The Serverless Observability Problem
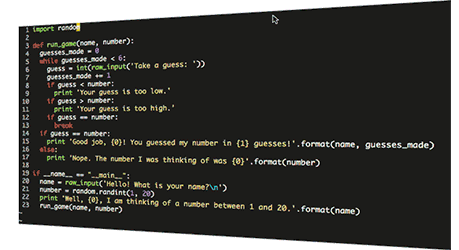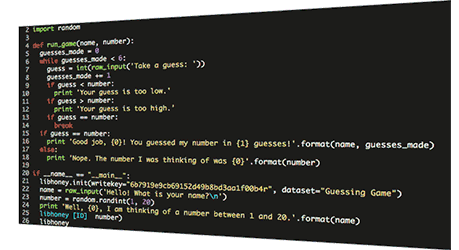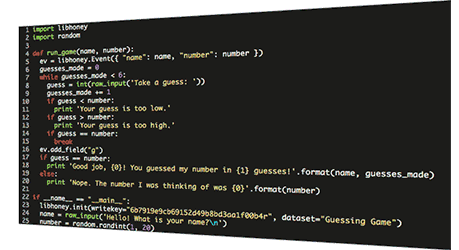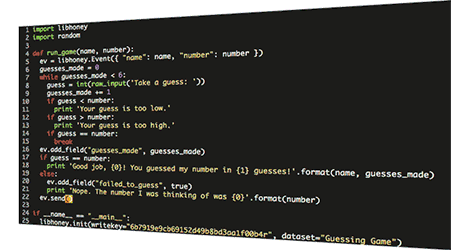
“Serverless” apps are built by writing and deploying functions to cloud providers and using their code or your own to connect other third-party services for data storage, queues, push notifications, etc. Serverless patterns are defined by never having to manage any infra below function. This can be a very efficient and powerful way of building loosely-coupled apps. The paradigm was popularized by AWS Lambda.
But serverless can be opaque and hard to debug for the very same reasons that it is powerful: you can never log in and just look at the thing silently swallowing requests. If the functions we’ve written and the services they are using aren’t well-instrumented, it can be frustrating-to-impossible to know what’s happening.
We built Honeycomb to answer those questions–to deal with microservices, serverless, distributed systems, polyglot persistence, containers, CI/CD–and build an understanding of how your systems and software actually work. You can’t debug what you can’t know.
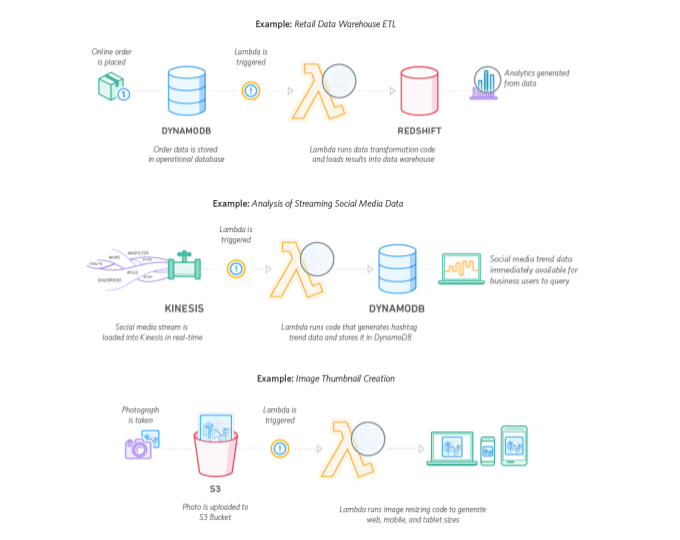
What to do
Build observability into your serverless environment:
- Instrument code verbosely. Pay attention to the boundaries between services; it’s up to us to reliably surface error messages and debugging information.
- Get as much detail as possible out of third-party components. For example, does the database service emit useful events or metrics about storage state, system stats, or internals? Consume these alongside those coming from your own code for correlation.
- Instrument the deploy path and rollbacks with extra care. It can be hard to tell what changed.
- Think carefully about what happens in every failure scenario (retry, fail over, abort?) and log detailed explanations of what you expect to happen. Cascading failures are all too common, as every user of AWS us-east-1 knows well.
- Audit configurations and config changes as part of system state.
- Keep a lid on the proliferation of third-party services. For example, try to standardize the event store in something reusable for client, functions, databases.
Observability requires rich instrumentation, not to poll and monitor for thresholds or defined health checks, but to ask any arbitrary question about how your software works. An observable system is one you can fully interrogate.