Understanding Your Telemetry Volume for Honeycomb
Understanding Your Telemetry Volume for Honeycomb
Understanding Your Telemetry Volume for Honeycomb
Table of contents
Whenever I’m talking to prospects, one of the most common questions is “how much will my telemetry data cost when I’m sending it to Honeycomb?” Understanding how pricing works and maintaining a good discipline in controlling the amount of telemetry data can be vital, especially when thinking about applying good observability across your enterprise.
In this article, I share some of the key aspects in better understanding and estimating your telemetry volume, and what that looks like in Honeycomb so that when you use or evaluate Honeycomb, you get a good idea of how much it may cost.
How does Honeycomb pricing work?
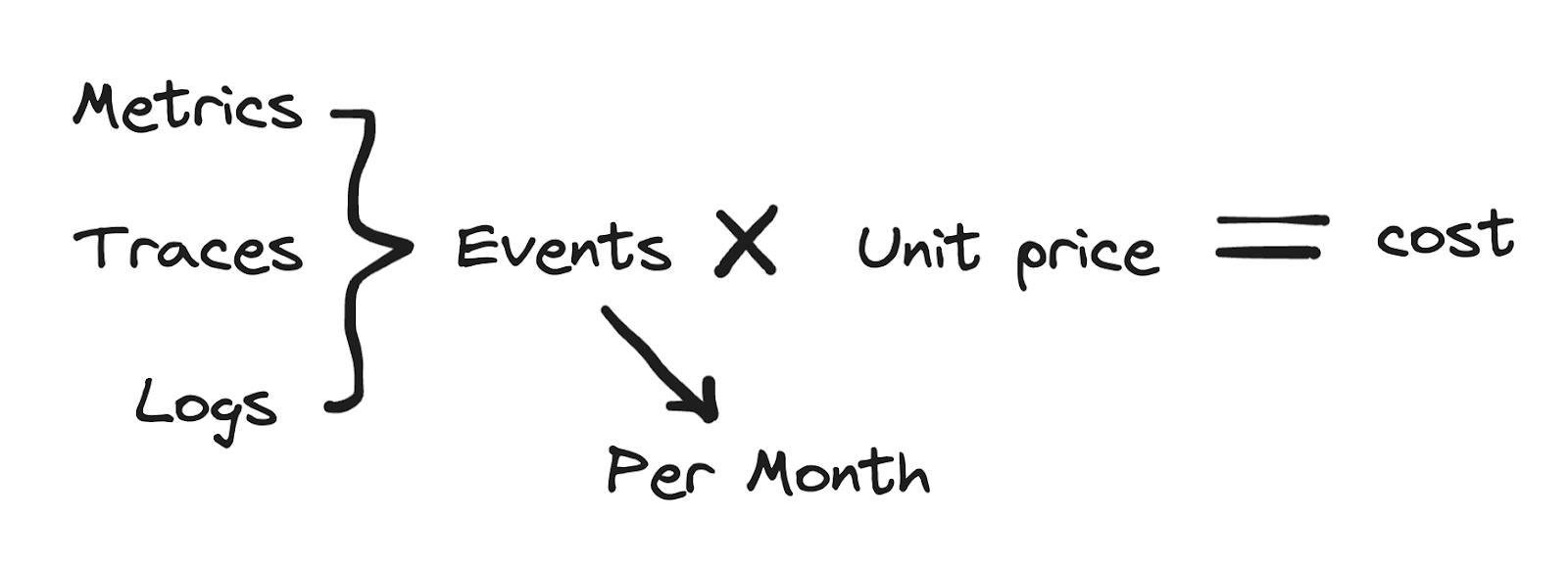
Honeycomb’s pricing is quite simple. We treat any telemetry data as ‘events,’ regardless of whether they are in the form of logs, metrics, or traces. Every month, we measure the amount of events, and your cost is the contracted unit price per event.
Metrics as events
A single metric telemetry point, for example system.cpu.utilization, is considered a single event.
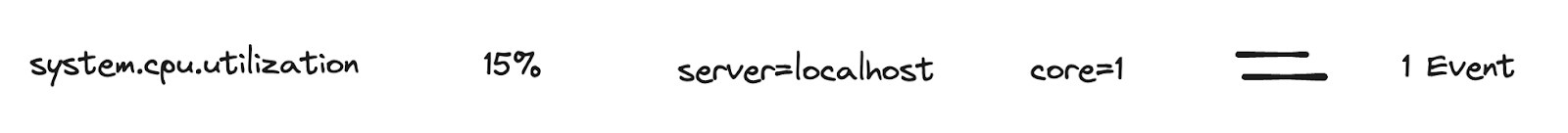
Traces as events
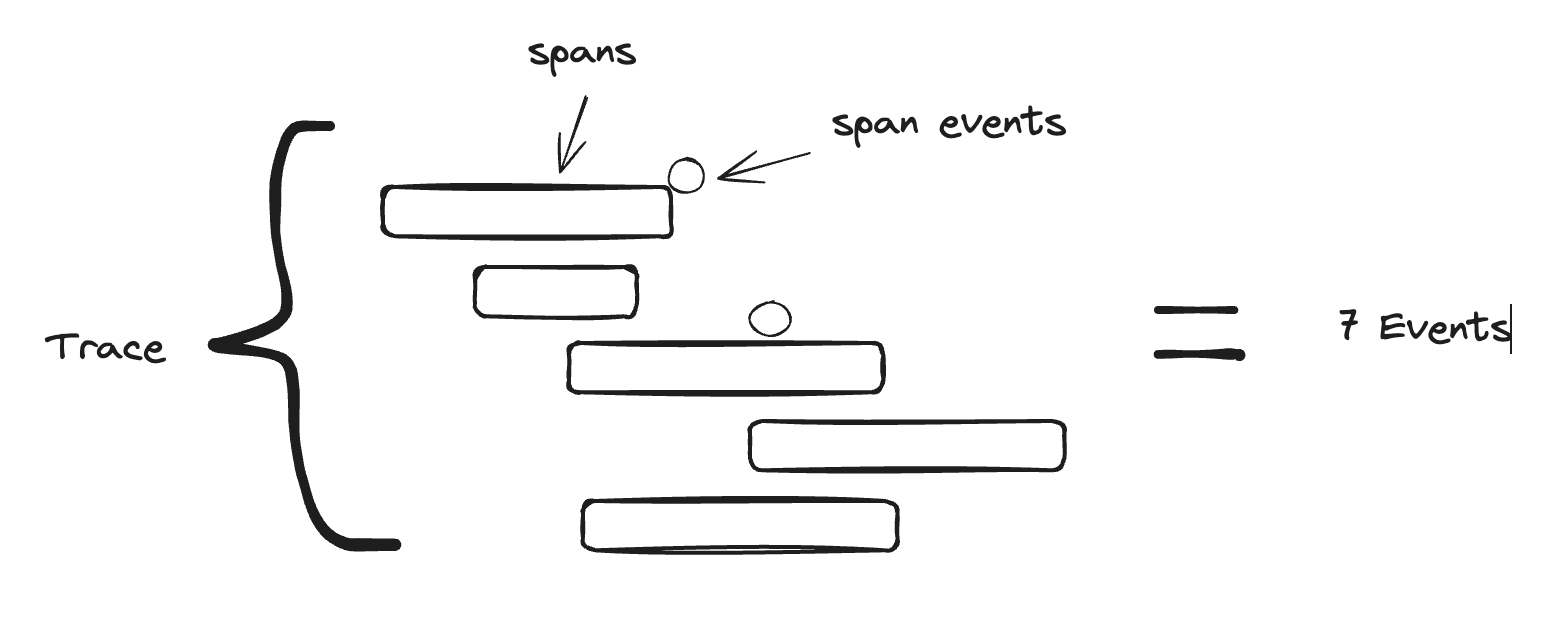
Traces have multiple spans, span events, and span links, right? How does that get treated? If a trace has 10 spans, span events, or span links, they are treated as 10 events.
Logs as events
A single log entry would equal a single event, similar to how a single metric data point equals to an event.

The pros and cons of events
Having a pricing model based purely on the number of events has many advantages:
- You can add your entire engineering organization to Honeycomb without worrying about incurring per-seat costs.
- It rewards curiosity. Query the data as often as you need to get answers.
- The pricing model is transparent and concise. When you use Honeycomb, you know exactly how much it’s going to cost you, no matter the number of sources, users, metric names, attributes, or log size. We only care about the number of events, period.
- Since we do not charge based on the number of attributes, nor the size of the payload, you can populate as many attributes that you want in a single event without worrying about cost overages!
- A single attribute in Honeycomb can store up to 64kb of data. Multiple lines of logs can be converted into a single event
However, event-based pricing isn’t perfect. Here are potential shortfalls:
- It may be hard to predict how many events are going to be generated, unless you can predict the future. Estimation can be tricky if you do not have a good awareness of how ‘many’ of these events are being generated.
- Trace data can be expensive, proportional to the number of spans inside it.
- If your current cost is based on number of users (seats), or amount of data (e.g. storage space), you may need to perform additional calculations to properly estimate it by converting them into a number of events.
How to better estimate events in Honeycomb
An estimation is an estimation, and no one can ever be correct about estimating a potential cost of something that is going to be used based on the future. That is unfortunately quite common across many monitoring tools out in the market. Not only that, what you estimated based on may not be static at all since in today’s world, applications are highly ephemeral, dynamic, scalable, and always changing. It is also common to see more systems getting added to the ingestion, through various business events like organizational changes, new service launches, mergers and acquisitions, etc.
We start by assessing how you currently spend money on collecting metrics, and use that as a basis to estimate the cost of redirecting everything that you collect into Honeycomb.
Metrics
Suppose that you have 10 servers, and in each server, you collect around 20 different time-series data (e.g., cpu, memory, disk I/O, network I/O, etc.) in a 60 second interval. If we take a naive approach, the calculation would be: 20 (metrics) x 1440 (minutes) x 10 (servers) = 288,000 events in a day. In a month, that would be 8,784,000 events (288,000 x 30.5).
Things to consider for Honeycomb
Honeycomb has a special feature where when it ingests metrics, based on the values of the data’s resource attributes, it combines individual time-series data together into a single event—if the timestamps are closely aligned with one second each.
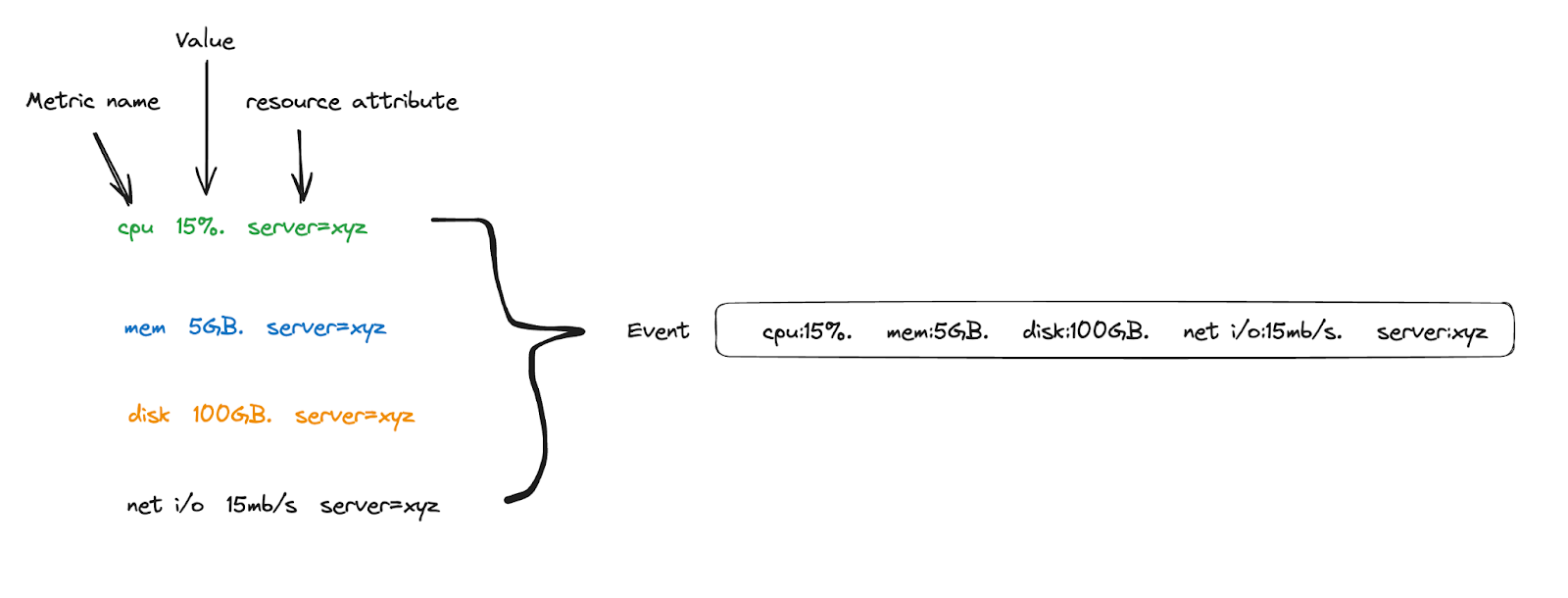
In this case, the actual number of events that is going to be generated is (10 x 1440 x 1) = 14400, which is 439,200 events per month—far less than expected. Therefore, it is generally a good idea to:
1) make sure your metrics intervals are conformed to a single time interval (e.g., 1m, 30s, etc.).
2) if those are all coming from the same resource, anticipate that they can be consolidated into a single event.
Logs
One thing to be aware of is that many logging solutions bill based on the amount of log entries, not individual entries. For example, they will have a price plan on retaining 100GB of logs per month instead of keeping 100 million log entries. That means that people may not know how many log entries are getting created, but rather how much. Also, log entries are not produced in intervals—rather, they are based on requests—so it may be harder to estimate how many entries will get produced.
According to the sources found in many log-related websites, the average size of a single log entry seems to be heuristically thought of as 200 bytes. Like I say, an estimation is an estimation, so if you know the amount of logs being generated, get the stored size and divide it by 200 bytes to ‘estimate’ into events.
Think outside the logs
When moving from log-centric monitoring to trace-based monitoring, there’s the potential to reduce the amount of logs you send. For example, let’s assume that developers have been writing five different log entries, such as service xyz started, service xyz is running, service xyz had an error, service xyz produced output, and ultimately service xyz is finished. If these logs can be re-instrumented as spans, those five log entries could be turned into a single span!
Traces
The cost of ingesting a trace is proportional to the number of spans it contains. One thing to note is that in case you use OpenTelemetry’s auto-instrumentation extensively to produce traces, log messages can be automatically converted into ‘span events’ and stored as part of the trace. It’s important not to estimate them in duplicates.
Traces are the data type that is hardest to estimate, as the number of spans is highly variable—even with the same service calls—as many factors can come into play.
Accounting for trace sampling
When ingesting traces, users should consider a head- or tail-based sampling strategy to make sure they don’t ingest highly repeated low-importance traces (like every success service calls that ran for 0.001s).
But how much should you be sampling the data, and at which rate? One out of five? Ten out of 50? Or even 50 out of 100? That may be the hardest question to answer, and the correct response is “it depends.”
When trialing Honeycomb, we generally use a table of historically collected ‘sampling trends’ to base our initial sampling estimation. Yes, an estimation is an estimation, but estimations based on historical trends are straight out of actual use cases and generally more accurate.
Think about the average over seven days, not an hour
If you have an existing measurement on how many events (e.g., log entries, requests, etc.) are occurring, make sure to measure for at least seven days. When I monitor for patterns, many operations do have a weekly pattern (weekdays are usually busier than weekends, Mondays are especially busy, etc.).
Measuring how many requests happen in an hour, therefore, could result in dramatically different results depending on what time of day you measured during. In order to avoid that, and to make sure the estimate can be more accurate, try covering the whole week worth of requests or rates rather than a single day or hour.

Last but not least, try a little experiment!
There are ways that you can assess how much of each telemetry data can be generated by using the OpenTelemetry Collector.
- Instrument your application and platforms using OpenTelemetry so that they can be emitted via OLTP.
- Install and run the standalone OTel Collector.
- Configure the Collector to run its internal telemetry service that will expose statistics.
- How many spans, metrics, and logs have been exported by monitoring: otelcol_exporter_sent_log_records, otelcol_exporter_sent_metric_points, and otelcol_exporter_sent_spans.
- You do not have to send the data, but can also run an OTel Collector to output everything as logs, which will also output stats into standard output.
- Run the application. Most ideal is to run requests that would represent the production environment as closely as possible.
- Monitor the telemetry. You can scrape the telemetry endpoint and send it to Honeycomb to analyze it easily!
This may feel like a bit of a work, but the Honeycomb team is there to help you out. We offer free 14-day trials of our enterprise plan so that you can assess the data and make proper decisions on how to instrument your telemetry data and get an estimate of how many events you’ll need.
Try our enterprise plan
It's risk-free! Request your free 14-day trial today.