Get all your observability data in one unified platform with limitless possibilities.
Discover why Honeycomb is the better choice for your engineers, your customers, and your bottom line.
Explore our latest blogs, guides, training videos, and more.
Give all software engineering teams the observability they need to eliminate toil and delight their users.
Tyler Wilson | Jun 05, 2023
Frontend observability is a tricky problem. No website is free of errors or slowdowns; sites break down in weird ways for all kinds of reasons. Accounting for every possible combination of platform, browser, extensions, and (sometimes baffling) user behavior would be an impossible task. How do we decide which errors are important? One useful framework for making these frontend development decisions is customer-centric observability.
Mike Terhar | Jun 01, 2023
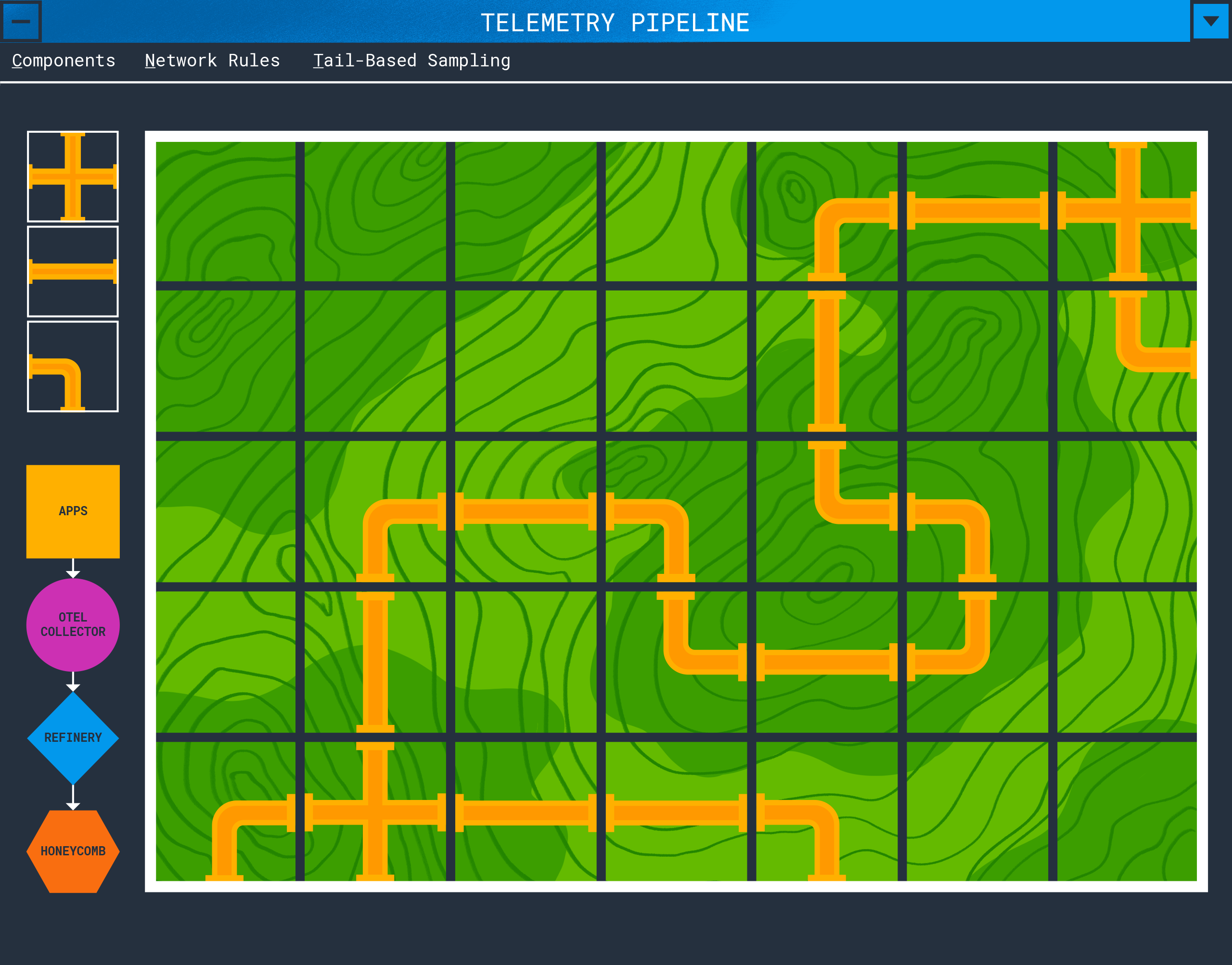
In a simple deployment, an application will emit spans, metrics, and logs which will be sent to api.honeycomb.io and show up in charts. This works for small projects and organizations that do not control outbound access from their servers. If your organization has more components, network rules, or requires tail-based sampling, you’ll need to create a telemetry pipeline.
Rebecca Carter | May 31, 2023
When people hear the word “migration,” they typically think about migrating from on-prem to the cloud. In reality, companies do migrations of varying types and sizes all the time. However, many teams delay making critical migrations or technical upgrades because they don’t have the proper tools and frameworks to de-risk the process.
Rebecca Carter | May 30, 2023
Modern software development—where code is shipped fast and fixed quickly—simply can’t happen without building observability in before deployments happen. Teams need to see inside the code and CI/CD pipelines before anything ships, because finding problems early makes them easier to fix. And don’t take “easier to fix” lightly: incidents found late not only impact the customer experience (and perhaps their loyalty), but they also hit developer productivity and job satisfaction hard.
Nir Gazit | May 30, 2023
At Traceloop, we’re solving the single thing engineers hate most: writing tests for their code. More specifically, writing tests for complex systems with lots of side effects, such as this imaginary one, which is still a lot simpler than most architectures I’ve seen.
Phillip Carter | May 26, 2023
There’s a lot of hype around AI, and in particular, Large Language Models (LLMs). To be blunt, a lot of that hype is just some demo bullshit that would fall over the instant anyone tried to use it for a real task that their job depends on. The reality is far less glamorous: it’s hard to build a real product backed by an LLM.
Valerie Silverthorne | May 24, 2023
The pressure on today’s development teams is real: innovate, release quickly, and then do it all again, only faster. Is it any surprise that studies are showing 83% of software developers are feeling burnout? We’re here to remind you that it doesn’t have to be this way.
Jessica Kerr | May 23, 2023
Honeycomb recently released our Query Assistant, which uses ChatGPT behind the scenes to build queries based on your natural language question. It's pretty cool. While developing this feature, our team (including Tanya Romankova and Craig Atkinson) built tracing in from the start, and used it to get the feature working smoothly.
Valerie Silverthorne | May 18, 2023
If debugging has sucked the soul out of your engineers, we’ve got the answer: event-based observability. Instead of spending hours and resources trying to find out why an alert is sounding, event-based observability can quickly surface the correct cause of any issue. Here are five concrete ways teams can save time, money, and sanity using Honeycomb’s event-based approach to observability.
Tesha Richardson | May 17, 2023
The Honeycomb design team began work on Lattice in early 2021. Over several months, we worked to clean up and optimize typography, color, spacing, and many other product experience areas. We conducted an extensive audit of all components, documenting design inconsistencies and laying the foundation for a sustainable design system. However, a more extensive evaluation and audit were necessary before updating or developing components.
Jamie Danielson | May 16, 2023
Also known as confidence testing, smoke testing is intended to focus on some critical aspects of the software that are required as a baseline. The term originates in electronic hardware testing; as my colleague Robb Kidd stated, “We want to apply power and see if smoke comes out.” If a smoke test fails, there is almost definitely a problem to address. If it passes, it doesn’t necessarily mean there is no problem, but we can feel confident that the major functionality is okay.
Michael Wilde | May 11, 2023
A while ago, we added Metrics to our observability platform so teams could easily see system information right next to their application observability data—no tool or team switching required. So how can teams get the most out of metrics in an observability platform? We’re glad you asked! We had this conversation with experts at Heroku. They’ve successfully blended metrics and observability and understand what is most helpful to know. Here are three strategies to maximize the benefits of Honeycomb Metrics.