Observability built for the demands of AI
AI is changing how we write, test, and deploy software. To understand what’s really going on in production, you need an observability platform with rich context and fast feedback loops that enables rapid learning for your developers and agents. That’s Honeycomb.
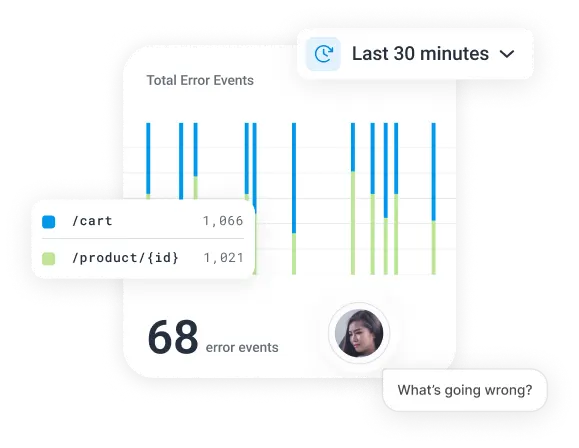
Never hit a dead end
Honeycomb lets you zoom in for details, then zoom out to see the big picture. You and your agent see your entire stack and get answers fast.
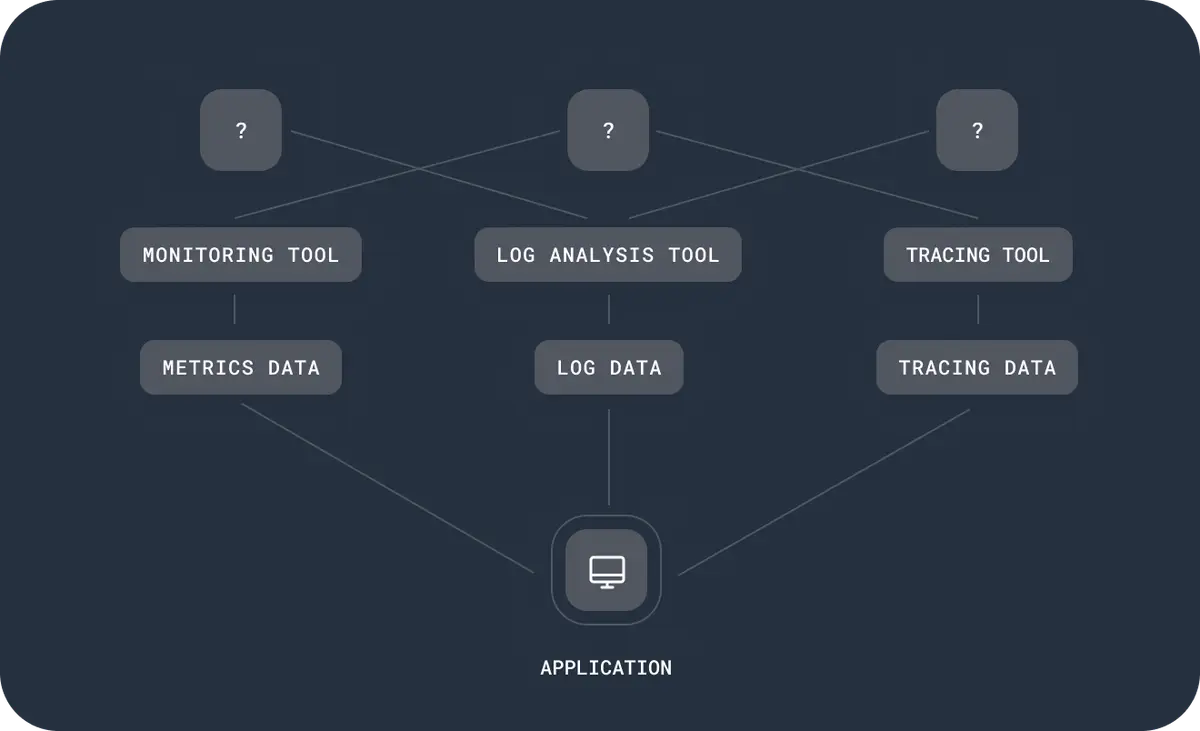
Traditional Monitoring Tools
Logs, metrics, and traces are stored separately, often in different tools. Dashboards can't answer the questions you didn't predict because siloed signals lose the context you and AI agents need to understand and debug production. Redundant data storage multiples your costs without multiplying your insight.

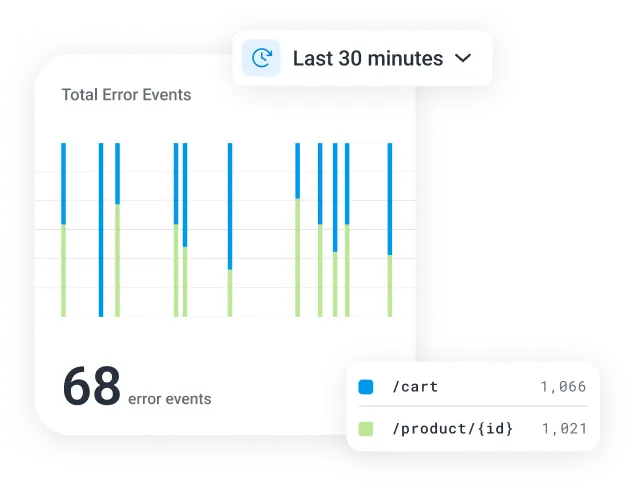
Observability with Honeycomb
Honeycomb's unified data model retains the high-value relationships across production data, and our purpose-built columnar data store delivers sub-second query times, even across high-cardinality data. This allows you and your AI agent to investigate and debug issues before they impact customer experience.
Ask questions. Get answers. Stay in the flow.
Query in natural language in Canvas or directly from your IDE with Honeycomb MCP. See full evidence of your AI-powered investigations, and dive deeper into the most relevant details.
Canvas
Any developer or SRE can debug like an expert with AI-assisted investigations. Ask questions in natural language, explore your data interactively, and share investigations or access them from your IDE for collaborative debugging.
One unified platform.
Unlimited Insights.
Honeycomb takes data for all of your software, stores it once, and opens up limitless querying and analysis, supported by AI-assisted workflows and dynamic visualizations. Scroll to learn more.







Supercharge investigations with AI
Work smarter, not harder. Speed up your investigations with Canvas, an AI-assisted copilot, or access your observability data directly with your IDE via Honeycomb MCP so you can stay in your state of flow.

Solve the problems you can’t predict
AI systems bring new complexity, like nondeterministic behavior, expensive LLM calls, and multi-step agent workflows. We created Honeycomb to help you solve the unknown unknowns that traditional monitoring approaches don’t address. Explore the ways Honeycomb can work for you.

Analyze and understand your whole system
Make answering questions and solving problems simpler. Any engineer can use our intuitive platform and built-in analysis tools to pinpoint issues, conduct investigations, detect anomalies, and identify solutions.

All your data, one predictable price
Logs, metrics, traces—send any structured data our way without incurring extra costs as you capture more data. Let our experts help you build an efficient data strategy that captures what you need and lets you access more data on demand, all while keeping your costs predictable.

See how it works
Before Honeycomb, it was like poking around in the dark. You’d bump into things, break glass, fix something, and hope it didn’t break again.

The features at your fingertips
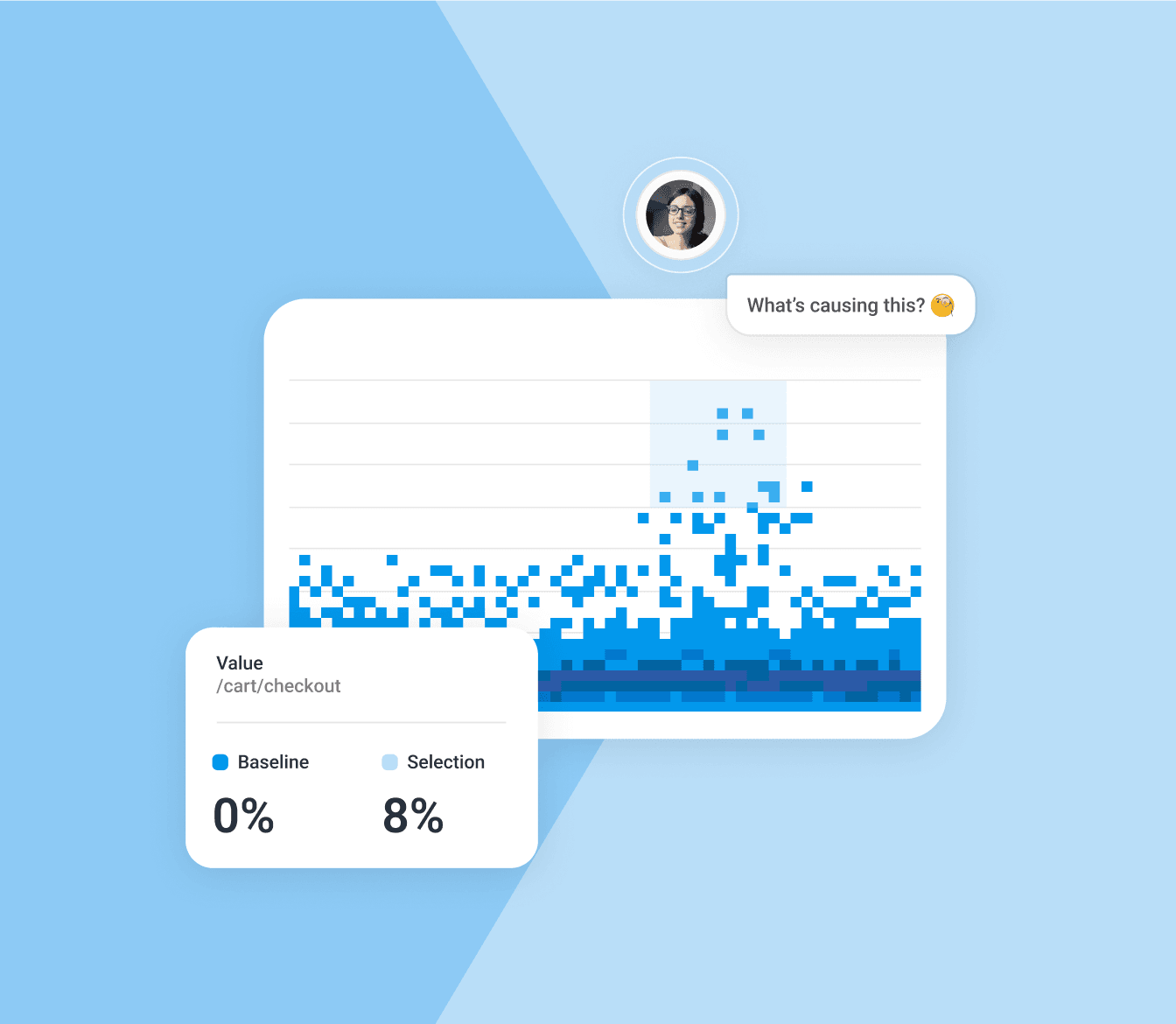
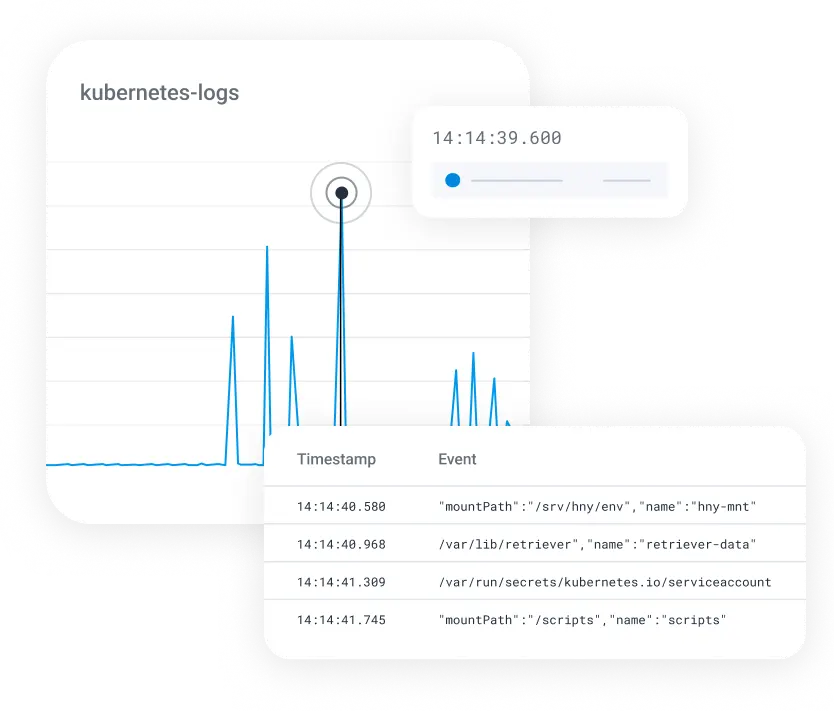
Level up with BubbleUp
Automatically detect outliers, then zero-in with our dynamic analysis tool to understand what happened and why. Easily explore across multiple views—traces, metrics, or logs—and go wherever the information takes you.
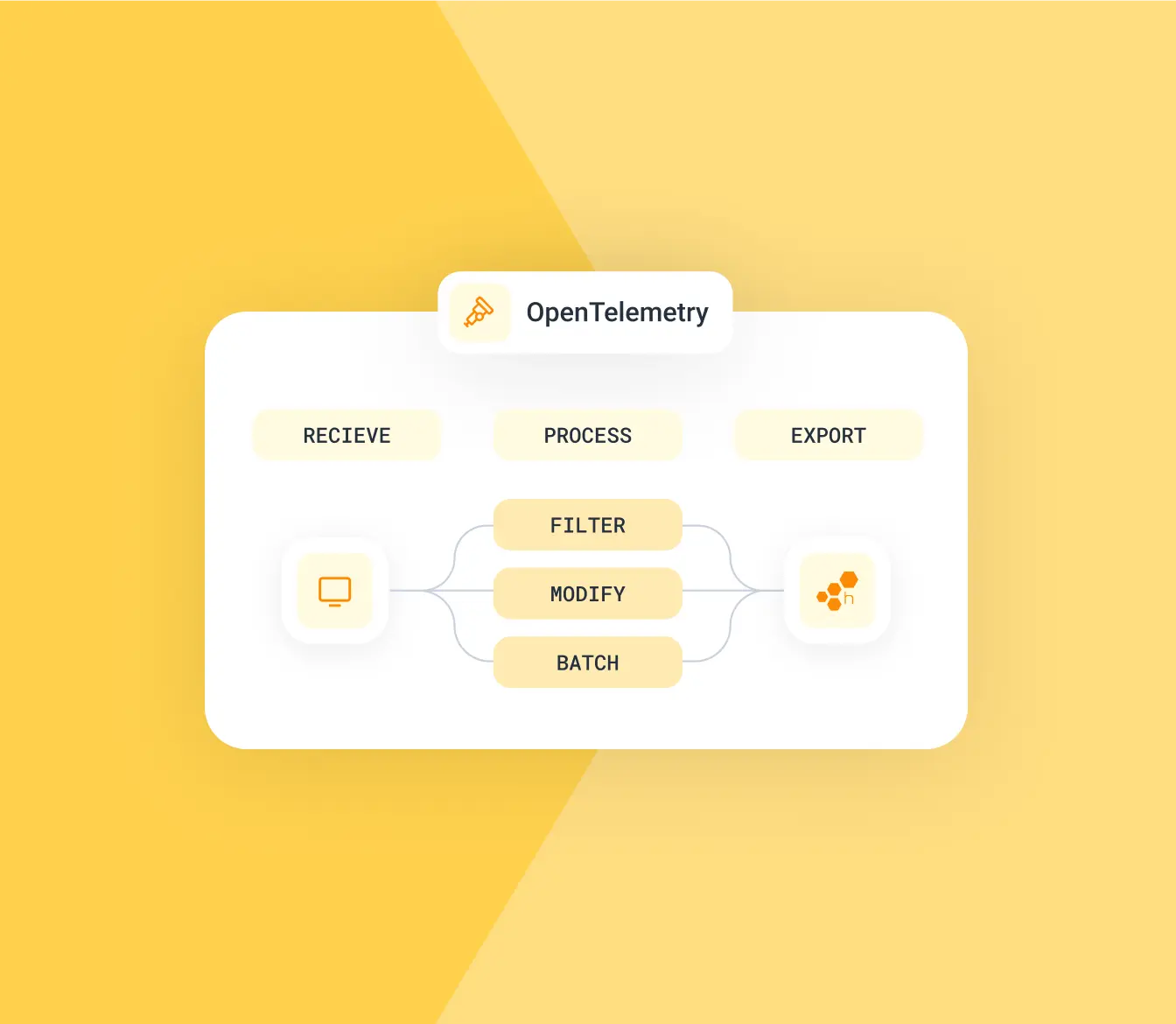
All-in on OpenTelemetry
Honeycomb supports OpenTelemetry. With over 40 programming languages from Java to Ruby, OpenTelemetry allows teams to instrument, collect, and export high-quality telemetry data.
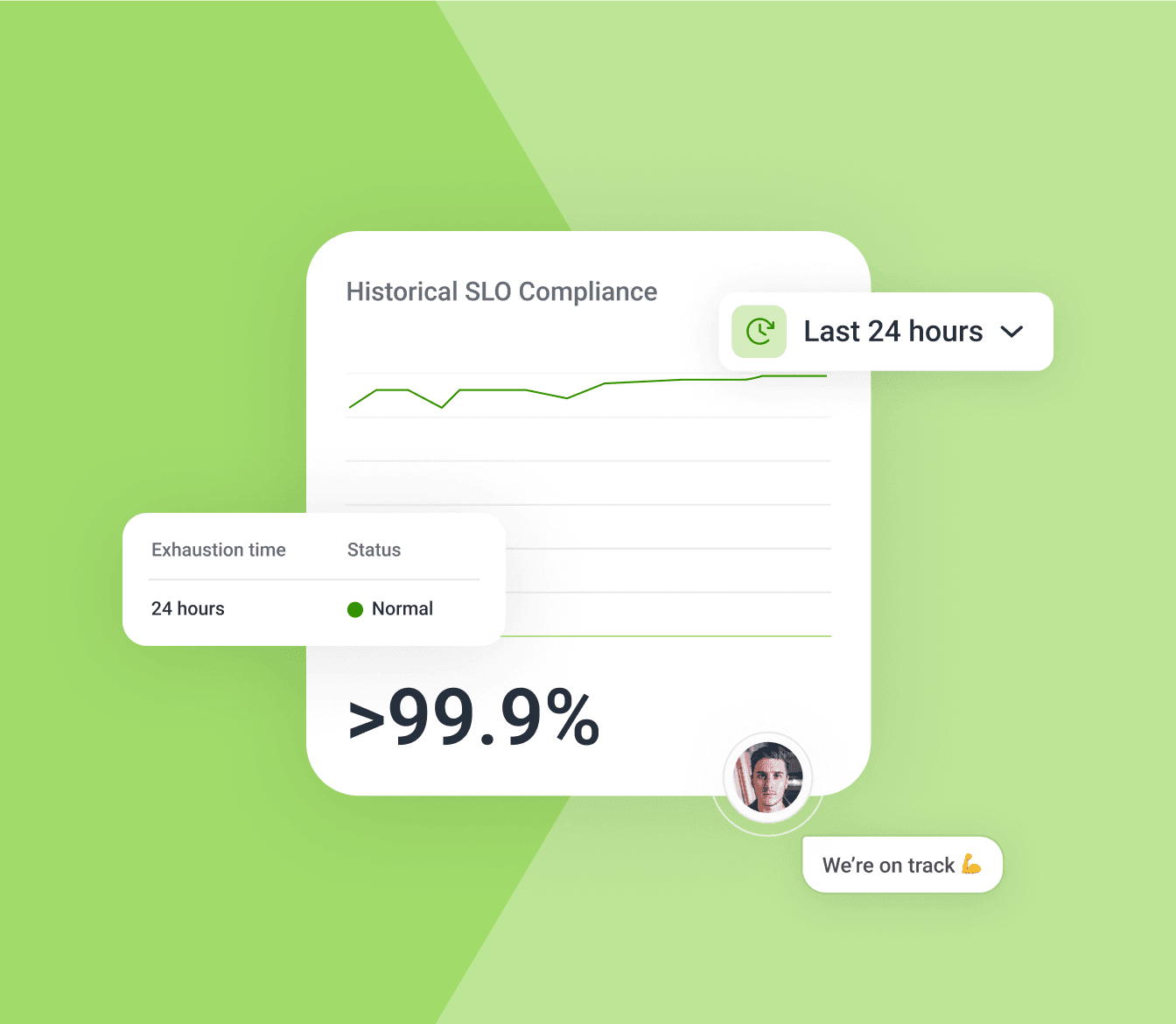
Go SLO to react fast
Service Level Objectives (SLOs) let you specify what good looks like in the language of your business. Set alerts if your service falls below acceptable levels and don't alert on noisy stuff. Every SLO is debuggable.
Built for organizations of any size
From small projects to enterprise-scale applications, Honeycomb enables you to resolve incidents faster, no matter how complex your code is.
User-friendly interface
Access an intuitive, easy-to-use platform that clearly highlights anomalies and encourages endless exploration.
Effortless collaboration
Save useful investigations and share them with your team, making hand-off a breeze. Don’t send a lengthy message, simply share a Honeycomb link.
Robust onboarding
Get up and running with guidance, best practices, and quick wins. Need help migrating from your current tooling? We’ve got your back.
Predictable costs
Pay by event volume. That’s it. No penalties for adding extra fields. No hidden charges for adding users.
Security compliant
Honeycomb is SOC 2 Type II certified and regularly undergoes independent penetration testing.
Seamless integrations
Honeycomb works with all modern application languages, frameworks, databases, SaaS applications, cloud providers, and more.
Debug complex systems in seconds at enterprise scale.
Experience the power of Honeycomb
Jump into our sandbox and start exploring—no signup required.