When you have questions about your software, telemetry data is there for you. Over time, you make friends with your data, learning what queries take you right to the error you want to see, and what graphs reassure you that your software is serving users well. You build up alerts based on those errors. You set business goals as SLOs around those graphs. And you find the balance of how much telemetry to sample, retaining the shape of important metrics and traces of all the errors, while dropping the rest to minimize costs.
Then sometimes, the shape of that data changes. Familiar field names disappear, replaced by others. More values appear that your queries did not expect. It is possible that alerts don’t fire, your sampling rates are disrupted, and your SLOs are wrong—how can this happen?
Right now, your telemetry might change shape when you update your libraries. OpenTelemetry libraries produce a lot of our telemetry; it outputs the spans we know we need (like HTTP requests) and populates them with fields everybody needs (like status code).
OpenTelemetry is changing some of these field names and values, as their HTTP Semantic Conventions (which specify names for common fields) just turned 1.0. When you update libraries, your telemetry can change shape.
At any time, your telemetry might change because you integrated a new service—maybe an acquisition—that has different standards. Or you might update your standards, and it will take a long time (admit it: forever) before they’re rolled out to the whole organization.
This post is here to help you deal with all of these changes. It will give you three ways of accommodating changes in both field names and field values, in three different places in your telemetry pipeline.
What to do when a field name changes
We design a lot of alerting, sampling, and boards around the names of fields. When that name changes, how can these continue to work?
A currently-unfolding example of this is http.status_code becoming http.response.status_code. OpenTelemetry changed these to conform to Elastic Common Schema (ECS) naming conventions, which sounds like a great idea. But our SLOs depend on the status code!
Because the field name update will not happen in every application at once, our changes need to accommodate both fields for a while. Look for suggestions on migrating completely to the new name later in this post.
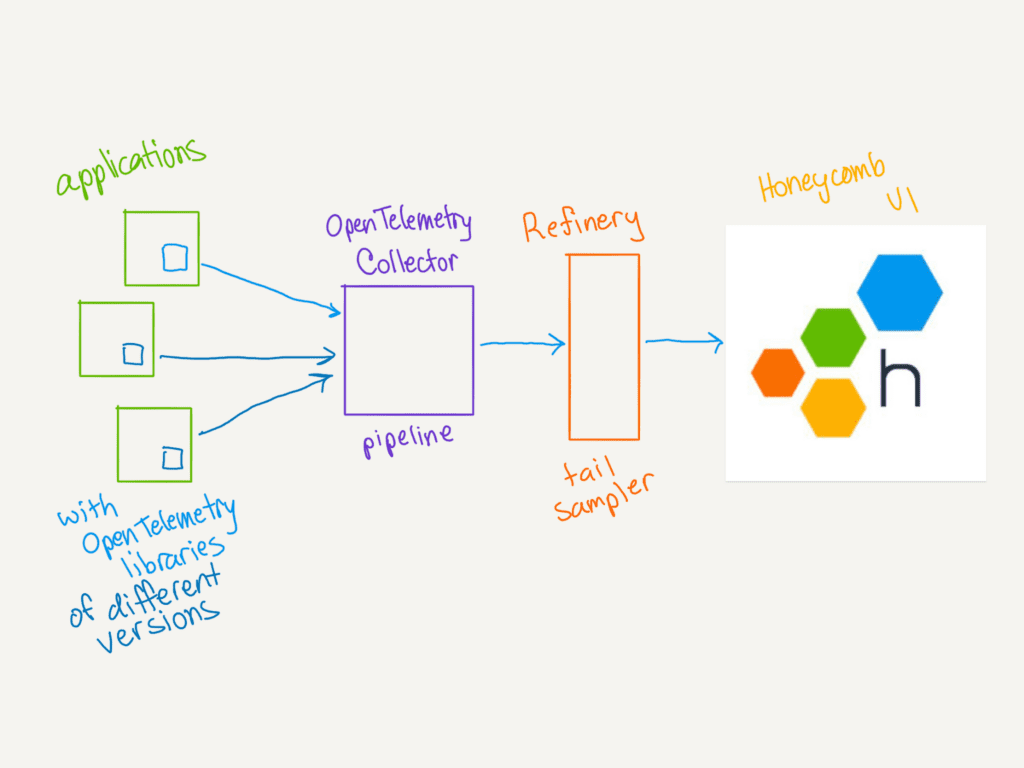
Let’s look at three places in our telemetry processing where we can accommodate the change: the Honeycomb UI, an OpenTelemetry Collector, and our sampling proxy, Refinery. You may not have all these components in your pipeline, so choices are good.
Accommodating field name changes in Honeycomb
You can change the queries in boards, triggers, and SLOs, but you can’t update them to use the new field until that’s populated in all telemetry. Instead, create a third field of your own name. This may be a good time to standardize on yourcompany.status_code, something you can apply more broadly than to HTTP spans.
Populate your own status code field as a derived column, using the COALESCE function to merge values from the old OpenTelemetry field and the new one.
COALESCE($http.status_code, $http.response.status_code)
Now your graphs use a field that you control, which is satisfying. You may choose to include values from other fields, or even translate them.
Adding a derived column is a quick solution to get you through the day, but it has its disadvantages. For instance, other derived columns can’t reference this one, so any Service Level Indicators in your SLOs have to include the whole COALESCE clause. Derived columns can span a Honeycomb environment, but if you use multiple environments, you have to create it in each. That’s okay if you use Terraform to keep environments consistent, but no fun by hand.
Consider adding your new field before the telemetry reaches Honeycomb.
Accommodating field name changes in the OpenTelemetry Collector (recommended)
Many Honeycomb customers pipe telemetry through an OpenTelemetry Collector before sending it to us. The Collector is a powerful pipeline component. It can normalize the attributes on spans for us.
You can define a new field with the values from both OpenTelemetry fields, or you can standardize on the new field name.
This portion of Collector configuration defines an attributes processor that populates the new field http.response.status_code with the value of http.status_code and then deletes the old field:
processors:
attributes/rename:
actions:
- key: http.response.status_code
from_attribute: http.status_code
action: insert
- key: http.status_code
action: delete
Don’t forget to incorporate that new processor in the definition of your traces pipeline.
pipelines:
traces:
processors: [attributes/rename, batch]
Accommodating field name changes in Refinery
Refinery lets you minimize cost by dropping a majority of traces, while keeping a representative sample—plus all the interesting ones. It is a sophisticated tail-based sampling proxy with flexible rules. For instance, most customers choose to keep all errors and very slow requests, while dropping most of the ordinary, successful ones.
That makes http.status_code an important field in sampling rules. For instance, you might keep about 10% of requests that return 200, while keeping every trace ending with status 500.
If you standardize your telemetry in a Collector before it reaches Refinery, then update your rules to use the new standard fieldname.
If telemetry reaches Refinery with both fieldnames, then its rules can accommodate that.
As of 2.3, Refinery can use multiple fields in a condition, which creates a little de facto coalesce. For instance:
- Name: dynamically sample 200 responses across semantic conventions
Conditions:
- Fields:
- http.status_code
- http.response.status_code
Operator: =
Value: 200
Datatype: int
Note that by pluralizing Field we can now add an array of fields. It takes the first one that’s present and uses it to evaluate.
What to do when field values change
While the current changes in OpenTelemetry don’t include any changes in what values will be contained in the status code, for the purposes of the post, let’s consider the possibility. This does happen when load balancer configuration changes or services start using more HTTP codes.
Sometimes your queries expect a certain limited value set, and new values come in. This post is here to help you in this scenario, too.
Accommodating field values in Honeycomb (recommended)
Let’s say that http.response.status_code used to be 200, 404, or 500, but now it includes 100 and 301. Success used to be defined as 200, but now 100 and 301 are also considered successes.
To filter queries for only successful requests, you can use IN to include all three successful status codes. This filter can be combined with other conditions that must also be true.
WHERE http.response.status_code in 200, 301, 100 http.route contains /checkout
Even better: create a derived column that defines success for your organization’s purposes. That can be referenced in many queries.
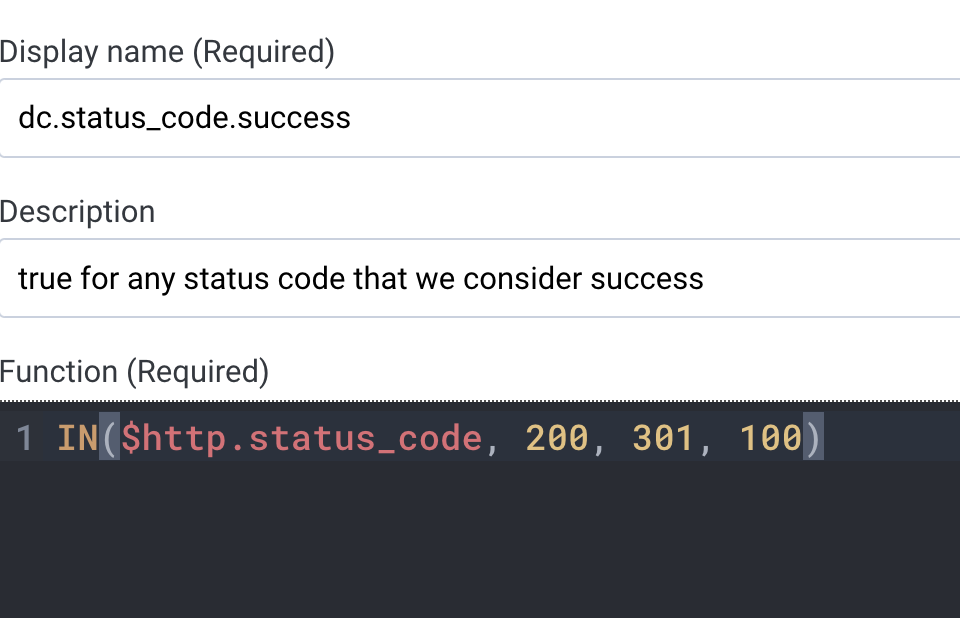
Now you can reference that new derived column in a where or group by clause to get the information you need.
This all works fine in the Honeycomb user interface, but what if your Refinery cluster is making sampling decisions based on these values?
Changing values have consequences for sampling
The new status codes might not match the sampling rules that you have. Perhaps your rules say, “Keep about 10% of requests that return 200, 100% that return 500, and… default to 100% for anything that doesn’t match those rules.” Honeycomb compensates for the dropped requests so that all your metrics come out right anyway. But if values change and your rules aren’t prepared, you might keep more requests than necessary.
If 301 becomes a common return code, you probably mean to consider it a success and keep only 10%. But Refinery will keep 100% of them. Suddenly, you’re saving more traces than you intended to—perhaps you’re sending 1.3 million events to Honeycomb each day, when one million would be just as useful.
Refinery doesn’t have an IN operator and the conditions within a rule are always ANDed together, so you can’t group 200, 301, and 100 into the same rule. If you create many rules, each with the same condition and target sample rate, the Refinery cluster will treat them as separate buckets, each trying to achieve the sample rate. If your intention is to save 10% of successful requests, instead of 10% of 200s, 10% of 301s, and 10% of 100s, then having three separate rules is suboptimal.
What you need here is a single field representing that successful status. If you only had one service sending traces, you could add it to your instrumentation. But when you want consistency across many sources of telemetry, turn to our friend the Collector!
Accommodating field value changes in the Collector (recommended)
When all your telemetry flows through an OpenTelemetry Collector, that is an ideal place to standardize.
Here is a section of Collector configuration:
transform:
error_mode: ignore
trace_statements:
- context: span
statements:
- set(attributes["telemetry.sampling_status"], attributes["http.response.status_code"])
- set(attributes["telemetry.sampling_status"], 200) where attributes["http.response.status_code"] == 200 or attributes["http.response.status_code"] == 100 or attributes["http.response.status_code"] == 301
This transform processor sets the telemetry.sampling_status to the http.response.status_code so it’ll reflect the value if it’s not one we care about. Then, it looks for a 200-like status code and, if found, changes the new field to 200. In Refinery, simply reference that field instead of the http.response.status_code and you’ll get the buckets you need.
This method also gets your new field into Honeycomb in all spans. The Collector is the best place to standardize telemetry.
Complex scenarios involving both changes
If you find yourself in a scenario where you need to account for both a field name change and a field value change, you can do that with the transform processor. Be careful about the order of things: normalize the key first, then do the value adjustment.
This transform processor moves http.status_code into http.response.status_code, then creates the new field telemetry.sampling_status based on multiple possible values of the status code.
transform:
error_mode: ignore
trace_statements:
- context: span
statements:
- set(attributes["http.response.status_code"], attributes["http.status_code"]) where attributes["http.status_code"] != nil and attributes["http.response.status_code"] == nil
- set(attributes["telemetry.sampling_status"], attributes["http.response.status_code"])
- set(attributes["telemetry.sampling_status"], 200) where attributes["http.response.status_code"] == 200 or attributes["http.response.status_code"] == 100 or attributes["http.response.status_code"] == 301
Completing the migration
We don’t necessarily want to keep these things in place forever, especially if it’s a field name change and the old field name isn’t being sent anymore. Honeycomb’s system ages out the underlying data at 60 days. Whenever the last system has been updated to send the new field names, you can set a timer for 60 days and then remove the rule at the end of that time.
In the Data Settings page, on the Schema tab, expand “Unique Fields.” You can look at the schema for each service to see the last time Honeycomb received the old field. If you click Last Data Received twice to sort by it with the oldest fields at the top, you can take this time to clean up other schema changes that have happened over the years.
Click the Hide checkbox on fields that haven’t been received in the last 60 days, and they won’t appear in autocomplete suggestions.
The good news is: if you have links to queries that were run long ago, they’ll still work. The saved results will still have the old field and its corresponding values.
This is the main reason you want to move values from the old name to the new name, instead of moving values from the new name into the old name. If you do that, the age-out won’t happen and you’ll need to keep these transformations in place forever.
Conclusion
As the standards evolve and OpenTelemetry is called on to do more things, these primitive transformations will be commonly relied upon to smooth over the transition periods. It’s important to clean them up and always keep an eye on the future state to avoid creating more technical debt or fragility in the pipeline than is needed.
Getting comfortable with transform processors and derived columns gives you power that helps with more than OpenTelemetry migrations. You can integrate nonstandard telemetry, unify fields across teams, and migrate your own field names as standards evolve. Honeycomb gives you options, and you keep control over your telemetry.
For further reading on the OpenTelemetry Collector, read this piece by Martin Thwaites on securing your Collector.