Honeycomb was built for the AI era. Learn how to futureproof your software for what comes next.
Discover why Honeycomb is the better choice for your engineers, your customers, and your bottom line.
Start your journey with the definitive guide to observability. Download our complimentary ebook.
Bring observability to every software engineer.
Learn about our company, mission and values.
Come for the impact, stay for the culture.
See Honeycomb's latest press releases, media, and more
Learn more about becoming a Honeycomb partner.
Already a Honeycomb customer?
Austin Parker
Is the era of tokenmaxxing over before it even began? The rise of token leaderboards to the death of token leaderboards at companies like Amazon seem to have taken place in less than three months!
Kale Bogdanovs
Dan Juengst
Shabih Syed
Jessica Kerr (Jessitron)
The OpenTelemetry Collector is usually deployed as a long-running process, but when telemetry is rare, it makes sense to run it as a Lambda function instead. Here's how to do it.
Sara Cave
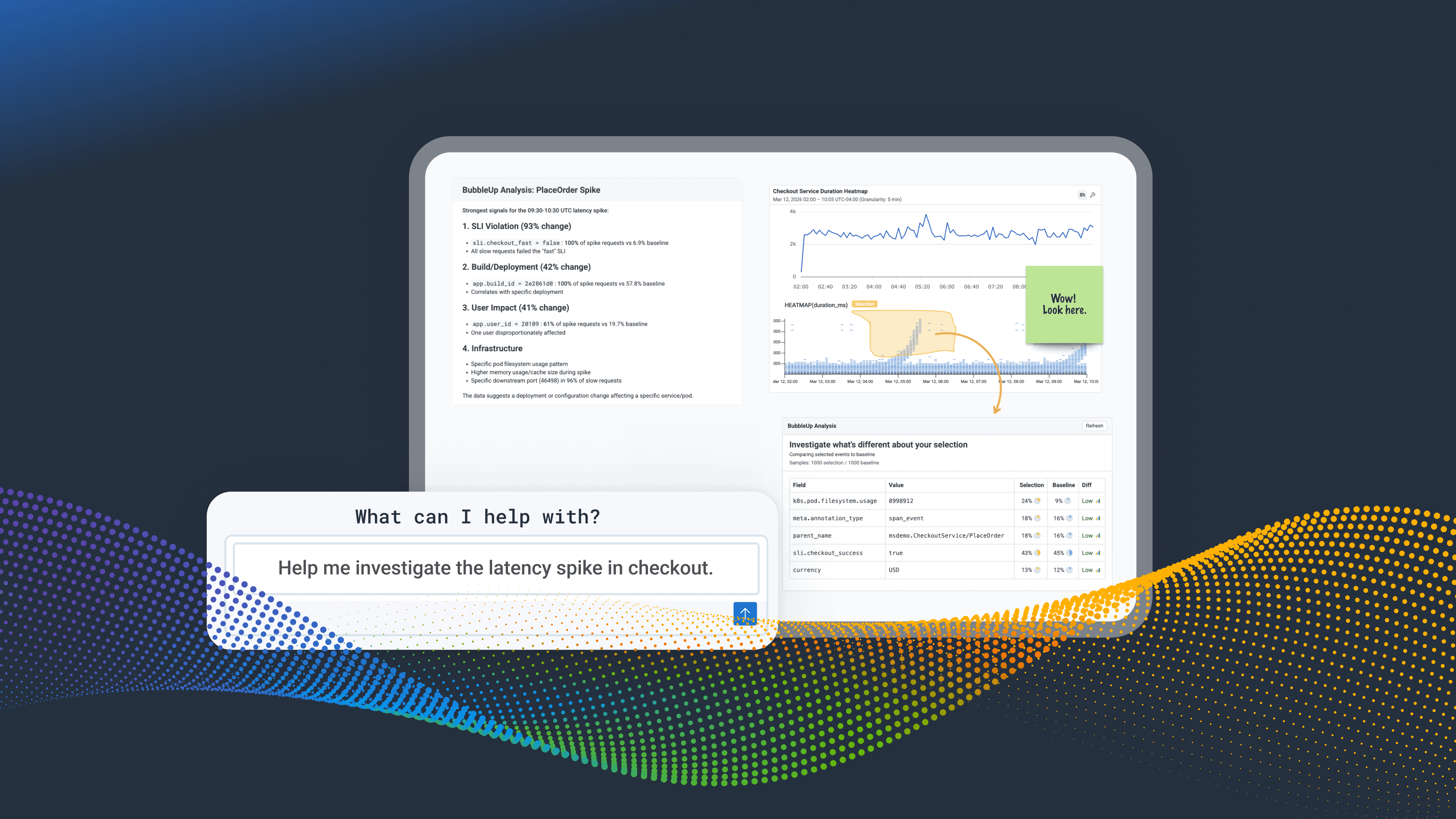
Our support team leverages our own tools, Canvas and the Honeycomb MCP, to navigate vast and complex internal telemetry when debugging customer issues. This shift means we spend far less time on query mechanics and detective work, and customers get answers faster.
Ken Rimple
We just wrapped O11yCon 2026, and this year's conversations hit differently. Agent-based software development is here, now. It's no longer an optional choice, and everybody is struggling to understand what their agents are doing and how to make them cost less and perform better. Over the course of both days, we saw clearly that the old assumptions on how and who (or what) writes our software has been upended.
Auto-investigations that start the moment a trigger fires. Custom skills that encode your team's runbooks. A live workspace where humans and agents investigate production together. Now available to all Honeycomb customers.
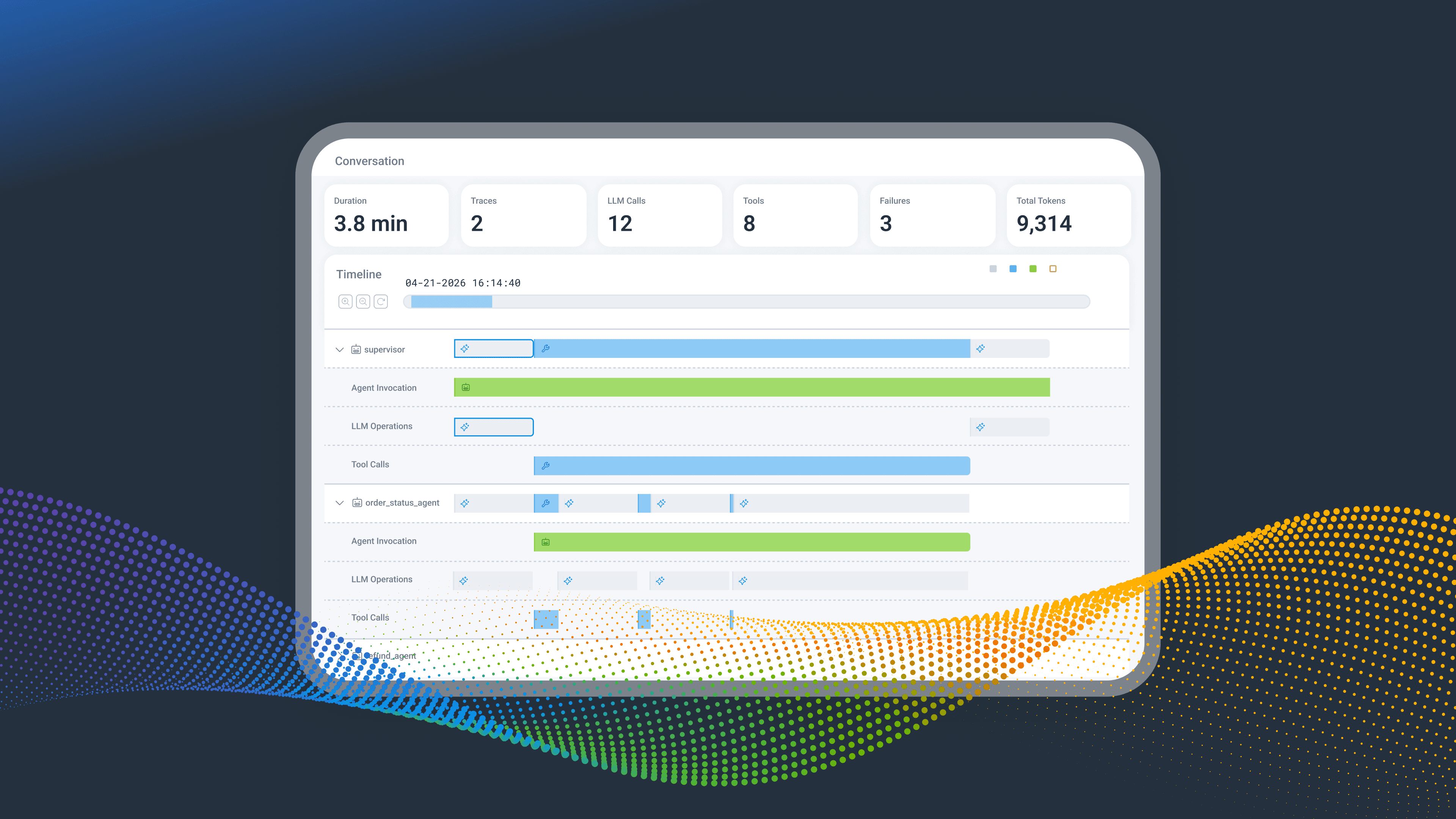
Every LLM call, every tool invocation, every agent handoff, every downstream service span, in one conversation, in one view. Now in Early Access.
Howard Yoo
Why hop between tools when you can have a single, unified view? By speaking the common language of OpenTelemetry, Honeycomb and Embrace are finally closing the gap between the frontend and the backend.
Matthew Scott
Honeycomb is proud to share that we have achieved the Amazon Web Services (AWS) Financial Services Competency.
AI is reshaping the SDLC in two directions at once. AI-generated code is shipping faster and with less human supervision than ever before, while agents and LLMs are running directly in production, where they behave very differently from traditional software: non-deterministic, with a wider blast radius than any single function or component, with no stack trace to catch when something goes wrong.
Day 1 of Innovation Week was about how software gets validated, where observability fits, and the problems that have always been hard but are now genuinely urgent with AI part of the software development lifecycle.
Mike Goldsmith
In this post, I'll show how OpenTelemetry Weaver lets you define, layer, and validate semantic convention schemas so that both humans and agents have full context on every attribute in your telemetry.
When you want to add some information to your tracing telemetry, you could emit a log, create a span, or add a piece of data to your current span. Adding a piece of data to your current span is the best! Usually.
Get it delivered straight to your inbox.
By subscribing to our newsletter, you agree to Honeycomb’s Terms of Service and Privacy Notice.
Do you receive 50 million log lines per day and struggle to see what actually matters? Health checks, heartbeat pings, connection pool messages—they all drown out the errors and anomalies you're trying to find. What if the Collector could figure out the patterns for you?
Midge Pickett
The new Honeycomb MCP course in the Honeycomb Academy gives you a starting point when you're not sure what to ask, and teaches you how to direct an investigation so you're getting evidence, not just answers.
A parhelion is created when light refracts through hexagonal ice crystals in the atmosphere, forming bright spots that appear on the horizon, connected by a faint halo. You don’t have to squint very hard to appreciate how relevant this is to our current AI moment.
This is what a semantic convention migration looks like in practice: not a clean cutover, but months of coexistence where old and new attribute names overlap. In this post, I'll explain why this happens, how the OpenTelemetry Collector's schema processor is designed to automate migrations in both directions, and what we're actively working on to get it into a state where everyone can use it.
Observability is the visibility you need to get the job done. Sending telemetry to Honeycomb explains what your agents are actually doing. OpenTelemetry provides semantic conventions for generative AI systems, a spec that defines how agents, LLMs, MCPs, and tools are properly observed. The primary telemetry is defined as trace spans and other events with specific naming patterns, mostly starting with gen_ai.
Erwin van der Koogh
One of the customers I’m currently working with is a large financial institution that has a robust three pillar implementation. Every critical application ships their telemetry to either or both their cloud-native tool and a central tool. This worked fine when they had relatively monolithic applications, but with their architecture moving towards a service-based one, it’s getting harder to manage.
Rox Williams
Over the last three months, we’ve been exploring what about software development and observability changes with AI, and what doesn’t. Our conclusion: these five principles will still remain true, even when 90% of the code is AI-driven.
Alex Boten
The performance impact of instrumentation on running applications should be minimized wherever possible, and this is what led to the investigation described in this article.