This is my first week here as the first dedicated SRE for Honeycomb, and in a welcoming gesture, I was asked if I wanted to write a blog post about my first impressions and what made me decide to join the team. I’ve got a ton of personal reasons for joining Honeycomb that may not be worth being all public about, but after thinking for a while, I realized that many of the things I personally found interesting could point towards attitudes that result in better software elsewhere.
I’ll take a stance that talks about reliability, but I’ll start by going over some definite-but-subtle signals I picked up about Honeycomb throughout the interview process and my first few days here. I’ll then tie them to principles I believe are critical to fostering resilient organizations, and how these likely bubble up to be found in Honeycomb’s product.
Fostering Human Processes
I’ve spent the last decade building and operating large-scale production systems with all sorts of teams, in all sorts of environments. Over the last few years, I’ve tried to find ways of making better, more operable systems. For personal reasons, I decided to move on from a Staff “Engineer” position* for something possibly closer to operations and incident handling. I found myself looking at Honeycomb’s job ad for their first SRE position. A few things instantly stood out.
It didn’t name any specific technology, nor did it necessarily ask for any specific prior titles or education. Instead, it mentioned characteristics of the person they wanted:
- Someone who can debug both automated and human processes
- Someone who can work in both software engineering and automation
- Someone able to find balance in all things
- Someone who enjoys teaching and practice
- Someone with some experience of managing stateful services
This led me to apply despite never having held the SRE title before and not having worked extensively with the main backend language used there. I figured it was easier to brush up on specific pieces of tech than developing the higher-level attributes they were looking for, and they probably figured as much because I did get the interview.
I’ve interviewed quite a bit over the last decade, on both sides of the table, from short one-hour sessions to 3+ days-long “tryouts.” I, like many others, have formed very strong opinions about what interviewing ought to be like.
https://twitter.com/mononcqc/status/1291094216664326146
At Honeycomb, the sessions involved discussions about how the role should be defined, how prioritization needs to be done, code reviews, understanding how the product is being driven, and the role of internal advocacy. They also asked me to prepare a short presentation about bringing services to production with a Q&A after it.
By all means, this wasn’t an easy process, but having it grounded into what real work is like meant Honeycomb’s interviewing process was refreshingly realistic. It seemed tailored to what actual work would be rather than what people aspired it to be like if they wanted to boast about it at a conference.
Frankly, it was also surprising to me to see a ton of people with far more SRE experience just be fine with discussing what the position should be and having a lot of leeway in shaping it accordingly. In the end, I ended up choosing to join Honeycomb because it felt that it could be a place and a team where I’d have a ton to learn, but also a bunch to share as well.
With my first week loosely coinciding with the company’s kickoff activities for the year, I got to see even more of their approach in how the organization reflected on its last year and planned 2021. The approach they’ve had the entire way through felt deeply centered on people-first, characterizing people as non-linear first-order components in software development, and fully aware of sociotechnical challenges The awareness of people’s value appeared to run deep throughout the company.
I have generally seen strong alignment on such values in some teams or departments, but rarely within entire organizations. I have not been here long, but I believe it has been and will remain a key success factor for Honeycomb.
Sociotechnical systems and context awareness
To show why I think centering on a people-centric approach is a key factor, there are a couple of questions I like to ask to people working in tech:
- How many projects were you involved in that failed mainly because you feel the technological choices were wrong?
- How many projects can you count where you instead believe the failure felt like it was mainly related to breakdowns in communication and shared understanding?
Usually, and for me personally, the answer to the first question can be counted on one hand, maybe two. The second question, however, feels like it’s uncountable. Not just for me, but in the stories I’ve heard from other people as well, so there is a third question I like to follow up with:
- Do you feel you’re spending most of your time focusing on the right one of these questions?
As much as I’ve always enjoyed the deeply technical details and pulling on all the threads I can in a hairy investigation, that third question has long gnawed at me. In fact, it’s one of the things that attracted me to Erlang, a language and ecosystem where I spent my last 10 years working: It takes a basic stance where it is accepted that errors are going to happen regardless of what you try to do before deploying your software, and that you should therefore provide constructs to cope with them rather than hoping very hard they never show up.
The more time I spend in this industry, the more interested I get about that social aspect of our systems. Initially, as a software developer, it’s tempting to frame the software as an independent system that you work on. You can make the system as correct, fault-tolerant, and as robust as possible. If a problem comes up, it can be addressed in code, hardware, and through automation. With enough time and effort, we can get things in a state where they’ll be good and hopefully self-running. But the flaw in this approach is that the world is a dynamic environment and all targets we have are shifting constantly.
We have to remember that the humans who write, operate, and influence the software are also part of the system, and we have to broaden the scope of what our system is to encompass people. A clear, visual explanation can be found in the STELLA report’s above-the-line/below-the-line framework. A framing of systems as being both social and technical (sociotechnical!) is pivotal. We don’t have to abandon efforts to make the technical aspects of the systems robust, but we have to be aware that its ongoing survival is a question of adaptation in the face of surprises. This last aspect is resilience, and it isn’t something code can realistically demonstrate on its own.
That assertion can feel contentious. It’s related to something cognitive engineers call the context gap. In short, all solutions and strategies we have to solve a problem are contextual and depend on the environment and situation you’re in. People tend to be good at observing and being aware of that context, picking up a few relevant signals, and building a narrow solution that works for a restricted set of contexts. More importantly, we have the ability to notice when a solution no longer fits its context, and then broadening the approach by modifying the solution.
On the other hand, automated components tend to start at the focused, narrow end. In practice, they do not have the ability to properly evaluate their environment and their own fitness, and neither are they good at “finding out” that the signals they’re getting are no longer relevant to the overall system success. They therefore cannot really “know” that they need to adjust. Closing the context gap requires the ability to evaluate and perceive things in ways our software systems can’t yet do as reliably, or nearly as effectively, as people. A good solution will require people in the loop if we want it to remain good over time because the world is dynamic and requires continuous adjustment.
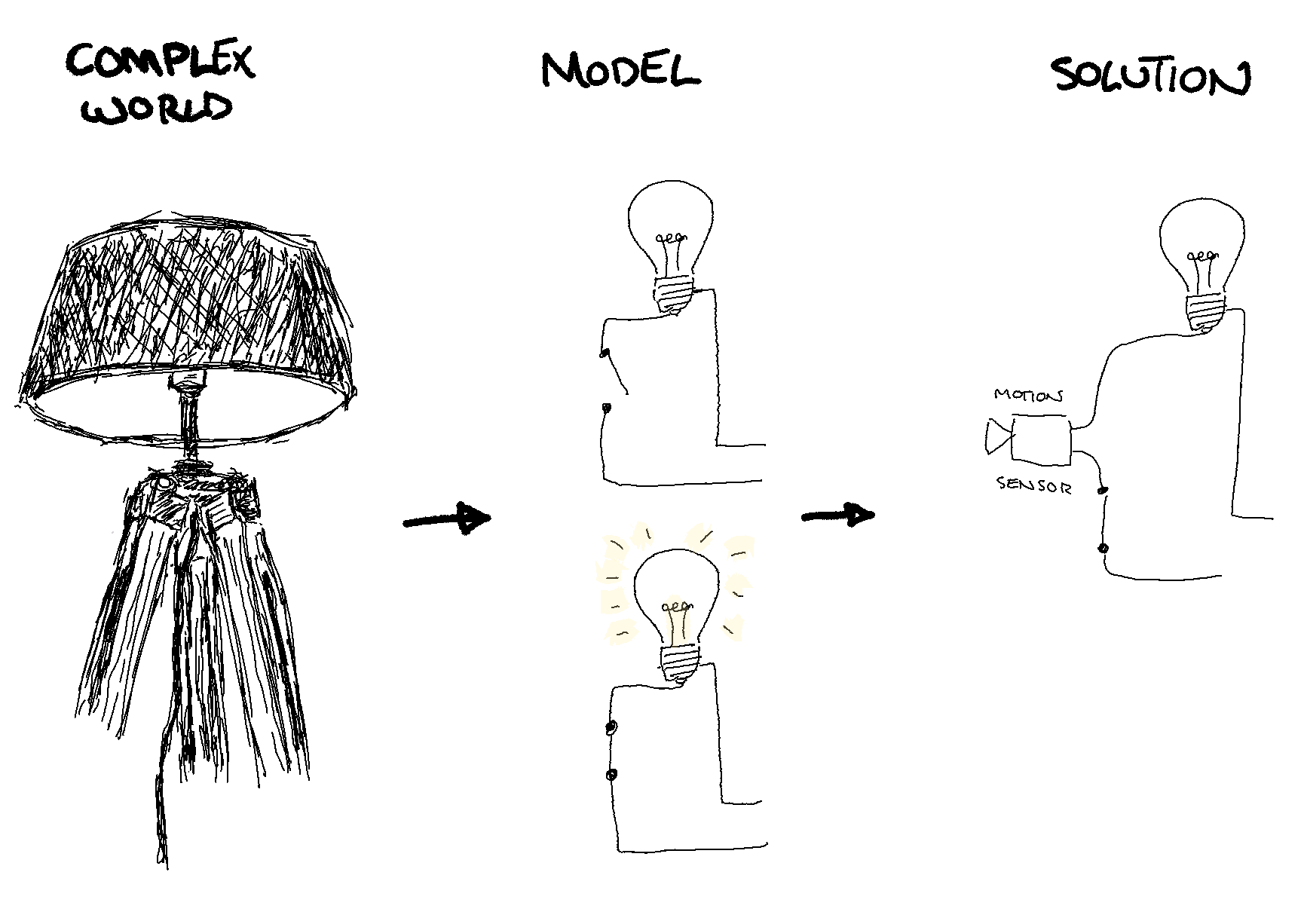
The solutions we build (to the right) are a response to a simplified model (middle) we make of the real world (left). As a consequence of this, a solution is often bound by the model’s scope, and cannot adequately know when its strategy is no longer adequate nor adjust to the complexity of the real world. It is no surprise that almost all light switches with a motion sensor also come with a manual control to allow humans to take over when the automated solution fails.
This underlines how important mechanisms such as chaos engineering or blame-aware incident reviews can be—they are processes meant to figure out where and how things break down, and to let us, as teams, re-synchronize and update our individual mental models of the whole sociotechnical system. They are tools we use to continually improve our solutions and our organizations. They do not replace technical solutions and good expertise remains critical. However, it frames and guides the form it should take to make it more effective, useful, and sustainable.
Ideas such as blamelessness have become more and more popular, but many of us are still far from a great position there. There is a tendency to focus a lot on blameless to mean no retribution—which is a nice and necessary starting point—but to then end the process there. It’s a bit funny to see people go, “We do not want to blame people for this event,” but otherwise still frame everything as a human error, with undertones that everything is someone’s fault and we’re just being nice by not naming them. This is noticeable by a general attitude where any of the following can happen:
- Human error is called out as a cause that needs remediation
- People are seen as problematic around operations because they’re unpredictable
- Automation is perceived as necessarily good since it takes people out of the loop
- Next time, we’ll just be more careful and do a better job
The above falls under shallow blamelessness—it avoids retribution, but still finds fault against individuals and frames most corrective work in controlling people. Better sociotechnical approaches see humans as a key factor of success, see their unpredictability as signs of adaptive work taking place, and do not attempt to take them out of the loop but rather try to enhance their capabilities. Aligning the socio- and the -technical parts of the system requires more than awareness; it requires a different perspective altogether.
Adapting and sharing observability
One of the things that transpired in the short time I’ve been here is that people at Honeycomb are aware that observability is not something you have; it’s something you do. Observability is to be used as a verb, and much like resilience and adaptive capacity, it tends to show up in critical, high-pressure situations.
Observability specifically requires interpretation. You can’t just open the black box, look inside, and get an understanding. It’s too noisy, too messy, and it’s steeped in layers of interpretation and mental models of everyone who’s worked on and around the black box before. It’s not something you can just buy, check things off the list, and be done with it.
This isn’t a big surprise: good alerting tends to depend on SLOs, which in turn can be considered good if they align with customer experience. Good logging states facts and does not mislead investigations with hamfisted suppositions done without the proper context. Good tracing lets you explore and experiment through high-cardinality searches. This investigative work is driven by existing mental models as we try to repair the context gap between what we thought would happen and led to the solutions we have, and what actually happens and will drive changes we’ll need to bring to products.
This challenge is shared by all software, and by all businesses that write and use it. Honeycomb, like tons of other vendors, provides interesting tools that can be used to a great effect. The one thing I’ve found at Honeycomb though is this deeply rooted idea that tools aren’t enough, and that the human factors within a sociotechnical system are critical to its ongoing adaptation and success. Diversity and experiences of all kinds are key to resilient systems and organizations, and Honeycomb has a lot to offer there (which I recommend checking out) that goes way further than checklists of features.