Get all your observability data in one unified platform with limitless possibilities.
Discover why Honeycomb is the better choice for your engineers, your customers, and your bottom line.
Explore our latest blogs, guides, training videos, and more.
Give all software engineering teams the observability they need to eliminate toil and delight their users.
Mike Terhar | Nov 22, 2023
A lot of reasoning in content is predicated on the audience being in a modern, psychologically safe, agile sort of environment. It’s aspirational, so folks who aren’t in those environments may feel like the path there includes doing “the new thing” or using “the new tool.” If you write software and your employer hasn’t caught up to all the newest, best ways to work, I hope this pragmatic post helps you sleep better at night.
Emil Protalinski | Nov 17, 2023
Software systems are increasingly complex. Applications can no longer simply be understood by examining their source code or relying on traditional monitoring methods. The interplay of distributed architectures, microservices, cloud-native environments, and massive data flows requires an increasingly critical approach: observability.
Fred Hebert | Nov 14, 2023
As someone living the Honeycomb ops life for a while, SLOs have been the bread and butter of our most critical and useful alerting. However, they had severe, long-standing limitations. In this post, I will describe these limitations, and how our brand new feature, budget rate alerts, addresses them.
Austin Parker | Nov 10, 2023
Stop me if you’ve heard this one before: you just pushed and deployed your latest change to production, and it’s rolling out to your Kubernetes cluster. You sip your coffee as you wrap up some documentation when a ping in the ops channel catches your eye—a sales engineer is complaining that the demo environment is slow. Probably nothing to worry about, not like your changes had anything to do with that… but, minutes later, more alerts start to fire off.
Mike Terhar | Nov 08, 2023
In telemetry jargon, a pipeline is a directed acyclic graph (DAG) of nodes that carry emitted signals from an application to a backend. In an OpenTelemetry Collector, a pipeline is a set of receivers that collect signals, runs them through processors, and then emits them through configured exporters. This blog post hopes to simplify both types of pipelines by using an OpenTelemetry extension called the Headers Setter.
Natalie Friedman | Nov 01, 2023
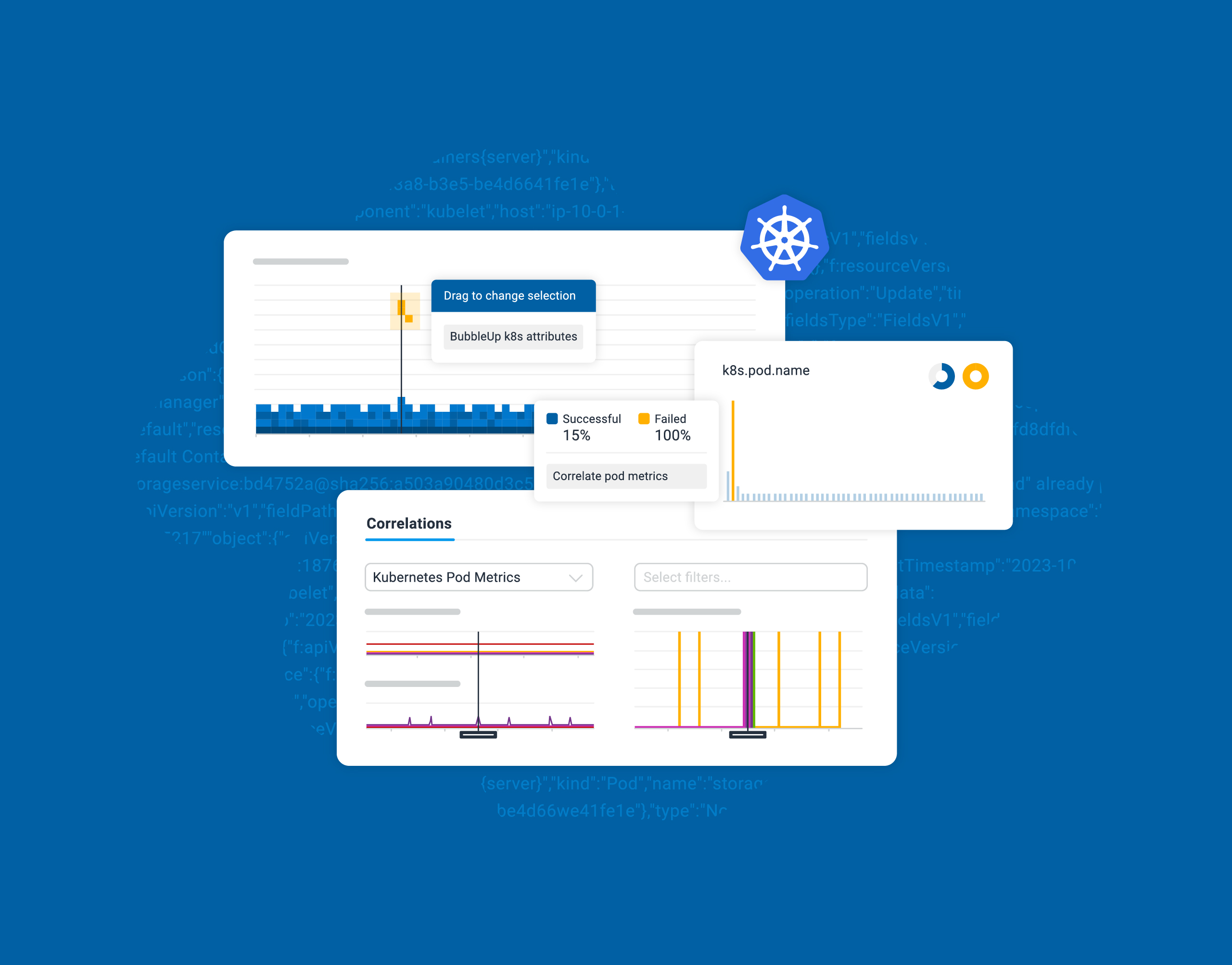
In our continuous journey to support teams grappling with the complexities of Kubernetes environments, we’re thrilled to announce the launch of Honeycomb for Kubernetes, a dedicated solution designed to bridge the growing divide between infrastructure/platform teams and application developers. This is available to all plans (including Free!) at no additional cost.
Martin Thwaites | Oct 30, 2023
You probably know that we have a generous free plan that allows you to send 20 million events per month. This is enough for many of our customers. In fact, some have developed neat techniques to keep themselves underneath the event limit. I’m going to share one way here—hopefully no one at Honeycomb notices!
Michael Sickles | Oct 26, 2023
Large Language Models (LLMs) are all the rage in software development, and for good reason: they provide crucial opportunities to positively enhance our software. At Honeycomb, we saw an opportunity in the form of Query Assistant, a feature that can help engineers ask questions of their systems in plain English. But we certainly encountered issues while building it—issues you’ll most likely face too if you’re building a product with LLMs—with the main one being, how do we get the model to return data in a way that works with our softwa
Tyler Wilson | Oct 24, 2023
Before Massdriver, Dave worked in product engineering where he was constantly bogged down with DevOps toil. He spent his time doing everything except what he was hired to do: write software. He founded Massdriver to help engineering teams build and release faster while limiting and managing the complexity of the cloud.
Austin Parker | Oct 16, 2023
Who is software for? It’s an interesting question, because there’s an obvious answer. It’s for the users, right? If your job is to write software, then it’s implied that the most important thing you should care about is the experience people have when they use your software. I think this is a bit of an over-simplification, though. Yes, we build software for our users, but we also build it for ourselves. At some level, I believe all developers are in it for themselves. They like to see the thinking rock respond to the commands they give it. There’s a level of intellectual curiosity that grips many of us when we write software, the quiet joy of getting one over on this unfeeling collection of silicon and cobalt, bending it to our will and mastering its arcane language.
Martin Thwaites | Oct 12, 2023
Kubernetes has been around for nearly 10 years now. In the past five years, we’ve seen a drastic increase in adoption by engineering teams of all sizes. The promise of standardization of deployments and scaling across different types of applications, from static websites to full-blown microservice solutions, has fueled this sharp increase.
Savannah Morgan | Oct 11, 2023
Understanding production has historically been reserved for software developers and engineers. After all, those folks are the ones building, maintaining, and fixing everything they deliver into production. However, the value of software doesn't stop the moment it makes it to production. Software systems have users, and there are often teams dedicated to their support.