Understanding production has historically been reserved for software developers and engineers. After all, those folks are the ones building, maintaining, and fixing everything they deliver into production. However, the value of software doesn’t stop the moment it makes it to production. Software systems have users, and there are often teams dedicated to their support.
Field engineers directly support users on these platforms day in and day out. Customer-facing teams are the first line of defense when there is any unexpected behavior, bugs, or confusion about a workflow. It’s important to empower these teams to understand how complex systems interact, what are expected and unexpected behaviors, how users actually use the product, and to diagnose the best path to resolve user concerns. Without this crucial context, customer-facing teams can misinterpret the urgency of some issues—for example, thinking something is a fire when it isn’t.
This leads to a vicious cycle. Frustrated customers come to field engineers with a unique problem, the customer-facing team misdiagnoses (or is unable to diagnose) the problem, and escalates to engineering. Engineering then receives an unnecessary page. None of this would have happened if the support teams had the data required to handle the problem autonomously. This is extremely frustrating for everyone involved.
So, how do you fix this?
Luckily, there are three simple steps you can take to bypass this endless frustration loop—all centered around observability:
- Democratize your data by instrumenting complex systems and providing access to this data to field engineering teams.
- Provide enablement to non-development teams to unpack and understand the instrumentation described above. This can come in the format of logs, traces, and metrics.
- Build jumping-off points for field engineering teams to base initial work on. This can take the form of documentation, recommended queries, or Board creation.
Breaking the cycle: open the gates!
At Honeycomb, we empower our field engineering teams to understand production by—you guessed it—using Honeycomb. Here are some ways that we use observability to support our own customers.
Support
Ding! A support ticket describes a customer experiencing unexpected or confusing behavior. The support team uses Honeycomb to quickly narrow down potential root causes.
- Avoiding the replication loop. What’s worse than experiencing a bug? Being asked to recreate that bug again and again and again to solve the issue. Observability can prevent the “can you replicate that?” loop. With the right data, support can find errors and unexpected behaviors. If the telemetry captures it, so can support.
- More targeted escalations. When digging into the telemetry, support sees a lot about the problem, like user IDs, error codes, status codes, and latency. When they find the services a problem originated from, they can escalate the issue to the correct engineering team.
- Validating improvements. An escalation is marked “resolved.” How can a team validate the results before consulting with the customer? With Honeycomb, of course! Using the same queries that helped in the root cause analysis, support reruns their initial queries and compares the system’s performance pre- and post-fix to ensure the issue is resolved before reaching out to the customer for final validation.
Learn more on how your team can unleash support power with Honeycomb.
Customer success managers
Customer success managers (CSMs) build and maintain long-term relationships with their clients across their entire observability journeys. They are here to advise and provide your team with the resources it needs to be successful. CSMs use Honeycomb to ensure each client is successful with observability.
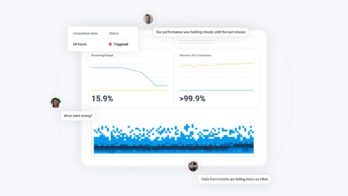
- Investigating the customer experience. There is a Board built for CSMs that acts as a jumping-off point in investigating customer experiences. If a customer reports high latency, they can quickly check to see what type of lag they are experiencing and if other accounts are impacted. This also makes it easy to keep tabs on which folks may be hitting a column limit, rate limit, etc. Honeycomb’s telemetry helps the team keep a bird’s eye view for any technical blockers.
- Tailoring client alerting. “Can you alert the channel if we use more than X events in a 24 hour cycle?” “Is it possible to be alerted if we hit a rate limit?” These are questions that CSMs at Honeycomb hear often. Using the power of Honeycomb, they can easily configure meta alerts on behalf of customers.
- Understanding customer instrumentation. It is best practice at Honeycomb to validate which instrumentation libraries a customer uses before we do anything else. By leveraging Honeycomb, CSMs can see if a customer uses Beelines, OpenTelemetry, Libhoney, the Kubernetes agent, etc.—along with which version. This allows CSMs to make recommendations regarding upgrades, and drives conversations about improvements clients can make to their instrumentation.
Product training
Honeycomb has many powerful features. To understand how to fully leverage their power, we offer a variety of workshops. These workshops range from beginner to experts looking to uplevel their observability game—so no matter where you are in your journey, we have a workshop for you.
- Exploring your data live. The most impactful way to learn a new ecosystem or tool is by hands-on learning. Product training encourages users to train within their own environments. This leads to impactful sessions where our implementation engineers sometimes find real production issues during sessions, thus helping teams learn more about Honeycomb and their own systems.
Customer architects
Customer architects are the technical consultants of our customer success organization. They create collateral like starter packs, join customer calls for custom solutioning, and so much more.
Here are some ways customer architects use Honeycomb to better advise the team and our clients.
- Deep dives into customer telemetry. Every customer at Honeycomb has unique data and instrumentation patterns. To provide relevant, personalized guidance, customer architects use Honeycomb to better understand these patterns, unique fields, libraries in use, traffic trends, and more. This empowers the team to make tailored recommendations on ways our clients can enhance instrumentation for a better observability experience.
- Refinery troubleshooting and scaling. Volume control is a hot topic at Honeycomb. Customer architects are always hard at work to find the best ways that customers can manage event ingest and maintain meaningful granularity for troubleshooting. To assist in this scaling, customer architects have created artifacts such as Refinery Boards. When clients run into scaling questions (or trouble with launching Refinery), the Refinery logs and metrics sent to Honeycomb can help the team debug issues, provide recommendations for scaling, and assist in fine-tuning rules.
- Content creation. Customer architects write blogs, film videos, and build artifacts in order to provide a robust library of relevant, hands-on technical content that empowers our clients to tackle new challenges and opportunities. They leverage Honeycomb to analyze user behavior, and select content topics. They also use Honeycomb to provide meaningful telemetry examples based on demo and real production Honeycomb observability.
This is the tip of the iceberg
There are so many avenues for telemetry to empower field engineering teams. It’s never too late to open the gates and democratize your data. Empower your customer-facing teams today through transparent, accessible observability.
Want more ideas? Reach out to the support team today and set up a consultation.