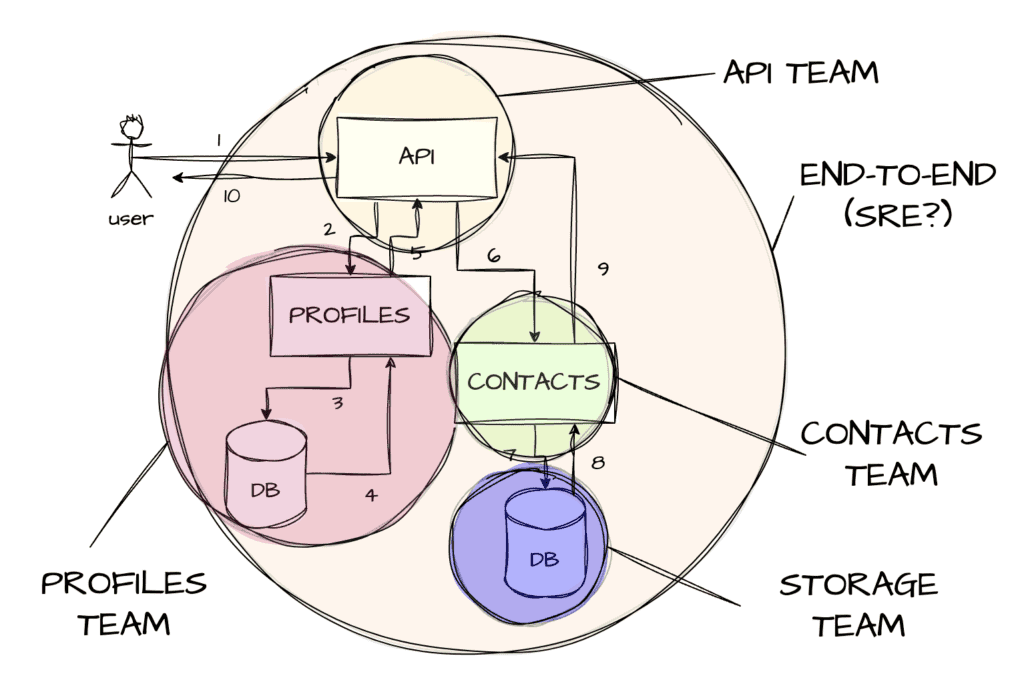
By discussing how to cut up responsibilities, each team can carve up subsets of the SLO for their own response times and overall success rates. Maybe the API gateway can lock up 50ms for its own performance, delegate 125ms to the profile service, and another 225ms to the contacts service. That way, everyone can fit within a 400ms budget.
The key elements to make this work are:
– Have an understanding of the end user’s desired experience.
– Avoid measuring the parts of the experience you can’t do anything about within your own team.
– Annotate instrumentation to identify which elements you do and don’t control.
With this data, you’ll be able to properly identify when you have to be involved or when you don’t because you’re just passing on errors. Plus, this way, a deep error can show up as customer-impacting without waking up teams in the middle. Alternatively, properly absorbing errors will protect other teams in turn.
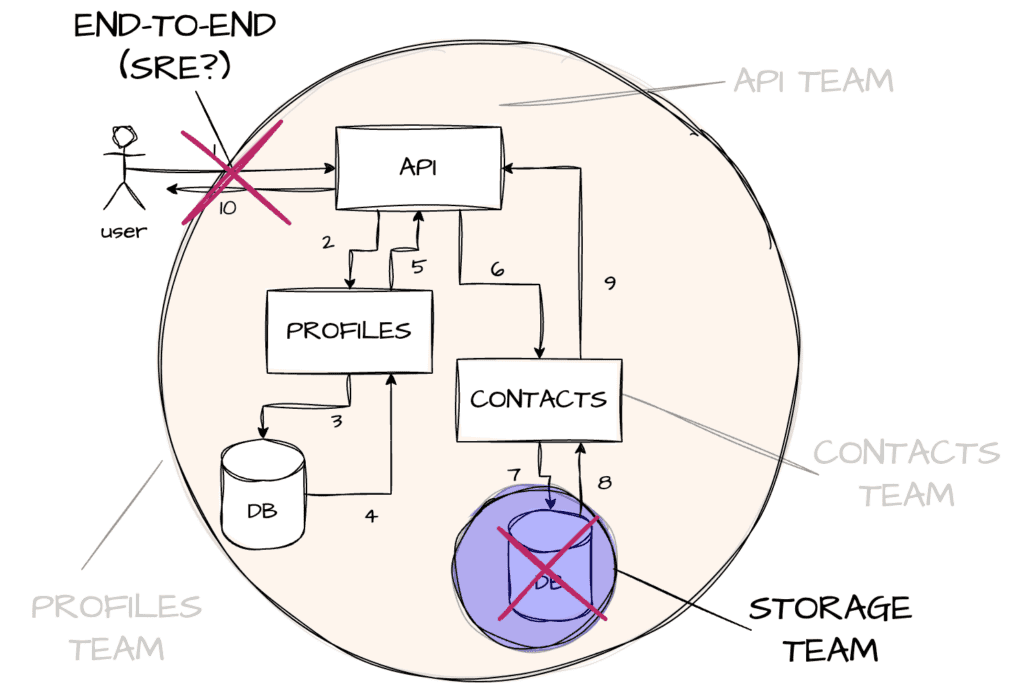
This sort of approach is likely to work as nicely for other teams internally, or third-party APIs you might be calling.
Helping each other help each other
We can also combine both approaches. It’s possible that by parallelizing calls to both services, the API can, within 50ms it already uses, make everything fit within 375ms (a 125ms reduction!). That’s enough time to possibly retry one profile call, but not a contacts one. But maybe, by negotiating an extra 5-10ms for the API, we can acceptably serve cached data for either. It might suddenly become tolerable for the other services to increase their speed requirements because the API lets them relax their reliability requirements.
Likewise, if you have lots of calls to make (such as loading the profiles of all contacts), you’ll be able to more accurately invest where it’s needed. For instance, reliability on the profile service might trump speed, because multiple parallel calls that succeed may be better than having retry rounds that slow down the overall flow.
Overall, while it is true that each team having their own alerts and that measuring at the user’s experience are both good ways to distribute reliability concerns through an organization, we should keep in mind that there are benefits to taking a more holistic (or systemic) view as well.
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.