Get all your observability data in one unified platform with limitless possibilities.
Discover why Honeycomb is the better choice for your engineers, your customers, and your bottom line.
Explore our latest blogs, guides, training videos, and more.
Give all software engineering teams the observability they need to eliminate toil and delight their users.
Chris Lasher | Mar 05, 2024
In this post, Chris describes how to send OpenTelemetry (OTel) data from an AWS Lambda instance to Honeycomb.
Fred Hebert | Feb 29, 2024
There are countless challenges around incident investigations and reports. Aside from sensitive situations revolving around blame and corrections, tricky problems come up when having discussions with multiple stakeholders. The problems I’ll explore in this blog—from the SRE perspective—are about time pressures (when to ship the investigation) and the type of report people expect.
Alex Boten | Feb 28, 2024
There is so much good work that OpenTelemetry has done in the software industry, specifically around the domain of observability, in the last five years. Bringing users and vendors together to define the future of telemetry? Check! Unify logs, traces, and metrics under a completely vendor-neutral API? Check! Deprecate other standards by bringing their collaborators to the table to ensure their use cases are met? CHECK!
Jessica Kerr | Feb 26, 2024
In twenty years of software development, I did not have the privilege of being on call, of tending to my software in production. I’ve never understood what “APM” means. Anybody can tell me what it stands for—Application Performance Monitoring (or sometimes, the M means Management)—but what does it mean? What do people use APM for? Now, I work at an observability company—and still, no one can give me a satisfying definition of “APM.” So I did some research, and now the use of APM makes sense from a few angles.
Rox Williams | Feb 22, 2024
Birdie’s platform is a complex software system that covers a lot of ground—from care management and rostering to HR and finance. To ensure the platform runs smoothly and the team can swiftly fix issues, the company depends on a smart observability tool to understand its performance and direct debugging efforts. However, since it’s not clear upfront which dimensions are going to be valuable for debugging purposes, the team needs the ability to adeptly query and explore the data.
Phillip Carter | Feb 20, 2024
Back in May 2023, I helped launch my first bona fide feature that uses LLMs in production. It was difficult in lots of different ways, but one thing I didn’t elaborate in several blog posts was how lucky I was to have a coherent way to get the data I needed to make the feature useful for users.
Rox Williams | Feb 16, 2024
Application performance monitoring, also known as APM, represents the difference between code and running software. You need the measurements in order to manage performance.
Jason Harley | Feb 14, 2024
We're delighted to introduce our new Ingest API Keys, a significant step toward enabling all Honeycomb customers to manage their observability complexity simply, efficiently, and securely. Ingest Keys are currently available for Environment & Services customers, with Classic support and programmatic key management capabilities under development and coming soon!
Austin Parker | Feb 06, 2024
In today’s economic and regulatory environment, data sovereignty is increasingly top of mind for observability teams. The rules and regulations surrounding telemetry data can often be challenging to interpret, leaving many teams in the dark about what kind of data they can capture, how long it can be stored, and where it has to reside.
Jessica Kerr | Feb 02, 2024
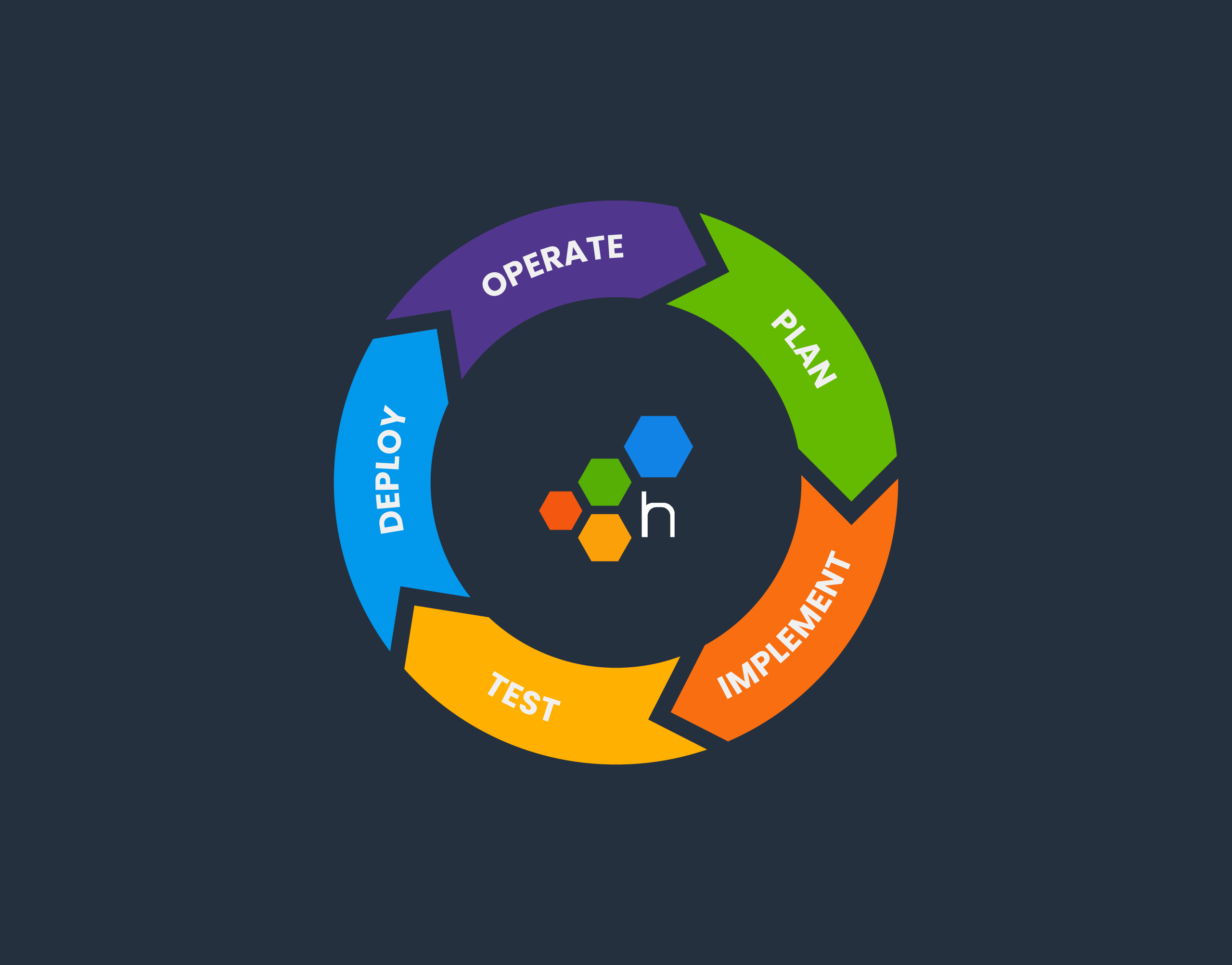
The software development lifecycle (SDLC) is always drawn as a circle. In many places I’ve worked, there’s no discernable connection between “5. Operate” and “1. Plan.” However, at Honeycomb, there is.
Mike Terhar | Feb 01, 2024
When you have questions about your software, telemetry data is there for you. Over time, you make friends with your data, learning what queries take you right to the error you want to see, and what graphs reassure you that your software is serving users well. You build up alerts based on those errors. You set business goals as SLOs around those graphs. And you find the balance of how much telemetry to sample, retaining the shape of important metrics and traces of all the errors, while dropping the rest to minimize costs.
Rox Williams | Jan 29, 2024
At Honeycomb, we are very concerned about privacy and data sovereignty—it’s something we take very seriously, and in an effort to serve our customers better, we’re thrilled to announce that we now offer data residency in Europe.