Achieving Great Dynamic Sampling with Refinery
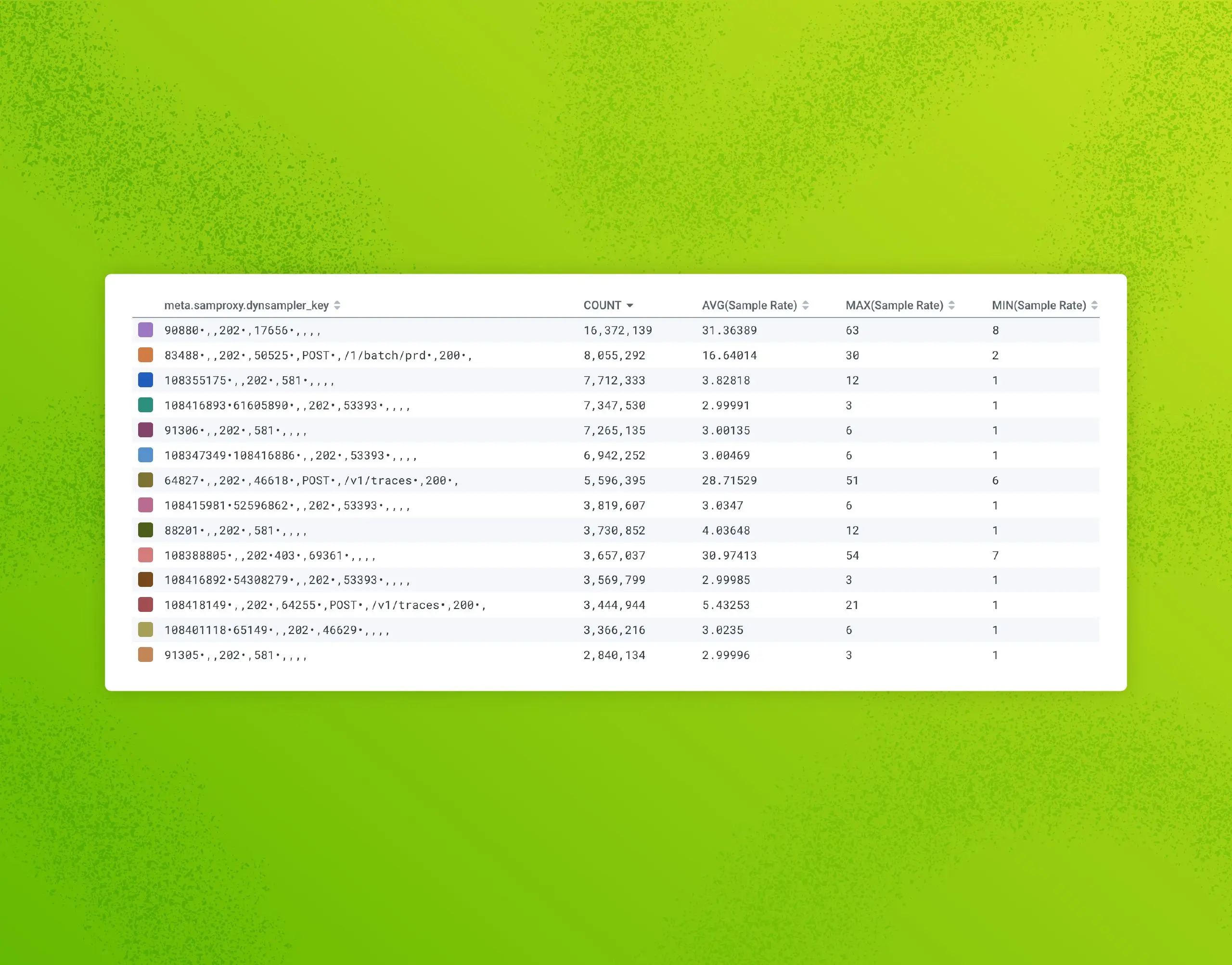
Refinery, Honeycomb’s tail-based dynamic sampling proxy, often makes sampling feel like magic. This applies especially to dynamic sampling, because it ensures that interesting and unique traffic is kept, while tossing out nearly-identical “boring” traffic. But like any sufficiently advanced technology, it can feel a bit counterintuitive to wield correctly, at first.