All-in-one observability for teams who manage software that matters.
See how observability with Honeycomb compares to traditional APM providers.
Explore our latest blogs, guides, training videos, and more.
Give all software engineering teams the observability they need to eliminate toil and delight their users.
Guest Blogger | Dec 07, 2022
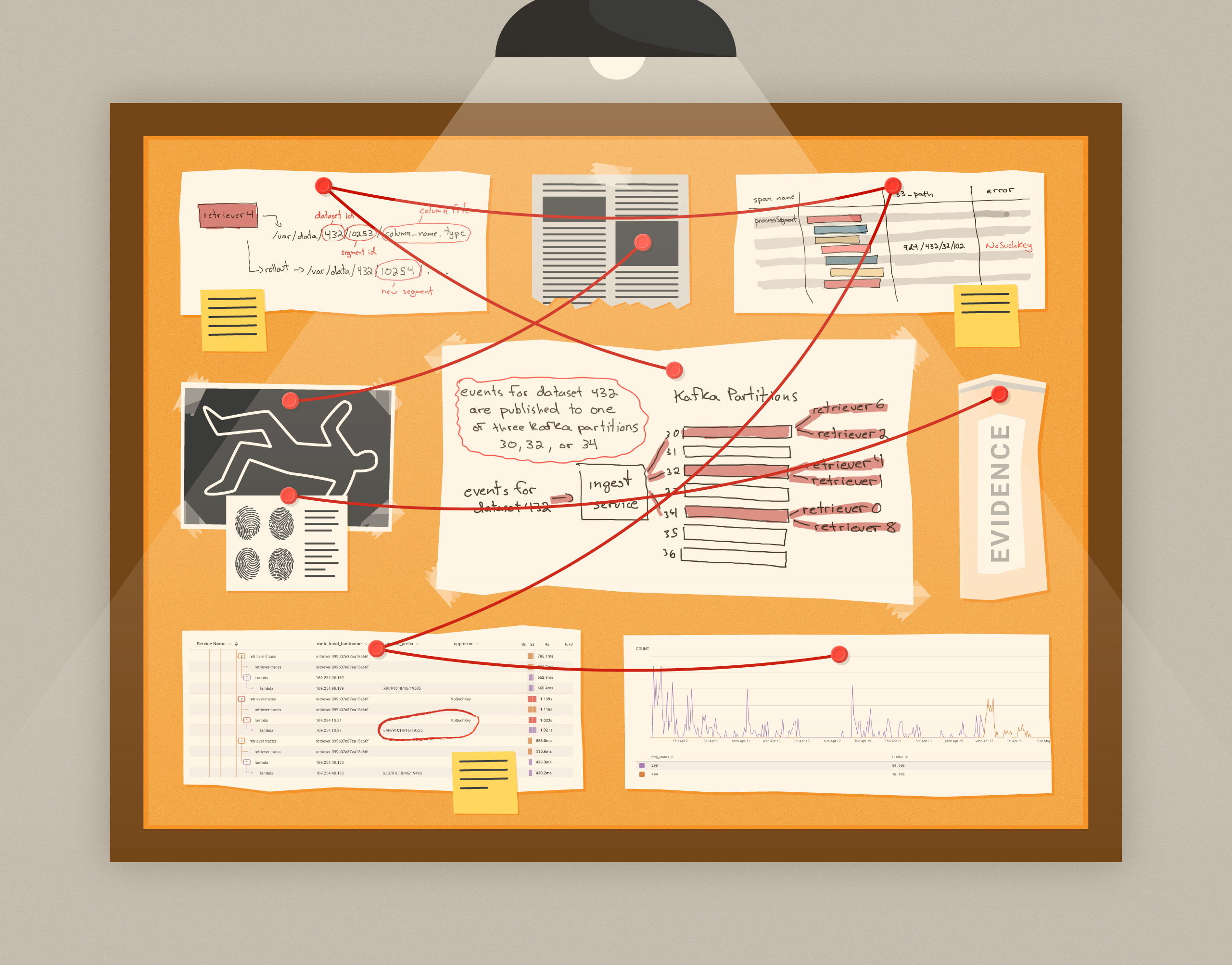
Bugs can remain dormant in a system for a long time, until they suddenly manifest themselves in weird and unexpected ways. The deeper in the stack they are, the more surprising they tend to be. One such bug reared its head within our columnar datastore in May this year, but had been present for more than two years before detection.
George Miranda | Nov 28, 2022
Today, we’re announcing the expansion of Honeycomb integrations with various AWS services. This update now covers a much wider swath of AWS services, makes it easier than ever to integrate your AWS stack with Honeycomb, and with our new BubbleUp enhancements, you’ll be identifying and debugging hidden issues in your AWS stack faster than ever.
Lex Neva | Nov 23, 2022
I joined Honeycomb as a Staff Site Reliability Engineer (SRE) midway through September, and it’s been a wild ride so far. One thing I was especially excited about was the opportunity to see Honeycomb’s incident retrospective process from the inside. I wasn’t disappointed!
Nathan Lincoln | Nov 18, 2022
With the introduction of Environments & Services, we’ve seen a dramatic increase in the creation of new datasets. These new datasets are smaller than ones created with Honeycomb Classic, where customers would typically place all of their services under a single, large dataset. This change has presented some interesting scaling challenges, which I’ll detail in this post, along with the solution we used, and how we leveraged Honeycomb’s own telemetry to scale Honeycomb.
Rebecca Carter | Nov 17, 2022
Intercom’s mission is to build better communication between businesses and their customers. With that in mind, they began their journey away from metrics alone and towards complete observability.
George Miranda | Nov 14, 2022
If you’re writing software today, then you likely use a CI/CD pipeline to build and test your code before deploying it to production. Having a fast and efficient build pipeline saves you development time, shortens feedback loops, and helps you ship features faster. Conversely, slow and unreliable build pipelines are full of lost productivity and sadness.
Nick Rycar | Nov 10, 2022
In our Feature Focus October 2022, we've updated documentation and derived columns, provided guides to make CI/CD easier, and more.
Reid Savage | Nov 09, 2022
One of the things that struck me upon joining Honeycomb was the seemingly laissez-faire approach we took towards internal SLOs. From my own research (beginning with the classic SRE book, following Google’s example), I came to these conclusions: -SLOs are strict. They aren’t as binding as an SLA, but burning through your error budget is bad. -SLOs/SLIs need to be documented somewhere, with a formal specification, and approved by stakeholders. -SLOs should drive customer-level SLAs. -Teams should be mandated to create a minimum number of SLOs for the services they own.
Martin Thwaites | Nov 03, 2022
In the last few years, the usage of databases that charge by request, query, or insert—rather than by provisioned compute infrastructure (e.g., CPU, RAM, etc.)—has grown significantly. They’re popular for a lot of the same reasons that serverless compute functions are, as the cost will scale with your usage. No one is using your site? No problem: you’re not charged.
Jess Mink | Oct 31, 2022
It may surprise you to hear, but Honeycomb doesn’t currently have a platform team. We have a platform org, and my title is Director of Platform Engineering. We have engineers doing platform work. And, we even have an SRE team and a core services team. But a platform team? Nope. I’ve been thinking about what it might mean to build a platform team up from scratch—a situation some of you may also be in—and it led me to asking crucial questions.
Liz Fong-Jones | Oct 27, 2022
Recently, Honeycomb held a roundtable discussion (available on demand) with Camal Cakar, Senior Site Reliability Engineer at Jimdo; Pierre Lacerte, Director of Software Development at Upgrade; and Kristin Smith, DevOps Engineer at Campspot. We talked about using OpenTelemetry and explained some important lessons the panelists learned—and are still learning in some cases. Here are five best practices based on these lessons and Honeycomb’s own experience with OpenTelemetry.
Nick Rycar | Oct 26, 2022
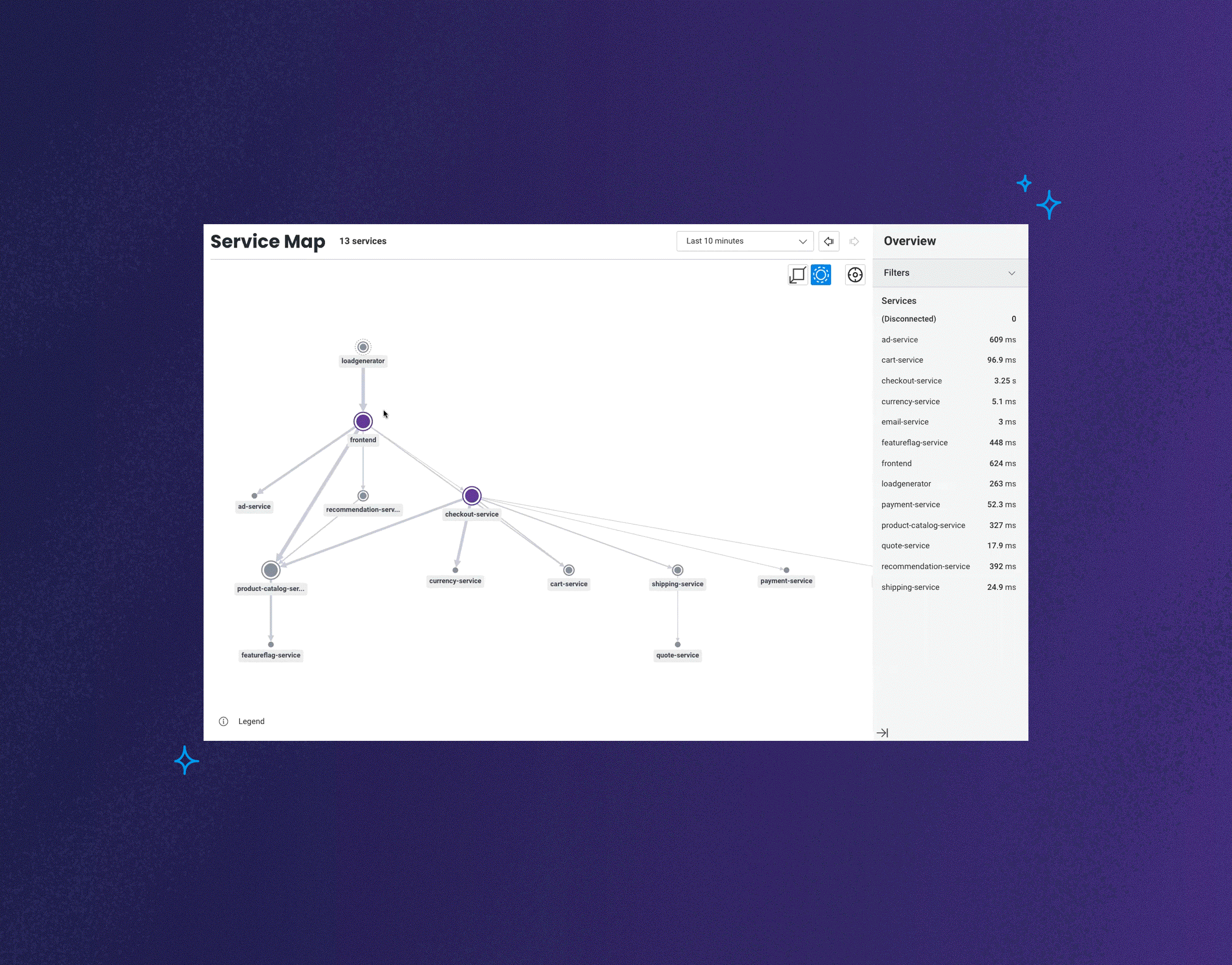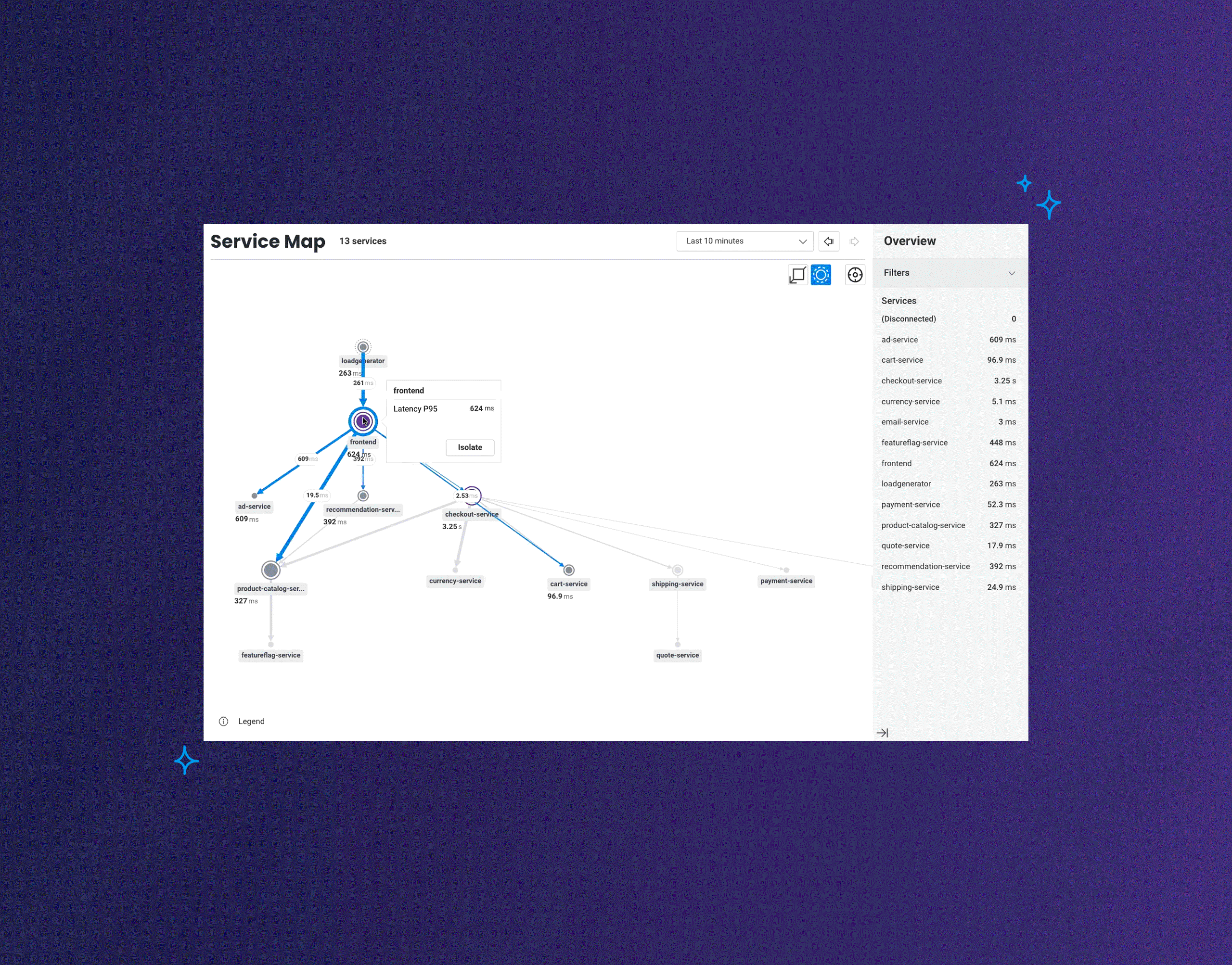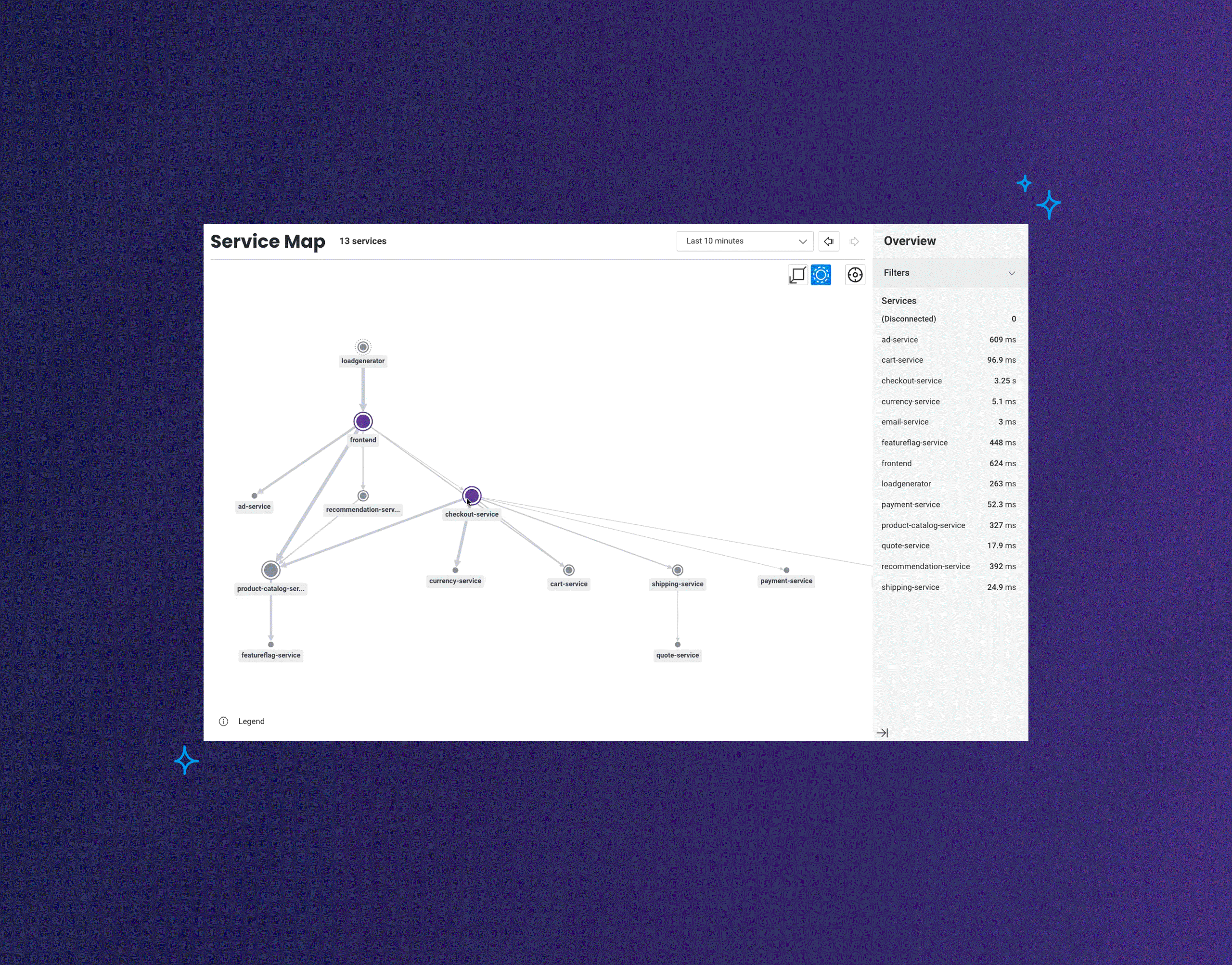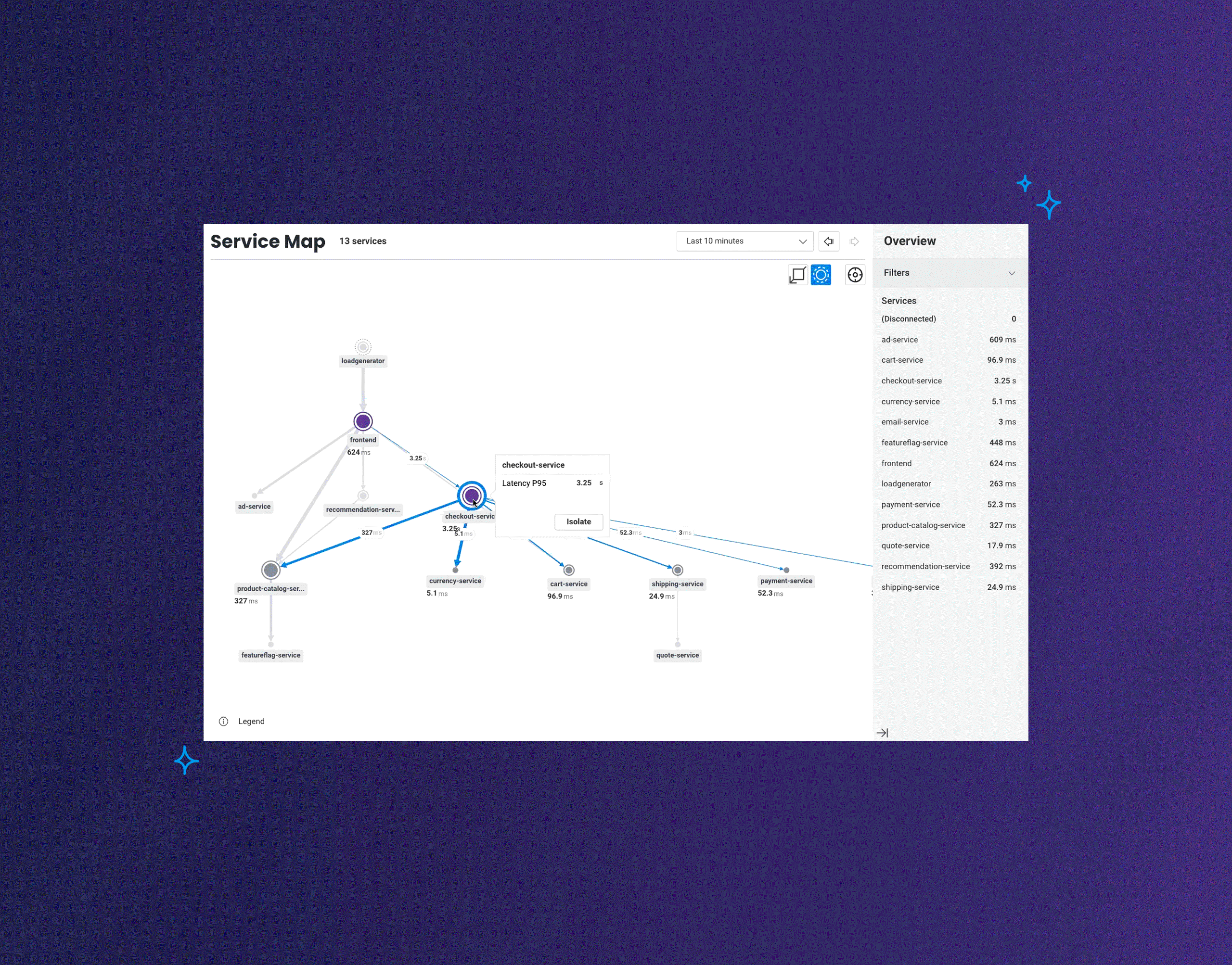
Today, we're announcing the launch of Honeycomb Service Map. This isn't your grandparent's version of a service map. This feature reimagines what it is that you want to know or investigate when looking at visualizations of how your services communicate with one another.