When an organization signs up for Honeycomb at the Enterprise account level, part of their support package is an assigned Technical Customer Success Manager. As one of these TCSMs, part of my responsibilities is helping a central observability team develop a strategy to help their colleagues learn how to make use of the product. At a minimum, this means making sure that they can log in, that relevant data is available, that they receive training on how to query, and perhaps that they collaborate with the rest of Honeycomb’s CS department to solve problems as they arise.
However, sometimes the organization has bigger goals. They want to improve the performance and reliability of their production system with Honeycomb. They want the experience of their customers and users to play the deciding role when making product development decisions. They want a CX-centric culture.
How do you make that happen?
An obstacle course
A key to centering customer experience and translating that into engineering requirements and tasks is observability. But it’s not enough just to make Honeycomb available when distributed tracing and the power it provides is new to most of the organization. That’s especially true when the intended users are software engineers who’ve never worked in an operations role or been required to support their code in production (read: be on call). In that case, an observability team needs effective ways to roll out Honeycomb to those engineers—in spite of potential obstacles. For example, concerns about working with a new or unfamiliar tool in a high-stress situation like a late-night outage.
That observability team only has so much power to change the organization from within to address such an obstacle. Production pressures may not allow for teams to dedicate much time to practicing with Honeycomb, and their colleagues may not want to go out of their way to learn how to work with it, because they don’t yet see how it empowers them in those high-stress events or even in their normal development work.
If you’re an observability team member facing these challenges, take heart: none of these are insurmountable.
One strategy for addressing them is to look at your organization differently. Consider how to make it work with you and not against you by asking the following question: what are organizational (i.e.: the socio- part of “socio-technical”) patterns and routines that software engineers normally engage in which we can use and treat as affordances?
These patterns, or “social institutions,” offer opportunities to introduce small but meaningful changes that can compound over time. You can use these institutions as infrastructure to grow your colleagues’ confidence with Honeycomb during normal work, which sets them up to leverage it during a crisis. That is an essential component for a CX-centric culture.
If this sounds good, then here are some ideas I’ve had that observability teams can take up to work with their organization’s existing social institutions. Think of these as prompts, NOT “best practices” or prescriptions—they are only meant to inspire. They are vague on purpose and not to be implemented exactly as written. Only by studying your own organization can you determine the precise details of the institutions, so do modify these proposals to fit properly.
With that qualification, let’s take a look at a few ideas broken out by exemplary social institutions.
Social affordances and supports
Team onboarding
Beginner boards
Make Honeycomb a standard part of how a new team member (either to the engineering org writ large or through an internal move to another team) learns about the system and service that their team is responsible for. Put studying things like traffic patterns and the relationships between services in production with Honeycomb on par with learning the codebase.
To that end, teams could create a “beginner board” populated with queries which teach the newcomer the most important patterns and pathways, and show bottlenecks or other known critical points and thresholds. A good place to start is our OTel starter pack, which teams can tailor or use as inspiration.
Those modifications can include trace waterfalls which illustrate crucial paths through key infrastructure (e.g. through load balancers), example heatmaps that reveal standard patterns, and other visualizations which might show other system features, like areas with opportunity to optimize, or which hit critical thresholds in the past and caused things to fall over. Since Honeycomb doesn’t impose a given way to look at the system, there’s a lot of flexibility for teams to create onboarding material that’s relevant to them.
Starter quests
Once a newcomer has developed a sense for what’s normal, the next step is open investigation. Ask them to find something that would improve performance in the system, and then update the code to effect that change. Then, have the developer return to Honeycomb to study the effects of their change so they can see their change moving the needle.
A related idea is to encourage newcomers to explore and challenge the established way that the team makes sense of the system. A set of fresh eyes may see things in a new light and reveal opportunities or perils (e.g. resource bottlenecks) that the current team couldn’t see because of their established perspective. Their approach to completing the quests will probably reveal new areas of the code to instrument, or attributes to add to events. Maybe they’ll even prompt removing old, stale attributes or instrumentation. That’s just as valuable as adding something new.
Finally, this is especially important to do for junior developers. As observability moves beyond old models, this is a chance to set the standard that distributed tracing is the way to understand software systems. The industry has continued to use old methods in part due to their age and ubiquity. Developers new to the industry (or to the practice of writing code and thinking of it in relation to production) should get started with tracing early.
Sprints
Reconnaissance
The idea here is simple: explicitly set aside time during each sprint to explore Honeycomb and look for work to do on the system.
Each sprint contains a standing task to use Honeycomb to investigate the system for performance improvements. Those could be optimizations or bottleneck thwarting—but the point is open-ended exploration serving as a chance to practice using Honeycomb, and to learn how the system behaves with actual traffic.
While doing this, the person is tasked with documenting their findings and sharing them with the team. The team can then decide if a discovery warrants a work task that is either immediately taken up or prioritized in the rest of the backlog. An example of this process could be a developer discovering a system trend approaching a known critical threshold, and creating a task to preempt that problem.
The most crucial part of this idea related to rollout is that the person who performs the exploration task should change from sprint to sprint so that each team member has numerous turns. Through several iterations, everyone grows familiar with Honeycomb and their system. That practice will be crucial for incident response.
Developers will see they can use Honeycomb to explore what’s happening in production even when not officially assigned to do so, or in the course of working on tasks which aren’t derived from the Honeycomb explorations described above. In other words, they’ll have learned the value of observability-driven development.
Recon has the added benefit of devolving responsibility for understanding the most interesting or important aspects of the system to the frontline team. As developers take on the responsibility of stewarding production, they’ll be the ones who know it best and can work in a distributed fashion with other teams in the org (who are on the frontline for their own services). This collaborative approach will keep the system up in an optimal fashion, à la Balinese subak.
Deployments
Watch parties
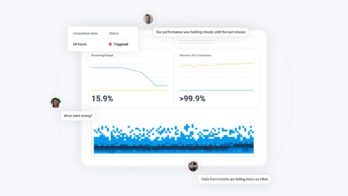
It’s important for engineers to see the impact their code has. Something you can do is notify teams before deployments happen so they can collectively see the effects it has. One of the great benefits of Honeycomb is the ability to work with high-cardinality data. Teams that take advantage of this can vary the fidelity at which they view post-deploy changes in traffic patterns. They can zoom out to see changes in high-level trends and zoom in to identify even individual users’ traffic flow through their system.
This means developers can see in greater—or lesser—detail what effect a given change to their code has for their customers and other users, and they can do before-and-after comparisons, which serve as a chance to display, share, and celebrate the team’s work (or remediate, if need be). Bonus points if this happens on a Friday and if the organization buys lunch for everyone.
Other
Here are a few other candidate institutions for you to consider:
- Standups
- Hackathons
- Industry conferences
- Demos for prospects and customers
- An observability/Honeycomb slack channel for users to share their findings with the whole org
- Internal reports with other parts of the business, e.g. product or finance
- For example, use Honeycomb’s long-lasting query permalinks to demonstrate changes to resource utilization and make the case for certain infrastructural changes or purchases.
Conclusion
Honeycomb customers understand the value of observability and how powerful it is for incident responders. But achieving a CX-centric culture requires that the whole organization adjust its practices, including software engineers. That change can come from working with their existing social institutions, not against them. These small adjustments can produce an outsized impact with time: cultivating confidence with Honeycomb and getting additional value from it.
At Honeycomb, our Customer Success team is ready to help. We provide support through online training, docs, and other resources, and can collaborate to identify tactics like the ones above. Let your TCSM know what they can do for you!