Observability is more than tooling. Of course having the right tools in place so you can ask arbitrary questions about your environment, without having to know ahead of time what you wanted to ask, is critical. Finding the unknown unknowns is the coveted observability sweet spot. However, it’s the actual doing it that proves a bit more challenging especially when you’re weaning off legacy tools.
Teams must decide how to start their observability journey and decisions not only impact tool choices but also which questions need to be addressed at what stages in the software delivery cycle. When everyone learns by asking new questions, systems begin to stabilize and the team spends more time on innovation and less on reactive fixing and technical debt.
To understand how the market is adopting observability driven development, we commissioned a research study with Clearpath Strategies, the same group that advised DORA reports. The hypothesis going in was:
Adopting observability tools, site reliability engineering (SRE) practices and a culture of shared ownership translates to efficiencies across the software engineering cycle, better end-user experiences and ultimately Production Excellence.
Observability is much more powerful when you apply the right mindset and clear processes in conjunction with tooling. In fact they reinforce each other — assuming you are using tools purposely designed to address observability use-cases. Our research tells us that most teams adopt a handful of tools across disparate teams to accomplish daily tasks. It’s the juggling of those different tools that brings confusion and frustration leading to tool bloat, an oft-heard complaint which slows everything down.
Dev.to’s Molly Struve shared this specific problem with Liz Fong-Jones during a shared HoneyByte session: “You’d look at one service, you’d see a spike, but that was all the information you’d get. So then you’d have to go to the other services and try to line up when the spike happened.” Molly successfully cut down from 7 different tools to 3 which gave the team way more clarity and massive efficiency gains.
Introducing The Observability Spectrum:
Our research gathered 406 responses from teams of varying sizes with a majority (57%) in SRE/DevOps roles. Additionally 1 in 3 are with large enterprises (>1,000 employees).
We began by assessing self-reported observability practices: org-wide practices, team-specific practices, and observability tooling. From there, weighted inputs across 35 questions measured tooling, capabilities, and processes, shifting participants up and down the observability spectrum. In the end, we identified 5 distinct groups across a five-point scale to address the following critical areas:
- Ability to proactively notice and catch bugs before fully deployed to prod?
- Can you / your org deploy code on a predictable schedule?
- Can people at your org efficiently debug production issues?
- Can people at your org understand user experience and behavior?
- Do you have a plan and process to reduce tech debt?
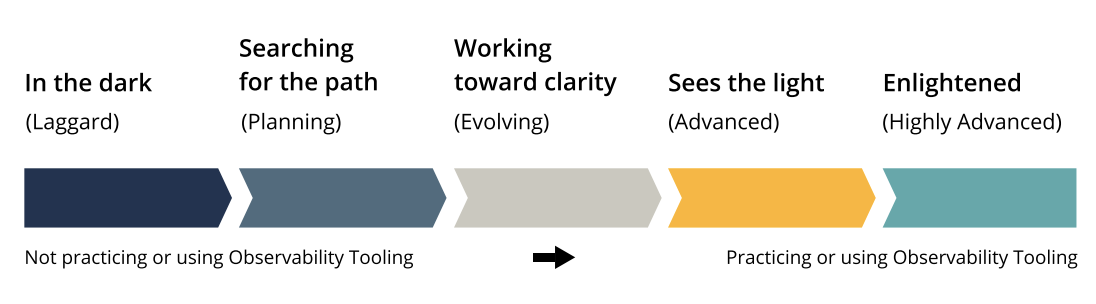
The report goes into a lot more detail on where teams & orgs fall on their adoption of observability tooling and practices. Surprisingly 80 Percent of Teams Intend to Practice Observability within Two Years. The market definitely sees the value and has plans to adopt. About a quarter (27%) fall into the Advanced or Highly Advanced groups and to them the value is clear.
Fully 90% of those who use observability tooling say those tools are important to their team’s software development success, including 39% who say observability tools are very important. While many more participants currently use tooling tangential to observability, e.g., monitoring (84% use), log management (79% use), and error reporting (71% use)–each is perceived as less impactful to their software development success and ability to achieve production excellence.
35% are Working toward Clarity (Evolving)
Probably the most interesting finding tells us that 1 in 3 respondents are on the path to achieving observability but still need more clarity across the team and organization to fully adopt tooling and practices.
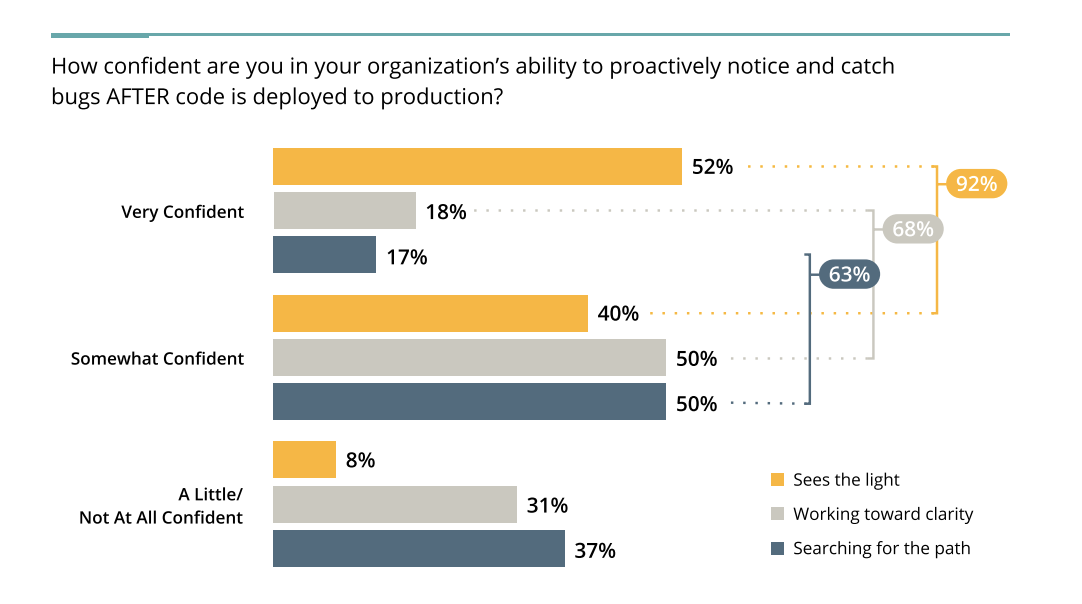
Proactively Notice & Catch Bugs AFTER code is deployed:
Compared to advanced teams (yellow), this cohort isn’t as confident in noticing and catching bugs AFTER code hits production – only 68% say they are very or somewhat confident compared to 92% of advanced teams.
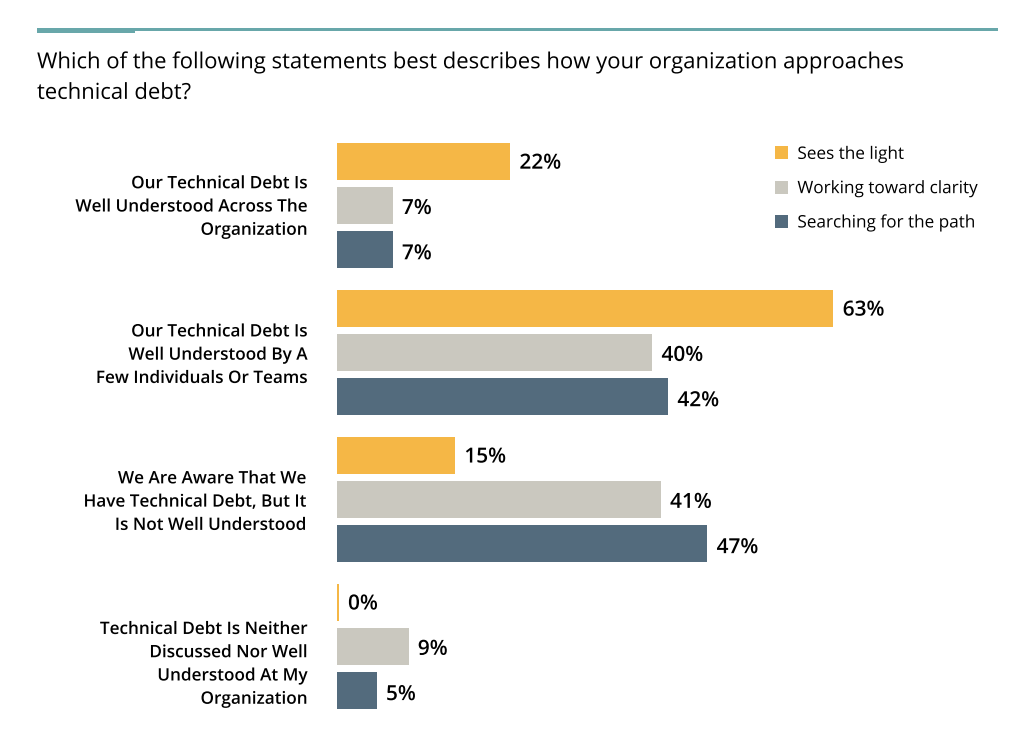
Know Where Tech Debt Lies?
When asked about the ability to detect and understand where tech debt lies, only 7% of the Evolving group say it is “well understood” compared to 22% of advanced observability teams.
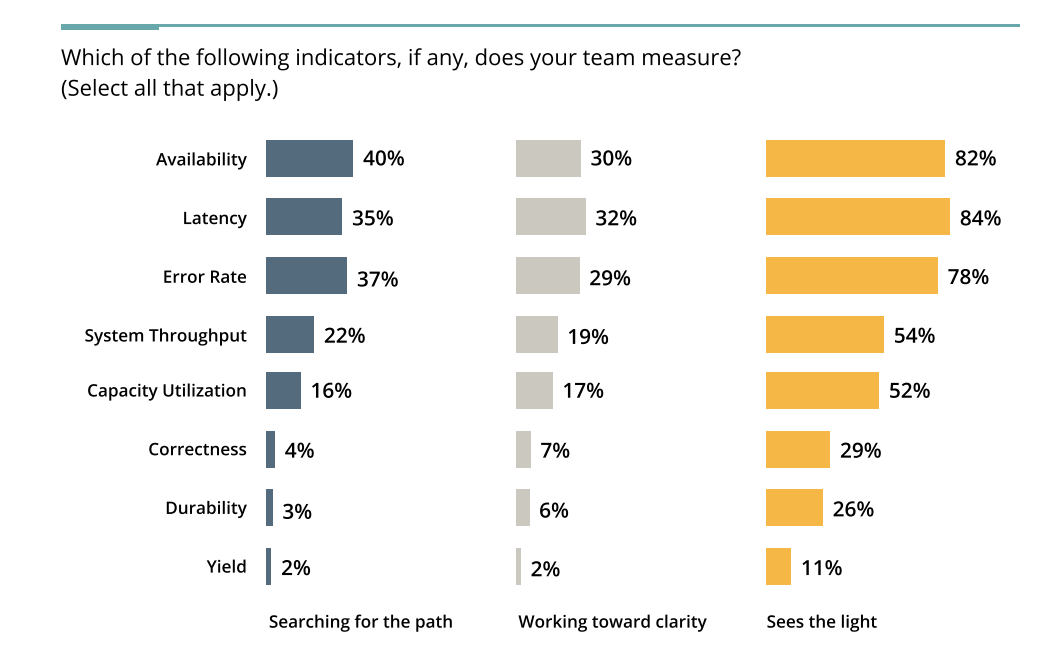
Set Service Level Indicators & Measures for SLOs?
78% of Advanced teams report setting and measuring SLOs, versus only 38% of those with less mature observability practices. Advanced teams are also measuring more indicators than their less advanced counterparts.
Observability is a journey. It takes time for the entire team to adopt new practices and adjust to a mindset of shared ownership. It’s easy to get started and even better if you bring along team-mates to understand what’s happening in production or perhaps begin with a dev or test environment. Instrumenting is an iterative process to get the right data in so you can start querying and introspecting. Go easy on yourself at the outset. There will be new learnings every step of the journey.
Thanks to everyone who participated in this important survey. As we understand more about the community’s needs and questions, we will work hard to get answers and deliver the right assets for this important journey that will ultimately reduce toil and improve team happiness.
Big shout-out to the team that helped craft and complete this study. Thanks for all the hard work and patience Danyel Fisher, Liz Fong-Jones, pie and Kate McCarthy
Where are you on your observability journey? Download the PDF of the full report.





