Honeycomb + Google Gemini
Today at Google Next, Charity Majors demonstrated how to use Honeycomb to find unexpected problems in our generative AI integration. Software components that integrate with AI products like Google’s Gemini are powerful in their ability to surprise us. Nondeterministic behavior means there is no such thing as “fully tested.” Never has there been more of a need for testing in production!



8 Best Practices to Understand and Build Generative AI Applications Effectively
Learn MoreToday at Google Next, Charity Majors demonstrated how to use Honeycomb to find unexpected problems in our generative AI integration.
Software components that integrate with AI products like Google’s Gemini are powerful in their ability to surprise us. Nondeterministic behavior means there is no such thing as “fully tested.” Never has there been more of a need for testing in production!
Honeycomb is all about helping you find problems you couldn’t before, problems you didn’t imagine could exist—the unknown unknowns. Charity showed how this applies to integrating with Gemini.
What’s the problem?
In the Honeycomb product, people can ask questions in natural language and get a Honeycomb query and result. We call this feature Query Assistant.

People type in stuff like “Which users have the highest latency?” and get a graph and table. This comes with a Honeycomb query they can modify.
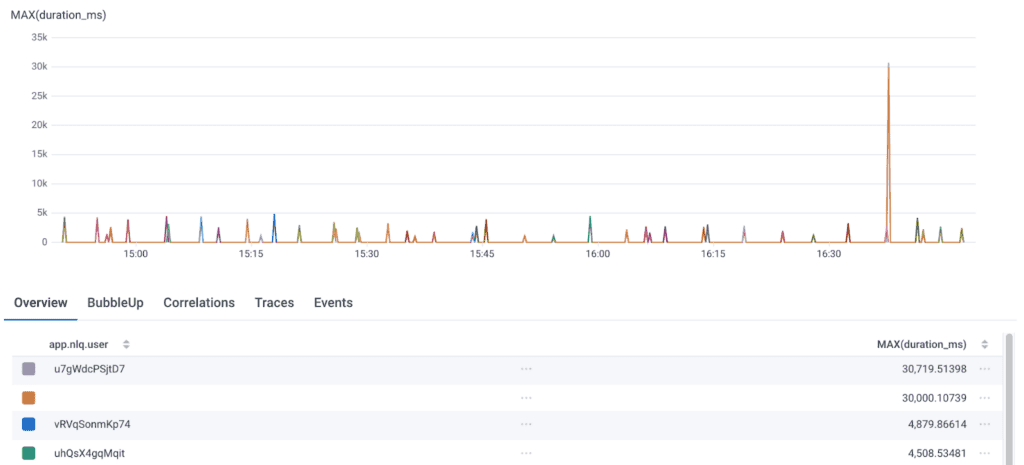
Query Assistant turns an engineer’s question into a valid Honeycomb query—most of the time. Is that good enough?
How good is the solution?
With Honeycomb, we can measure whether the feature is working. We have instrumented the entire operation all the way from when the user hits enter, our RAG pipeline, programmatic prompt construction, AI model call, response parsing and validation, query construction, and submission to our query engine. There’s a lot that can go wrong, even without the nondeterminism of AI!
Building GenAI apps? Read our best practices guide.
All of this rolls up into a single Service Level Objective (SLO) we call “Query Assistant Availability.” It tells us that Query Assistant produces a valid query 95% of the time.
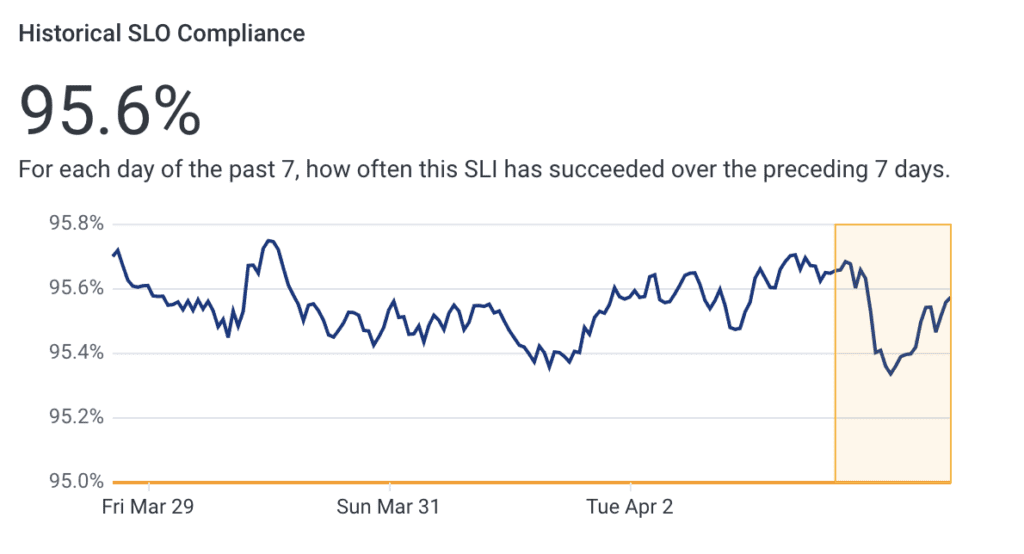
But what about the other 5%?
Where does it go wrong?
Charity scrolls down on the SLO screen, to the view where the magic really happens. We call this the SLO BubbleUp View.
BubbleUp looks at every Query Assistant request and compares every single dimension from the requests that violate the SLO against the baseline events that satisfy the SLO, and then sorts and diffs them so the differences come to the top.
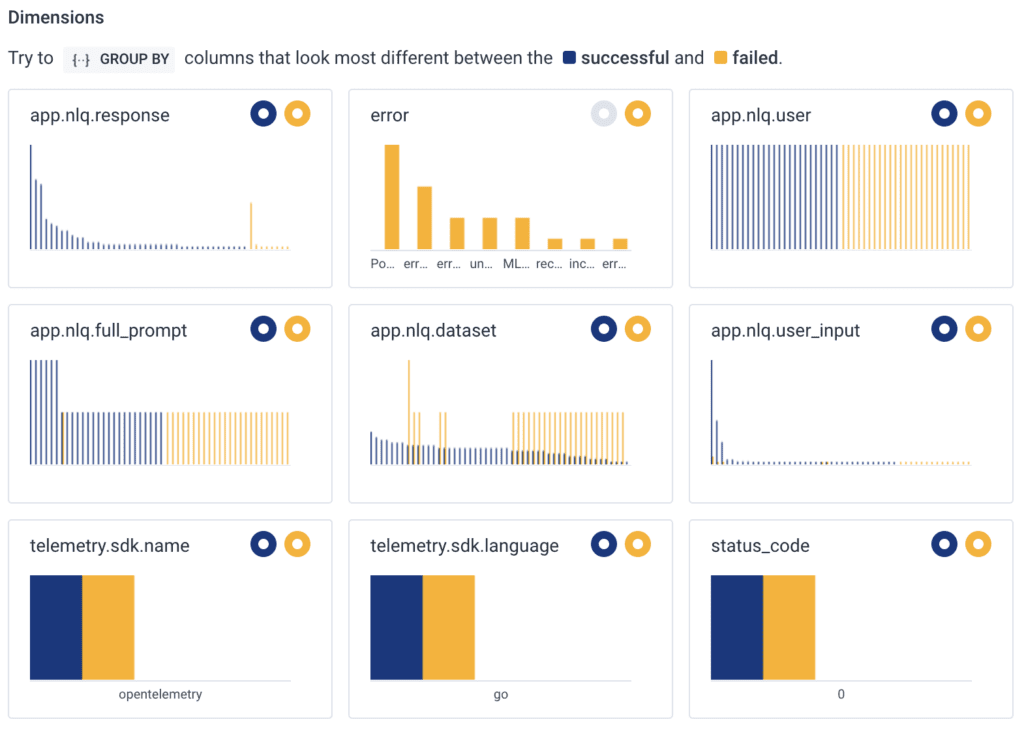
This answers the question: “What is different about the ones I most care about?”
Charity sees that “Error” is one of the most different fields, and there are several different values. She mouses over one of them. It says “unexpected end of JSON input.”
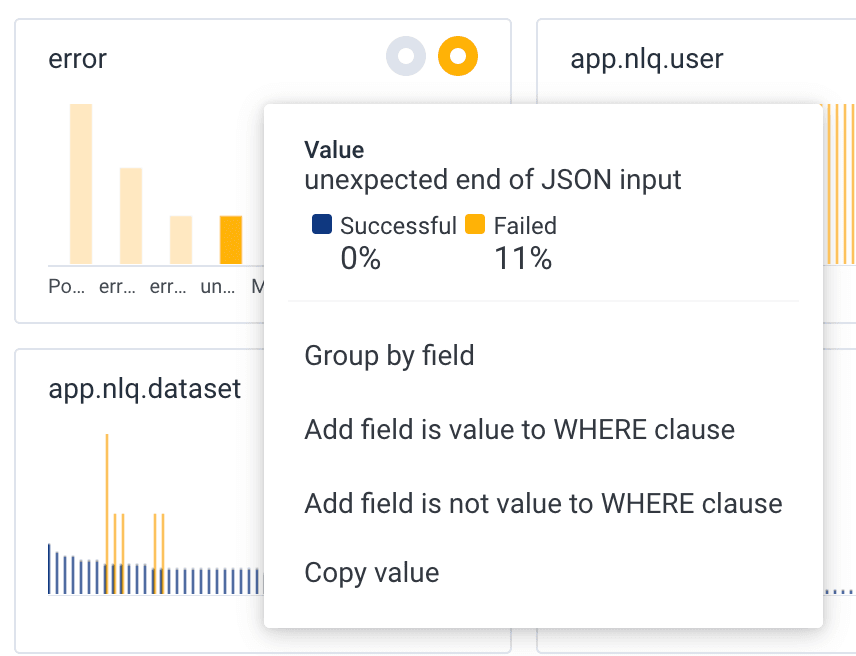
Charity clicks to add this field as a filter, and now she has a graph of only requests with this error.

Now, she’d like to see the end of that JSON input. She types something like “also show the user input and response” into Query Assistant.
Query Assistant usually adds the right fields to the GROUP BY, and now they appear in the table. There’s something suspicious about the end of that app.nlq.response value.
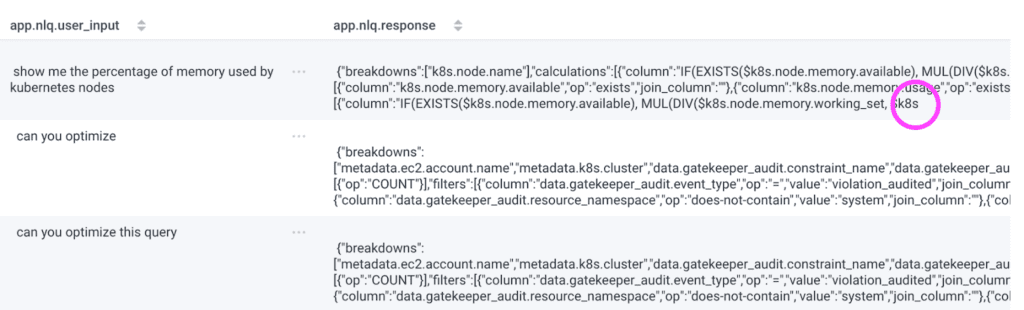
That response is truncated! Indeed, the JSON has ended unexpectedly.
What’s our limit on output tokens? Charity asks Query Assistant “also group by the output config.”
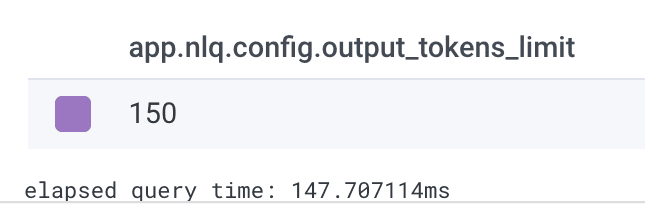
Looks like our configuration was just for 150 tokens from the LLM, and clearly that’s not enough!
That seems like an issue Charity should take to the team.
This is observability.
This flow shows just how important observability is when you’re building with generative AI. We found this problem to fix, but new ones will surely come up.
When you can use SLOs to identify something you find interesting, then slice and dice and explore your data, you can quickly get to the bottom of any issue—even if it’s totally new and unknown.
With Honeycomb, you can develop AI applications with confidence, in Google Cloud or any other environment. Try it today for free.
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.