
You may have seen the Honeycomb white paper on metrics, and want to use the power of Honeycomb with metrics. Sending infrastructure metrics data to Honeycomb has always been possible, but with our focus on debugging the user experience inside the application, it isn’t the first or most obvious thing to do. This post will discuss why we use metrics in general and how to think about metrics in Honeycomb.
Before we dig into how Honeycomb approaches infrastructure observability, let’s break down some of the deficiencies with traditional metrics platforms.
Metrics are Hard to Use
A dashboard full of charts updating in real time is pretty and easy on the eyes. Unfortunately the next step beyond looking at that dashboard, and each step thereafter, gets harder, and harder …and harder. Your dashboard might be able to identify the existence of an issue, but that doesn’t help you solve it. This is why in all aspects of observability we encourage adding more context. For metrics, adding context results in multiplying your mental combinations of metric names with services. Since not all services are used or categorized in the same way, we need to start adding tags to categorize the data. To add to the confusion, not all metrics have the same tags, and tags even vary by operation within a service.
Discovery is hard in metrics.
It would be convenient if every service and operation used the same metric and tag names, but that’s nowhere near reality. In a metrics platform, any given data element has a single metric name with a set of tags. Each one in a pool of seemingly endless combinations of metric and tag names. Metrics are the haystack.
The “Metrics” Model
Let’s break down how traditional metrics work: one data record per metric per resource per collection interval. The separation between all these disparate records forces you to do some mental gymnastics to get all the related data for a given resource. Metrics stored in this way are optimized for trend charts and dashboards, not for debugging. While these graphs can be useful, they don’t give you observability—they require knowing ahead of time the thing you need to look for. You can’t ask novel questions.
Put this into practice. In traditional form, each metric is an independent thing. Each one individually addressable by itself. It will contain attributes. Sure, these attributes can be matched with other individually addressable metrics,but you still need to do that mapping. As the user doing the debugging, you need to be aware of any other individual metrics collected from that same resource that might be relevant.
When you’re doing this investigative work, you need to have specific domain knowledge about how the service endpoints interact with each other. Using metrics, you also need to have domain knowledge of all the contextually relatable metrics, within and across those endpoints. So now you need a data dictionary just to deal with the wealth of individual elements to look at. Do you know who doesn’t like to update your data dictionary? The same engineers who add more data to your observability platform.
Managing Namespaces
Let’s pretend for a few moments you did build a data dictionary for your metrics, and you’ve managed to get your engineering team to keep it up to date. So when something happens, on-call can pull up the data dictionary and they find what they need. As the on-call engineer, you identify 58 different metrics that apply to the hosts/runtimes serving up the application. Some metrics are counters, others are gauges. Some are system metrics under a system. prefix. Another set is about the Java runtime under a java. prefix. You can filter these under a common host tag.
Then you realize that java. is a wide space and contains all kinds of metrics, so doing a query on java.* is prohibitive on your metrics platform. You go back to the data dictionary to make changes and refactor the metrics namespace.
Later you realize you have more than a few hosts running your application, which means selecting on the host tag doesn’t quite cut it anymore. So you add more tags. More things to remember or look up in the data dictionary, so you can join the data that varies by service type and function.
After that you realize you have more than a couple of different services running on multiple different infra combinations, each with their own metrics sets. Your data dictionary has become a 30+ page document.
Eventually you realize no one uses the fucking data dictionary. Finding correlated data in the metrics platform is hoping someone else created a dashboard somewhere in a big pile of dashboards… because moar metrics.
How We Got Here
Let’s rewind that metrics model, and go back to what it is we are trying to do: We want to understand the complete state of our infrastructure resource.
We started out by collecting multiple measurements about our resource. At first we only had a handful of measurements and a handful of hosts. Everything was given a unique ID and stored separately using traditional row-based data storage systems that rely on indexes to find attributes.
As time passed, we required increased visibility to know as much as we can from our applications, plus we grew the number of things we measure. With microservices, the variability of these attributes grew exponentially. Now we have a mess of things that relate to each other in different ways, all of which require the operator to have knowledge about.
Resource Events to the Rescue
At Honeycomb we use an event data structure to intrinsically relate all these items at the time we collect them. For infrastructure observability, we have resource events: one event for all metrics of a given resource per collection cycle. A single wide event contains everything you need to know about the state of the resource.
Wide events keep everything contained into a single consumable item. No more need to look up how to join other metrics, that’s done for you. Everything you need, right there.
{
"hostname": "app1-prod",
"region": "us-east-1",
"cpu.utilization": 0.15,
"memory.used": 84673525,
...
"java.threads": 12,
"java.gc_time": 38,
}
Honeycomb works wonders with these wide events, especially when paired with the BubbleUp feature. Using these resource events, users can quickly see how an infrastructure metric relates to other metrics on the same source(s).
An infrequently-used function of Honeycomb’s BubbleUp feature is how you can correlate your selection with distributions on other numeric attributes. For example, you might look at whether memory utilization correlates with high CPU and low disk activity. The histogram distribution for numeric attributes will show up just below the string attributes, in the Measures section of the BubbleUp results.
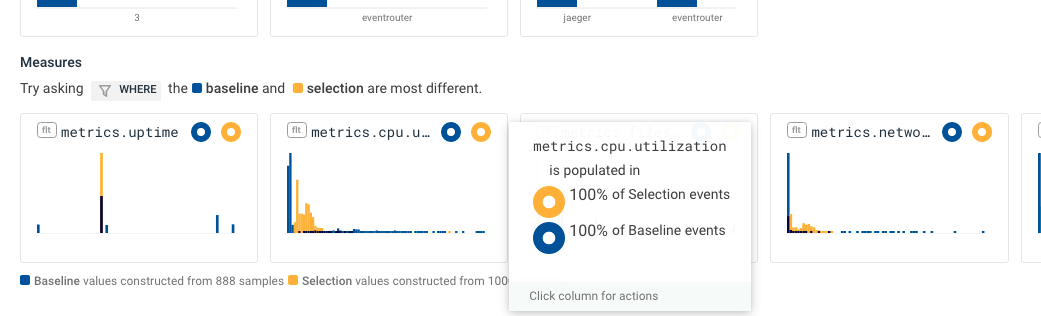
Imagine you have an incident where your application latency has gone up. Your infrastructure resource events in Honeycomb allow you to see elevated memory usage. Now you use Honeycomb’s BubbleUp feature selecting the high memory usage data, and see that other metrics are correlated on those same resources.
Try It Out Yourself!
Check out the recent HoneyByte post on how to use the new Kubernetes agent to gain observability into your infrastructure.





